Vision Transformer (1)
들어가며
현재 컴퓨터 비전에서 가장 뜨거운 주제 중 하나는 vision transformer (ViT) 이다. 2017년에 발표되었지만 벌써 4만 번 가까이 인용된 [
Language Model
Transformer가 발표되기 이전 자연어처리를 위한 language model은 주로 LSTM [1], GRU [2]과 같은 recurent neural networks (RNNs) 나 Encoder-decoder 구조를 가졌다. 예를 들어 “ABCD”로 이루어진 문장을 “XYZ”로 번역하는 machine translation 모델의 경우, A, B, C, D 각 단어를 LSTM의 각 cell의 입력으로 넣어주고, X, Y, Z 각 번역된 단어를 각 cell의 출력으로 얻는 것이다. (그림 1)
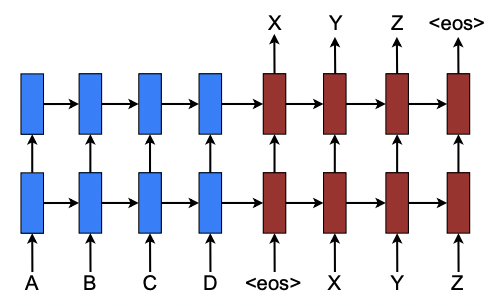
그림 1. Neural machine translation. <eos>는 문장의 끝을 의미한다. [3]
사과, apple, リンゴ는 모두 다른 모양새지만 의미는 같다. 결국 사과, apple, リンゴ라는 단어는 “사과”라는 의미를 표현하는 방식이 다른 것뿐이다. 표현(representation)을 의미(latent vector)로 바꾸는 것을 encoding, 의미를 표현으로 바꾸는 것을 decoding이라 하고, 표현을 의미로 바꾸어 다시 다른 방식의 표현으로 바꾸는 모델을 encoder-decoder 모델이라고 한다. Machine translation에서 서로 다른 표현이란 서로 다른 언어를 뜻하지만, encoder-decoder 구조는 그외에도 다양한 딥러닝 태스크에서 사용될 수 있다. 이미지와 segmentation도 결국은 한 scene의 서로 다른 표현 방식이다. (그림 2) 이미지와 caption도 마찬가지다. [4]
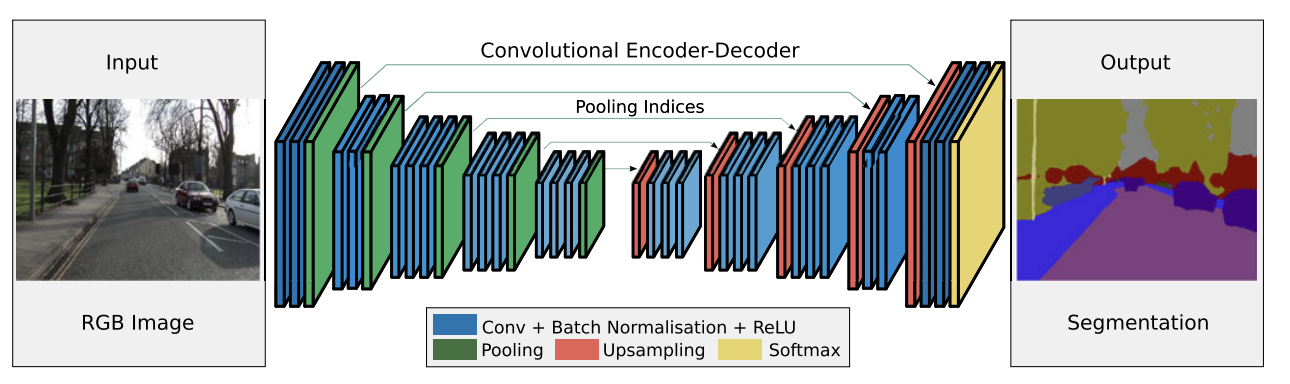
그림 2. SegNet [5]
Self-attention
문장의 어떠한 한 단어를 이해하려면, 그 문장의 다른 단어를 보아야한다. 예를 들어 “The Law will never be perfect, but its application should be just.” 라는 문장을 이해하려면 ‘its’가 가리키는 것은 ‘The Law’이라는 것을 알아야 한다. 그러나 ‘its’를 이해하는 데 ‘perfect’나 ‘but’이 차지하는 역할은 ‘The Law’보다 작을 것이다. 이처럼 한 단어를 이해하기 위해 문장의 다른 단어들이 필요한 것은 맞지만, 그 단어들이 모두 동등한 중요도로 필요한 것은 아니다. 그래서 문장 내에서 단어들 간의 inter-dependency를 효과적으로 mapping하기 위해 도입된 것이 self-attention이다. 간단히 말하자면 한 단어를 이해할때 문장을 구성하는 다른 단어들의 가중합으로 계산한 context를 함께 제공하는 것이 self-attention이다.
