Simple Copy-Paste is a Strong Data Augmentation Method for Instance Segmentation
Simple Copy-Paste is a Strong Data Augmentation Method for Instance Segmentation (2021)
Instance Segmentation
Computer Vision에서 Data Augmentation 기법은 항상 같이 붙어다닐 수밖에 없는 분야입니다. 모델의 성능이 아무리 좋아지더라도, 그것을 학습시키기 위한 충분한 데이터가 없다면 제대로 성능이 나오지 않기 때문입니다. 요새에는 굉장히 많은 양의 데이터들이 쏟아지고, 이를 수집하면서 기업들은 최대한 양질의 많은 데이터를 얻으려고 노력합니다. 하지만 그럼에도 불구하고 데이터를 얻어내는 것이 어려운 분야들이 있죠. 의료나 혹은 수집 동안 굉장히 오랜 시간이 걸리는 분야들은 그 자체로 수집된 데이터의 양이 적기 때문에 항상 어떻게 데이터의 양을 늘릴지 고민하게 됩니다. 이에 지금까지도 계속해서 발전하고 있는 분야가 바로 Data Augmentation입니다.
이에 관련해서, computer vision 분야 중 image classification의 경우, 상당히 성능 좋은 여러가지 augmentation 기법들이 개발되었습니다. 굉장히 다양한 방식으로 증강시키는 기법들이 있고, 그것들의 성능도 꽤 좋은 편입니다. 그러나, 아직까지 image classificaion과 비슷하지만 다른 몇몇 분야에서는 데이터 자체를 증강시키는 데에 어려움을 겪고 있습니다. 그 중 하나가 바로 ‘Instance Segmentation’입니다.
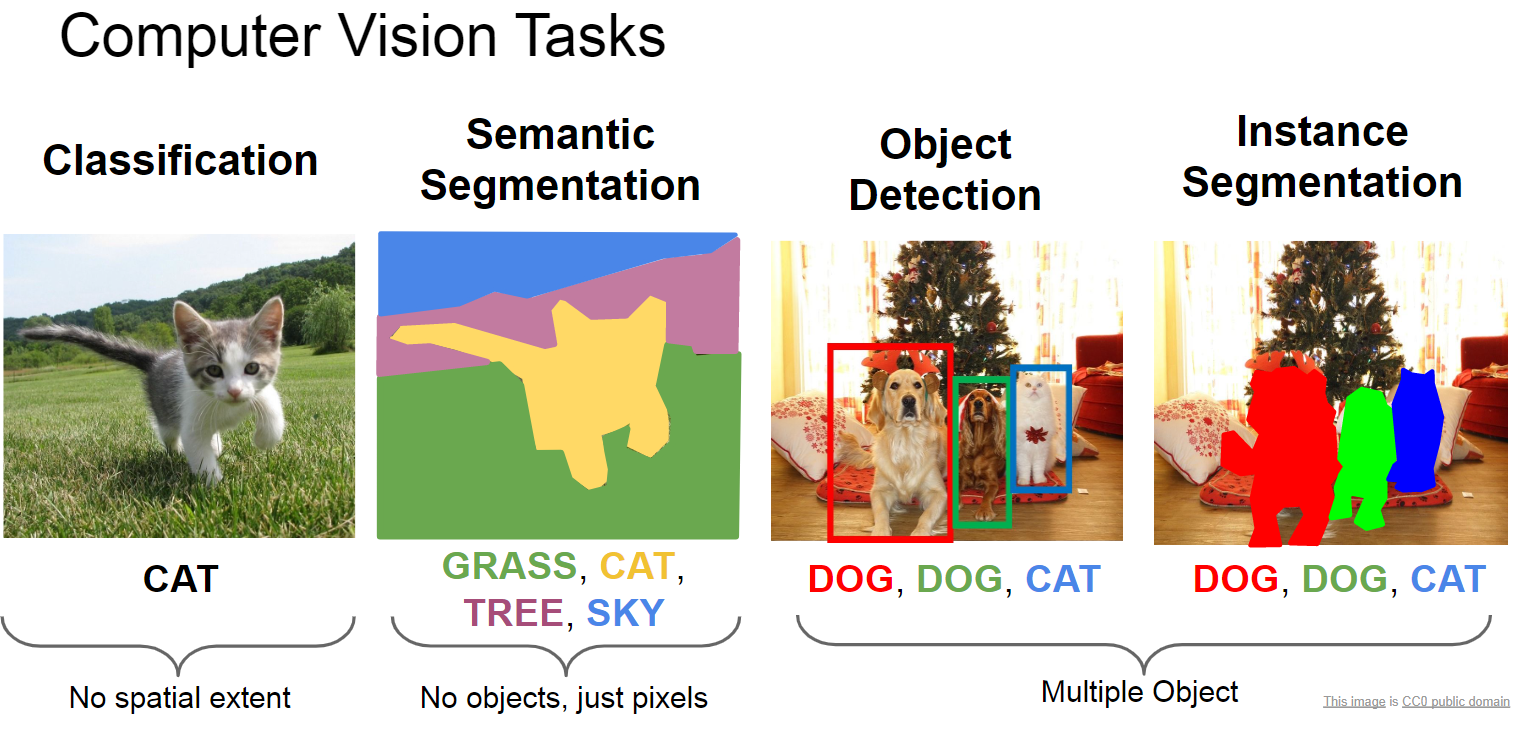
Instacne Segmentation에서의 data augmentation이 어려운 이유는 바로, 이를 위해서는 이미지에서 각각의 object를 수동으로 분류하고, 이에 대한 annotation을 또 다시 해야하기 때문입니다. 이전에 다룬 SaliencyMix의 경우, image classification에서 사용하는 augmentation이었습니다. image classification의 경우, 전체 이미지에서 해당 사진이 어떤 것에 대한 사진인지에 대한 labeling만 해주면 되기 때문에, 이를 매치시키는 것은 수동으로 해도 크게 어렵지 않습니다. 그러나 instance segmentation의 경우, 다음의 두 가지를 수행해야 하기 때문에 훨씬 더 데이터를 만들기가 어렵습니다.