Attention is All You Need
Transformer은 RNN이나 convolution layer 없이 온전히 self-attention에 의존하는 encoder-decoder 모델이다. Transformer은 attention을 query와 key-value의 pair이 있을 때 서로 대응되는 query와 key에 따라서 결정되는 가중치를 통해 계산한 value의 가중합으로 정의한다. 그리고 이러한 attention을 scaled dot-product attention이라 명명했다. $Q, K, V$는 각각 query, key, value를 의미하고, $W_Q, W_K, W_V, W_0$는 각각 query, kev, value를 projection하는 parameter matrices를 의미할때 scaled dot-product attention의 수식은 아래와 같다.
$\text{A}(Q, K, V) = \text{softmax}\bigg(\dfrac{Q W_Q W_K^T K^T}{\sqrt{L}}\bigg) V W_V W_0$
Multi-head attention은 이러한 scaled dot-product attention을 stack한 구조로, 서로 다른 parameter matrices를 통해 입력된 정보를 서로 다른 관점에서 attention할 수 있다. 이때 각각의 scaled dot-product attention를 head라 한다.
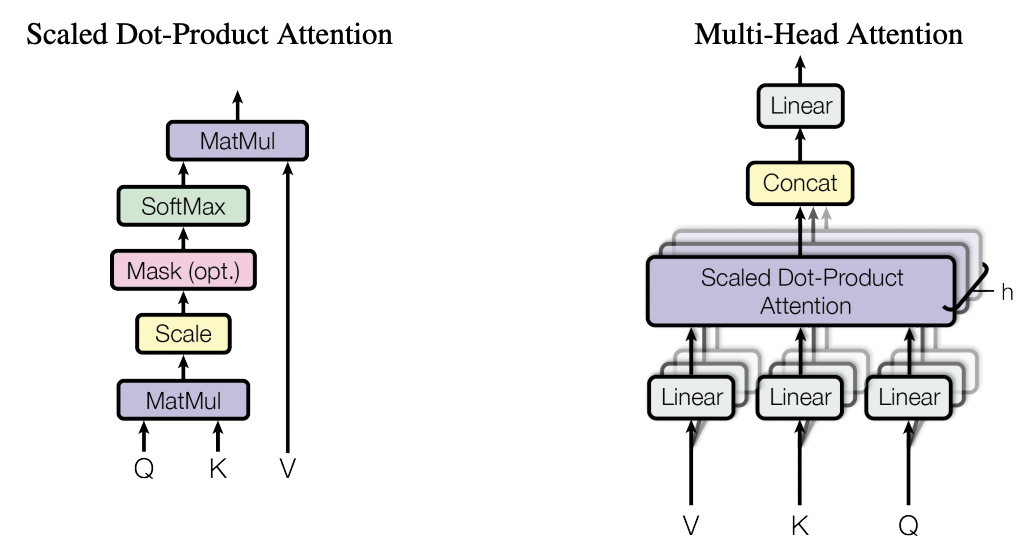
그림 3. (좌) Scaled Dot-Product Attention (우) Multi-head Attention
다시 “The Law will never be perfect, but its application should be just.”로 돌아가서, 이 문장을 multi-head attention에 입력했을 때의 attention 가중치를 시각화한 결과를 보자. 서로 다른 색은 서로 다른 head를 의미한다. 첫 번째 attention head는 ‘its’를 이해하는데 가장 중요한 ‘Law’를 매우 높은 가중치로 전달하고 있고, 두 번째 attention head는 ‘its’와 관련이 있는 ‘Law’, ‘application’을 높은 가중치로 전달하고 있는 것을 확인할 수 있다.