- 주어진 이미지에서 찾고자하는 instance가 어디에 있는지 영역을 정확하게 구분하여 표시하는 것
- 해당 instance가 어떤 label인지 annotation해주는 것
위 두 가지를 수동으로 해주어야 하기 때문에, 더욱 많은 노동력이 필요하게 됩니다. 실제로 image classification의 경우 CIFAR, ImageNet 등등 다양한 benchmark dataset들 뿐만 아니라, kaggle에도 굉장히 다양한 카테고리의 dataset들이 있으나, segmentation 분야의 dataset들은 이러한 한계들로 인해 현재 가장 유명한 데이터 셋인 COCO dataset을 주로 사용하며, 자신이 원하는 특정 분야나 instance에 대한 image dataset은 찾기 어려울 수 있습니다.
이러한 점으로 인해, segmentation을 위한 data augmentation은 굉장히 중요합니다. 기본적인 데이터의 양 자체가 적기 때문에 이를 효과적으로 증강시킬 수 있다면 몇 배의 이득을 보는 것과 마찬가지의 효과가 나기 때문입니다.
그러나 실제로는 segmentation에는 굉장히 좋다고 이야기되는 data augmentation을 찾기가 쉽지 않은 편입니다. 가장 큰 이유로는, image classfication에서 사용하는 data augmentation 기법들을 곧 바로 적용하기가 어렵다는 점 때문입니다. 이에 두 가지 이상의 이미지를 mixing하는 최신 image classfication augmentation 기법들을 곧 바로 instance segmentation에 적용하기 어렵습니다.
그러나 두 개 이상의 이미지를 mixing하는 기법이 굉장히 효과적이라는 것이 밝혀진 상황에서, 다른 computer vision task들에서도 이를 사용하지 않기는 어렵습니다.
두 개의 이미지를 instance segmentation에서 mixing하려는 시도 중 하나가, 바로 오늘 소개할 ‘Simple Copy-Paste is a Strong Data Augmentation Method for Instance Segmentation’입니다.
Simple Copy-Paste is a Strong Data Augmentation Method for Instance Segmentation (2021)
위 논문은 정말 제목에서 나와있는 것처럼, 두 개의 instance segmentation을 위한 이미지를 단순 복사 & 붙여넣기를 통해 구현합니다. 어떻게 보면 정말로 간단한 아이디어지만, 2021 CVPR에 발표가 된 최신 논문입니다. 해당 논문은 instance segmentation에서 당시 SOTA를 달성하게 만드는 주요 역할을 했습니다.
그렇다면 실제 이 논문은 어떤 식으로 이를 구현하는지 설명하도록 하겠습니다.
Copy-Paste Augmentation
기본적으로 이전에도 사용되던 Copy-Paste Augmentation 기법은 세 가지 단계로 구성됩니다.
- 주어진 train dataset에서 random한 두 개의 이미지를 선택하여 하나를 source로, 하나를 target으로 선택
- source image에서 복사할 object instance 선택
- source object를 target image의 어떤 위치에 붙여넣을 것인지 선택
이에 각각의 단계에서, 어떤 방식으로 해당 과정을 개선할 것인지를 따라서 여러가지 연구가 되었습니다.
즉, copy-paste augmentation은 label들로 annotation이 되어있는 instance segmentation train data 두 개를 임의로 선택하여 augmentation을 진행합니다. 이미지를 추출하기 위한 source image를 선택하고, 이를 붙여넣기 위한 target image를 하나 선택합니다. 그리고 그것을 옮겨 넣음으로서 두 개의 이미지가 합성된 것으로 만들어내게 됩니다.
image classification에서 사용되던 mix 기법들은 모두 특정 bounding box 영역을 통째로 들고와서 target image에 붙여넣는 방식으로 진행되었습니다(cutmix 등). 그러나 해당 논문은 이를 bounding box를 이용하여 구현하지 않고, train data에 나와있는 source image의 object instance 자체를 그대로 복사해서 target image로 이동시킵니다.
기존에 선행되었던 Copy-paste augmentaiton 논문의 경우, target 이미지의 surrounding visual context를 모델링하여, 이를 통해 해당하는 source object가 visual context를 최대한 해치지 않는 위치에 object를 배치하는 방식으로 구현이 되었습니다.
그러나 본 논문은 이러한 노력을 통해 위치를 선택하는 것보다, 그냥 target image의 랜덤한 위치에다가 source object를 삽입하는 것으로도 다양한 기준들을 고려하였을 때 훨씬 더 나은 성능을 보인다는 것을 발견합니다. 이는 단순히 정확도가 향상된다는 것 뿐만 아니라, backbone architecture의 variability, scale jittering의 범위 증가, training scheduling, image size 등등 여러 요소에서 훨씬 더 나은 결과를 보인다고 합니다.
Method - Base
기본적인 1과 2의 방법은 원래의 copy-paste augementation과 동일합니다. 그러나 source object를 선택한 이후의 처리 및, target image에 옮겨넣는 과정에서 본 논문과 기존의 방법은 차이가 생깁니다.
source object를 선택할 경우, 다른 train data가 이용될 가능성이 있습니다. 이 때, 기존에 존재하는 source image에는 해당 source object가 그대로 존재하기 때문에, 이를 원본과 다르게 만들어주기 위해 source object에 ‘random scale jittering’과 ‘flipping’을 추가합니다. 즉, 해당 object 자체에도 data augmentation을 적용하는 것으로 원본과 차이를 두게 만듭니다. 이렇게 만들어진 source object를 target image의 랜덤한 위치에 설정하여, 그 위치에다가 옮겨 붙이게 됩니다.
그러나 이 과정에서 source object가 target image에 존재하는 instance 영역을 침범할 수 있습니다. 이 때, 해당 논문에서는 우리가 새롭게 붙여넣는 object 자체를 아예 가장 앞에 놓여있는 것으로 간주합니다(즉, 덮어씌웁니다). 이를 통해, 원래 존재하는 target image instance의 ground truth를 source object에 의해 침범된 영역만큼 수정을 시켜줍니다. 이렇게 해서 새롭게 만들어진 이미지에서 각각의 instance들이 차지하고 있는 영역과 각 영역의 annotation들을 조정하여 주면 됩니다.