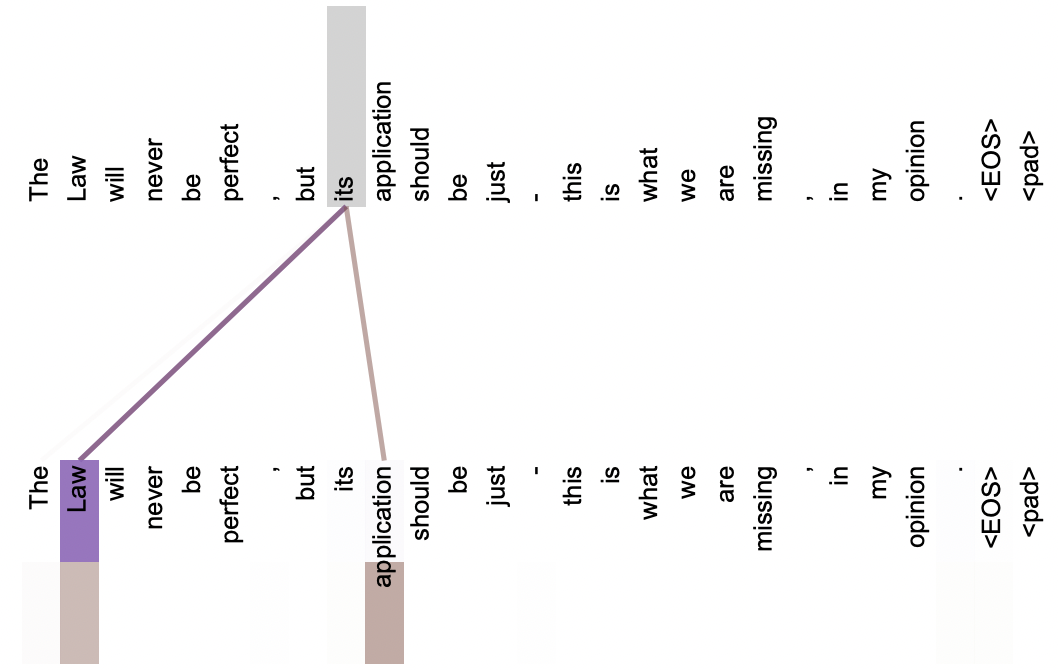
그림 4. 두 개의 attention head로 이루어진 multi-head attention.
Transformer의 전체 구조는 아래와 같다. Embedding layer을 통과한 input과 output은 반복되는 별개의 모듈을 통과하는데, decoder의 두 번째 multi-head attention은 encoder의 output을 value와 key로 사용한다.