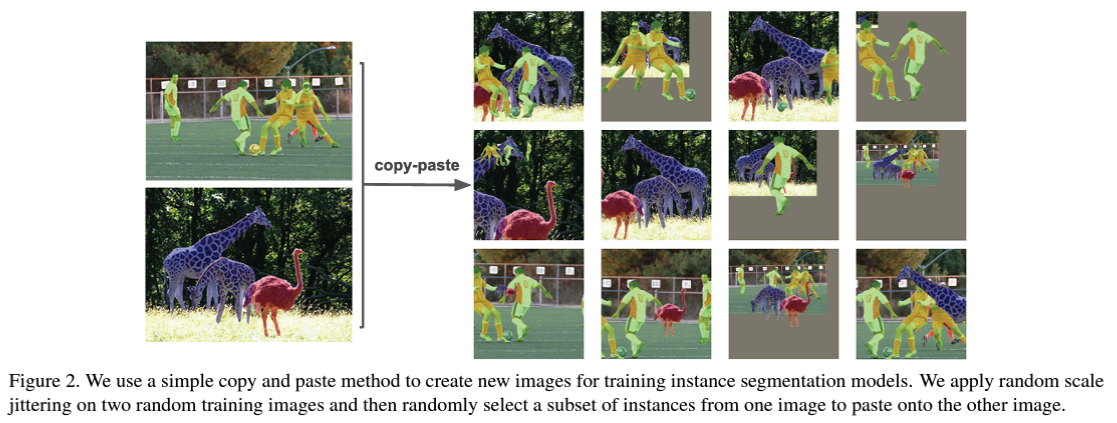
Blending Pasted Objects
이 때, 새로운 object를 붙여 넣는 과정에서, 해당 object의 binary mask를 α라고 할 때, ground-truth annotation은 다음과 같은 식으로 계산됩니다.
Large Scale Jittering
앞서 언급한 것처럼, 이미지에 scale jittering을 적용시켜셔 크기를 임의로 조정하고 잘라내는 과정을 적용합니다. 본 논문에서는 standard scale과 large scale을 둘 다 적용하여 이 둘 중 어떤 것이 더 나은지 확인합니다.

그러나 대부분의 경우에서는, 주어진 이미지에 scale jittering을 적용할 때에는 standard보다 large scale jittering을 적용하는 것이 더 나아서 본 논문에서는 앞으로 large scale jittering을 사용합니다.
Self-training Copy-Paste
앞서 이야기한 것들은 기본적으로 training data에 instance segmentation이 이미 적용되어, 각각의 object에 대한 annotation과 이들에 대한 ground-truth가 계산되어 있는 것을 가져가 사용했습니다. 그러나 본 논문에서는 이러한 supervised data뿐만 아니라, unlabeled image들에 대해 self-training을 진행하는 실험도 함께 진행합니다.
위 실험은 다음 3가지 단계를 통해 진행됩니다.
- label이 지정된 data에 대한 copy-paste augmentation을 사용하여 supervised model 학습
- label이 지정되지 않은 pseudo label data 생성
- 실제 ground-truth instance를 pseudo label 및 supervised labeled image에 각각 붙여넣어 새로운 데이터를 만들어 내고, 이를 사용하여 새롭게 model을 학습
Experiments
experiments로 저자들은 다양한 종류의 강점이 있다는 것을 확인했습니다. 이 중 중요한 몇 가지를 살펴보도록 하겠습니다.
Settings
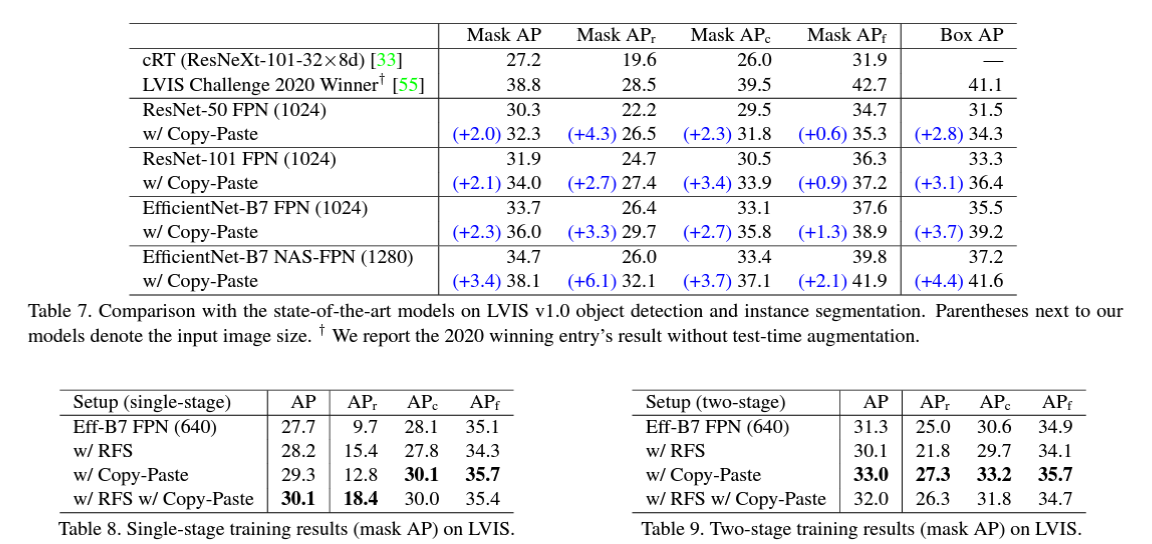
자세한 세팅에 대한 내용을 논문에서 확인할 수 있습니다. 기본적으로는 instance segmentation을 진행하기 위한 Mask R-CNN을 efficientNet과 ResNet을 backbone architecture로 사용하였습니다. 또한 이외에도 Cascade R-CNN을 사용하는 과정에서 efficientnet B-7을 backbone으로, NAS-FPN을 feature pyramid로 사용하여 가장 강력한 모델을 만들어 성능을 테스트했습니다. 이외에 여러가지 hyper-parameter를 조정하여 실험을 진행합니다.
실험은 118k 개의 train data를 가지고 있는 COCO Dataset을 사용하고, 전이학습을 위해 COCO dataset으로 pre-train한 이후 PASCAL VOC dataset에서 fine-tuning을 거칩니다.
Copy-Paste is robust to training configurations
Simple copy-paste 기법은 training configuration에 굉장히 robust하다는 것을 실험을 통해 확인합니다. 이는 다음과 같은 사항들에 robust 합니다.
- backbone initialization
Mask R-CNN은 보통 ImageNet으로 사전훈련된 모델로 backbone을 initialize하는 것입니다. 그러나 simple copy-paste을 다른 strong augmentation과 함께 사용하게 될 경우, 오히려 imagenet으로 사전훈련된 모델은 임의의 랜덤 initialize를 한 backbone을 사용하는 것보다 성능이 최대 1AP까지 줄어든다는 것을 확인할 수 있습니다.
- training schedules
보통의 Mask R-CNN을 사용하는 object detection model들은 많은 수의 epochs까지 훈련을 하면 오히려 성능이 저하된다는 문제점이 있어, 최대 46 AP 정도까지만 훈련하는 것이 일반적입니다. 그러나 Simple Copy-Paste 기법을 사용할 경우, 일반적인 train epochs보다도 더 많은 epochs가 증가할수록 성능이 향상되어 더 많은 train을 통해 성능을 향상시킬 수 있습니다.
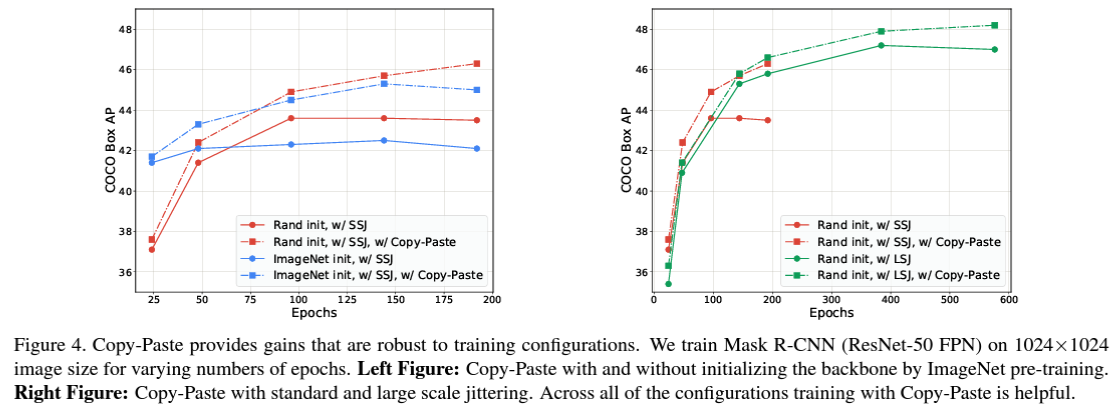
- additive to large scale jittering augmentation
앞서 이야기한 것처럼, large scale jittering에 더욱 좋은 성능을 보이고, 이와 함께 더 많은 수의 train epochs를 갖는 것으로 성능을 향상시킬 수 있습니다.
- works across backbone architectures & image size
Simple Copy-Paste의 경우, ResNet뿐만 아니라 EfficientNet 등 최신 architecture들도 backbone으로 사용할 수 있다는 장점이 있습니다. 즉, 이들 모델이 사용하는 서로 다른 image size에서도 모델을 학습시킬 수 있으며, 이러한 모델들에 모두 평균 0.8~1.3 box AP의 성능 향상을 보입니다.
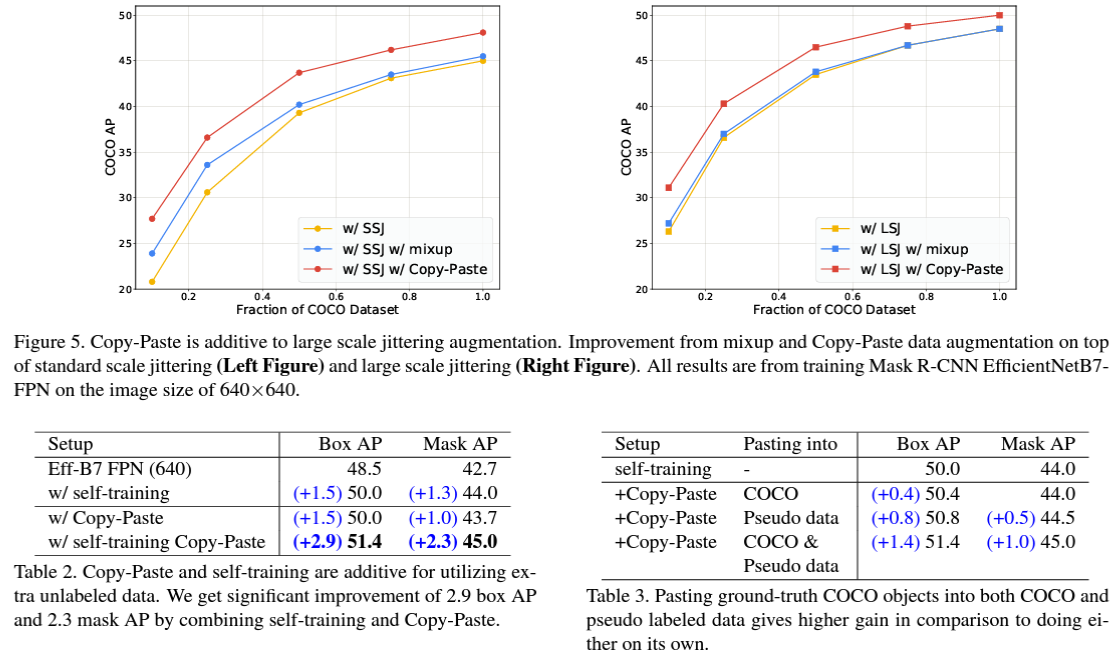
이외에도 다양한 experiments를 통한 simple copy-paste augmentation의 장점을 논문에서 확인 가능합니다.
Conclusion
결과적으로 simple copy-paste augmentation은 다른 augmentation과의 호환성도 굉장히 높으며, 다양한 종류의 backbone architecture에도 사용 가능하며, train scheduling에서도 강점을 보이는 등 다양한 장점들을 가지고 있습니다.
뿐만 아니라 instance segmentation을 single-stage를 사용해도, two-stage를 사용해도 항상 Copy-Paste를 같이 사용하는 것이 훨씬 더 좋은 결과를 내게 됩니다.
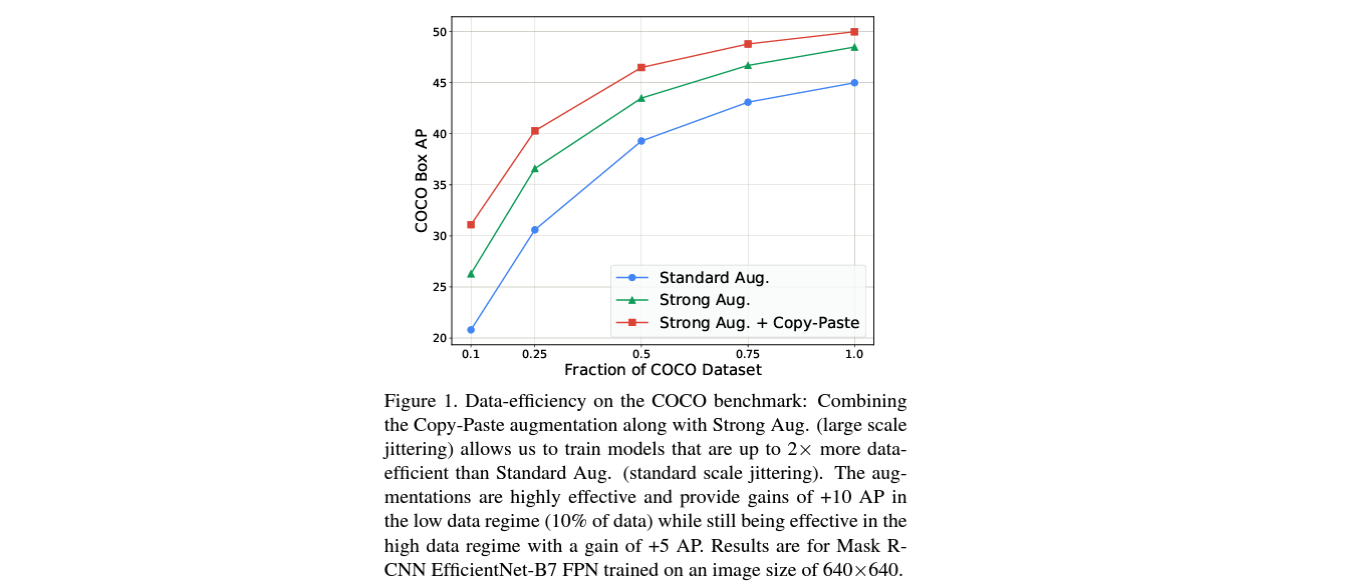
위 그래프에서 확인할 수 있듯, 기본적인 Copy-Paste Augmentation은 다른 augmentation과 함께 적용되었을 때, COCO dataset에서 굉장한 성능 향상을 보였습니다. 일반적으로 사용되는 standard scale jittering보다 data efficiency가 2배 향상되었으며, 훈련 데이터의 10%만 사용할 때 낮은 데이터 영역에서 10 box AP에 해당하는 향상이 있다는 것을 확인할 수 있습니다.
이러한 Data augmentation 전략은 computer vision 분야에서, 특히 instance segmentation에서 굉장히 중요합니다. 특히 본 논문에서 살펴본 Copy-Paste 전략은 굉장히 간단하면서 거의 모든 케이스에 대해 성능을 향상시키고, 굉장히 다양한 종류의 code base에 적용할 수 있으며 여러 종류의 data augmentation과 호환되며 backbone architecture들과도 호환됩니다.
이 논문에서 copy-paste 전략을 다양한 방식으로 살펴본 결과를 통해서, instance segmentation을 진행할 일이 있다면, copy-paste 전략을 자신이 구상한 모델에 어떻게 적용할 것인지 생각해보는 것도 좋을 것입니다.