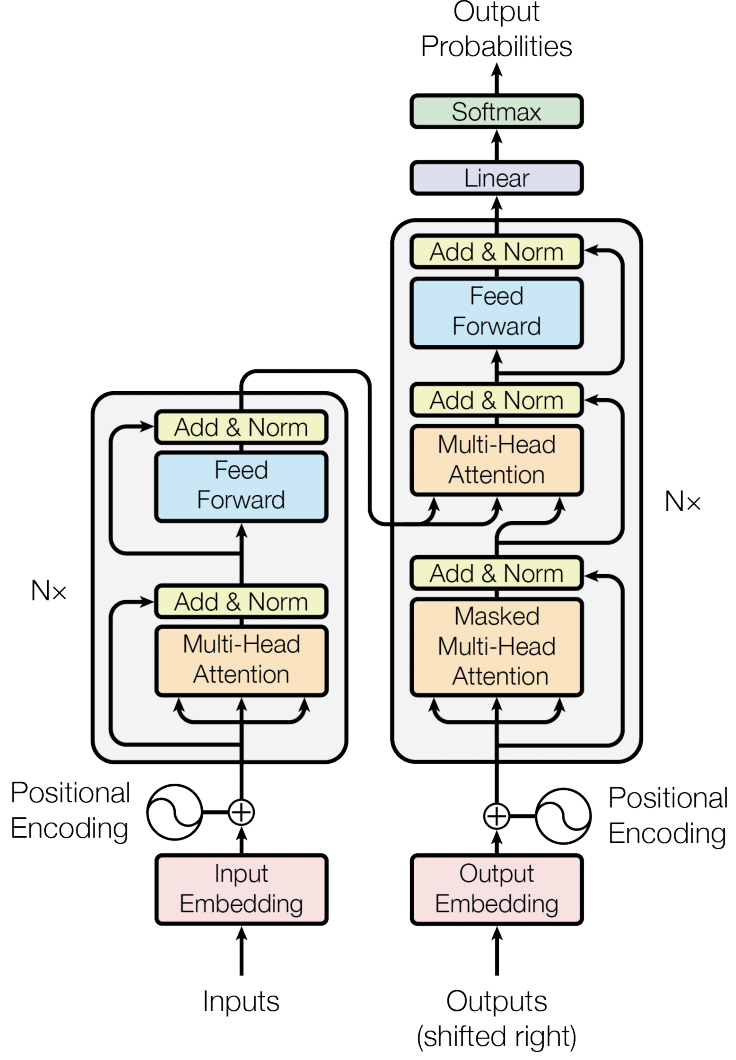
그림 5. Transformer model architecture
Why Self-Attention?
Self-attention은 기존에 사용되던 recurrent layer나 convolutional layer에 비해 낮은 computational complexity를 가진다. 또 recurrent한 구조를 취하지 않으므로 계산을 병렬처리할 수 있어 방대한 양의 데이터를 사용하는 language model에 적합하다.

그림 6. Computational complexity 비교. n은 문장의 길이를, k는 convolutional layer의 kernel 크기를, d는 embedding의 차원을 의미한다.
또 self-attention는 문장의 모든 단어에 대해 가중합을 계산하므로 가까이 있는 단어뿐만 아니라 멀리 있는 단어와의 dependency를 계산할 수 있다. 예를 들어 “It is in this spirit that a majority of American governments have passed new laws since 2009 making the registration or voting process more difficult.”라는 문장에서 ‘making’을 이해하기 위해 convolutional layer의 filter처럼 앞 뒤 3단어만 본다면 “more difficut”와의 dependency를 계산하지 못해 “making A more difficult”라는 중요한 구문 패턴을 발견하지 못할 것이다.
마치며
Transformer을 기반으로 한 모델들은 현재 자연어처리의 다양한 태스크에서 기록을 갈아치우며 선전하고 있다. 그러나 transformer 역시 큰 데이터셋을 필요로 하고 학습에 긴 시간이 필요한 등의 단점이 있다. 그런만큼 소규모 연구실이나 개인이 transformer을 학습하기 어려워 대기업에서 발표한 pretrained model을 사용하는 경우가 많다. 이렇게 대기업이 주도하는 연구 문화에 대항해 쉽게 transformer을 사용할 수 있는 시스템을 제공하는 단체도 존재한다.

그림 7. Hugging Face
Self-attention으로만 이루어진 새로운 encoder-decoder 구조를 제안한 transformer은 높은 성능을 달성했을뿐만 아니라 수많은 연구 주제들을 창출하고 연구 문화를 바꾼 인상적인 연구이다.
Reference
[2] Empirical evaluation of gated recurrent neural networks on sequence modeling
[3] Effective Approaches to Attention-based Neural Machine Translation
[4] Deep Hierarchical Encoder–Decoder Network for Image Captioning
[5] SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation