visualizing data
Visualizing data
Contents
- 탐색적 자료 분석
- Data to Image
- 다양한 툴과 차트
- 마치며
- 참고자료
탐색적 자료 분석
“the greatest value of picture is when it forces us to notice what we never expected to see”
위는 ‘존 튜키’ 라는 통계학자의 발언으로, 그림의 가장 위대한 가치는 우리가 예상하지 못한 것을 알려줄 때 라고 말하고 있습니다.
탐색적 자료 분석 (Exploratory Data Analysis) 는 ‘존 튜키’ 라는 통계학자가 창안한 자료 분석 방법으로, 시각적 방법으로 주요 특성들을 알아내기 위해, 데이터를 분석하는 접근 방식을 말합니다. EDA 는 중요한 과정으로서, 데이터 연구의 초기 단계에서 이루어지게 되며, 어떤 확증적인 모델 보다는 직관성을 이용해 패턴을 분석하고, 가설을 테스트하며, 요약하는 등, 데이터의 실질적인 분석을 진행하기 이전에, 초기 조사를 수행하는 중요한 과정이라고 이해할 수 있습니다.
EDA 를 통해 우리는 데이터에 어떤 변수가 존재하는지, 데이터에 특별한 문제점(이상치, 결측값)은 없는지, 각 속성(attribute) 간 특별한 관계가 존재하는지, 또는 그 범위나 분포가 어떻게 이루어져 있는지 등 을 알아낼 수 있습니다.
EDA 에서는 데이터 시각화 기법들이 다양하게 사용됩니다. 그 예로, 도표나 그래프, 또는 통계적 변수들이 사용됩니다. 가장 근본적으로 이상치를 찾아내는 box plot 또는 사분위 수 같은 요약통계들이 이에 해당된다고 볼 수 있습니다. 이처럼 데이터를 주의깊게 살펴보는 과정은 매우 중요한 것을 알 수 있습니다. 다음은 그 이유를 가장 중요한 4가지를 간단히 나열해 보았습니다.
- 수집 / 처리 과정에서의 실수(오류, 누락)를 식별
- 통계적인 가정에 오류가 없는지 확인 (분포의 정규성, 등분산)
- 데이터 패턴을 분석
- 가설을 생성
이렇게 EDA를 진행한다면 우리는, 일반적인 통계적인 정보에서는 찾아낼 수 없었던, 직관적인 정보들을 이용해 더욱 효율적이고 의미있는 모델을 만들어 줄 수 있고, 이를 이용해 예측을 진행하던지, 가설을 검정하는 데 이용을 하던지 등 유용하게 사용할 수 있는 정보들을 얻어낼 수 있는 것이다.
Data to Image
데이터를 이미지로 변환하는 과정입니다. 이미지로는 여러가지를 사용할 수 있습니다.
가장 기본적으로 Position(위치)이 있습니다. 속성에 따라 위치를 다르게 데이터를 둔다던지, 그 scale 에 따라 위치를 다르게 표기한다던지 등 position은 사람이 보았을 때, 가장 효율적으로 데이터를 이해할 수 있는 기준이 됩니다.
두 번째로는 Length(길이)가 있습니다. Position과 마찬가지로 length는 매우 직관적으로 데이터를 표현할 수 있습니다. 양이 많고 적음을 길이로 표현하거나, 크고 작음을 길이로 표현할 수 있으며, 위치와 마찬가지로 효율적으로 데이터를 표현하는 방법이 됩니다.
세 번째로는 Slope(기울기) 나 Angle(각) 이 있습니다. 데이터간의 상관관계를 표시할 때, 기울기는 유용하게 사용되며, 각 또한 마찬가지 개념이며, 원 이미지에서 사용될 경우, length 와 비슷한 의미를 가질 수 있습니다.
이 외에도, Area(면적) 정보, Intensity(강도) 등이 사용됩니다. 강도의 경우 색의 명도등을 이용할 수 있으며, 이와 마찬가지로 여러가지 색과, 모양들이 사용될 수 있습니다.
데이터를 이미지로 변환하는 과정에서는, 이런 여러가지의 요소들을 적절이 잘 혼합함으로서, 효율적으로 데이터 분석과 해석이 가능하도록 하는 것이 최우선과제라고 할 수 있습니다.
다양한 툴과 차트
이전 포스트에서 우리나라의 COVID19 사태의 실황을 데이터로 받아오는 웹 크롤링을 진행했습니다. 그 글을 참조해 가져온 데이터를 이용해서 여러가지 툴을 사용하여 시각화해보도록 하겠습니다.
한글 데이터를 matplotlib 를 이용해 보여줄 경우 기본 setting으로는 글자가 깨지는 현상이 존재합니다. 따라서, 아래와 같은 코드를 사용해서, font를 바꿔주는 것이 중요합니다.
import matplotlib as mpl
import matplotlib.font_manager as fm
font_list = fm.findSystemFonts(fontpaths = None, fontext = 'ttf')
font_list[:]
mpl.rc('font', family='NanumBarunGothic')
print(plt.rcParams['font.family'])
mpl.font_manager._rebuild()
먼저 findsystemfonts를 이용해서, 저장되어 있는 폰트를 확인하고, matplotlib.rc를 이용해서 기본 font를 지정해주면 된다. pyplot.rcParams를 출력해서 제대로 설정이 되었나 확인할 수 있고, 꼭 matplotlib.font_manager. _rebuild() 를 실행시켜주어야 적용된다.
이제 앞서서 covid 데이터를 가져와야 합니다. web crawling 편에서 다루었던 코드를 그대로 가져왔습니다.
import sys
sys.version
import pandas as pd
import requests
from bs4 import BeautifulSoup
url = 'http://ncov.mohw.go.kr/bdBoardList_Real.do?brdId=1&brdGubun=13&ncvContSeq=&contSeq=&board_id=&gubun='
req = requests.get(url)
html = req.text
soup = BeautifulSoup(html, 'html.parser')
tables = soup.find_all('table',{'class':'num midsize'})
head = tables[0].find('thead')
body = tables[0].find('tbody')
columns = head.select('tr')[1].select('th')
columnlist=[]
for column in columns:
columnlist.append(column.text.split(' ')[0])
columnlist
rows = body.select('tr')
rowlist=[]
datalist=[]
datas=[]
for row in rows:
rowlist.append(row.select('th')[0].text)
datas = row.select('td')
for data in datas:
datalist.append(data.text)
def divide_list(l, n):
for i in range(0, len(l), n):
yield l[i:i + n]
n = 8
result = list(divide_list(datalist, n))
my_dict = {}
i = -1
def erasecomma(s):
if s == None:
return 0
elif s != None:
return s.replace(',', '').strip()
for res in result:
i = i + 1
for j in range(0,8):
res[j] = erasecomma(res[j])
my_dict.update({rowlist[i]:{columnlist[0]:res[0],
columnlist[1]:res[1],
columnlist[2]:res[2],
columnlist[3]:res[3],
columnlist[4]:res[4],
columnlist[5]:res[5],
columnlist[6]:res[6],
columnlist[7]:res[7]}})
df = pd.DataFrame.from_dict(my_dict, orient='index')
df.set_value(df['발생률'] == '-','발생률',0)
display(df)
for column in columnlist:
df[column] = pd.to_numeric(df[column])
df.sort_values(by='확진환자',axis=0,ascending=False)
df['사망률'] = df['사망자']/df['확진환자']
df.sort_values(by='사망률',axis=0,ascending=False)
만들어진 covid 최신 데이터를 이용해 데이터 시각화를 진행해보자.
제일 먼저 진행할 것은 바로 bar plot 입니다.
df = df.sort_values(by=['확진환자'],axis = 0)
plt.figure(figsize=(10, 8), dpi= 80, facecolor='w', edgecolor='k')
if True:
df = df.drop(['합계'])
x = []
for i in df.index:
x.append(i)
plt.bar(x,df['확진환자'])
plt.title("확진환자")
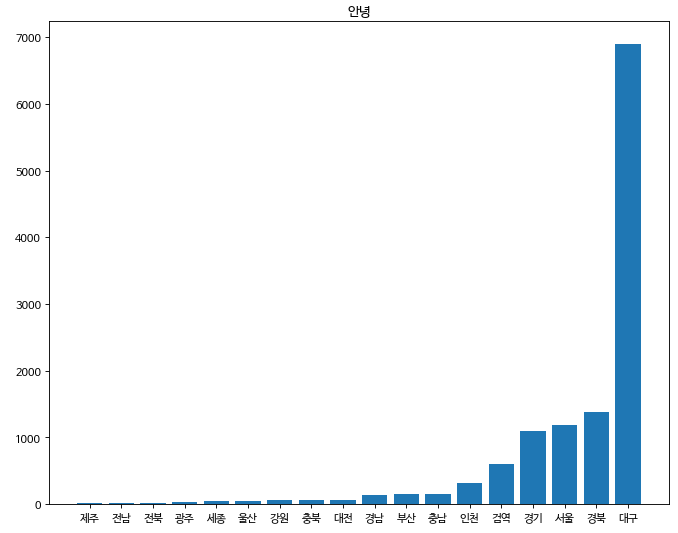
가장 기본적인 bar 그래프다. bar그래프는 바의 길이를 이용해서 데이터의 크고 작음을 아주 효율적으로 알아 낼 수 있는 plot이다. sort_values를 이용해서 정렬 후에 bar 그래프를 출력하면 더욱 직관적인 이미지를 뽑아낼 수 있다. 이 외에도 bar를 이용해 여러가지 종류의 plot을 그려낼 수 있다.
bar_width = 0.35
alpha = 0.5
index = np.arange(18)
plt.figure(figsize=(10, 8), dpi= 80, facecolor='w', edgecolor='k')
p1 = plt.bar(x, df['확진환자'], bar_width, color='b', alpha=alpha, label = '확진환자')
p2 = plt.bar(index+bar_width, df['격리해제'], bar_width, color='r', alpha=alpha, label = '격리해제')
plt.legend((p1[0], p2[0]), ('확진환자', '격리해제'), fontsize=15)
#plt.yscale("log")
plt.show()
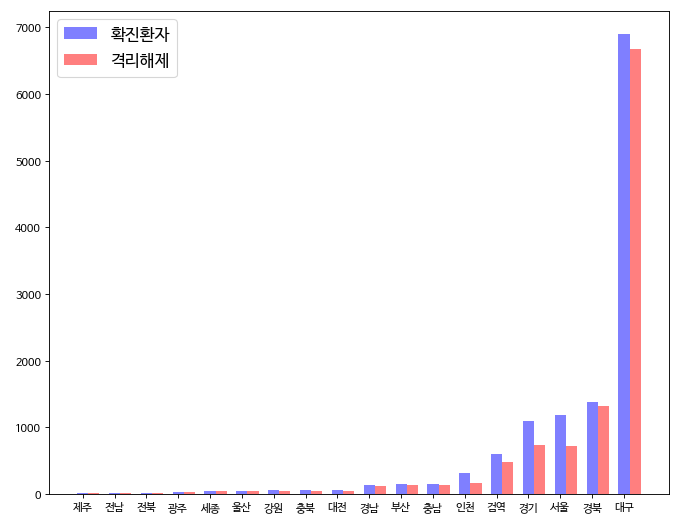
위와 같이 하나의 요소에 대해 2개 이상의 feature를 비교하고 싶을 때는 여러개의 plt.bar를 만들어주면된다. plt.bar 의 첫 번째 attribute인 x 의 경우에 실질적인 xlabel 을 의미함과 동시에, 그 위치의 스칼라값도 지정이 되므로, index 라는 리스트에 0~18값을 넣은 후, +bar_width 를 해주면 바로 옆에 바가 추가되는 것을 확인할 수 있다.
bar_width = 0.35
alpha = 0.5
index = np.arange(18)
plt.figure(figsize=(10, 8), dpi= 80, facecolor='w', edgecolor='k')
p1 = plt.bar(x, df['확진환자'], bar_width, color='b', alpha=alpha, label = '확진')
p2 = plt.bar(x, df['사망자'], bar_width, color='r', alpha=alpha, label = '사망', bottom = df['확진환자'])
plt.legend((p1[0], p2[0]), ('확진', '사망'), fontsize=15)
#plt.yscale("log")
plt.show()
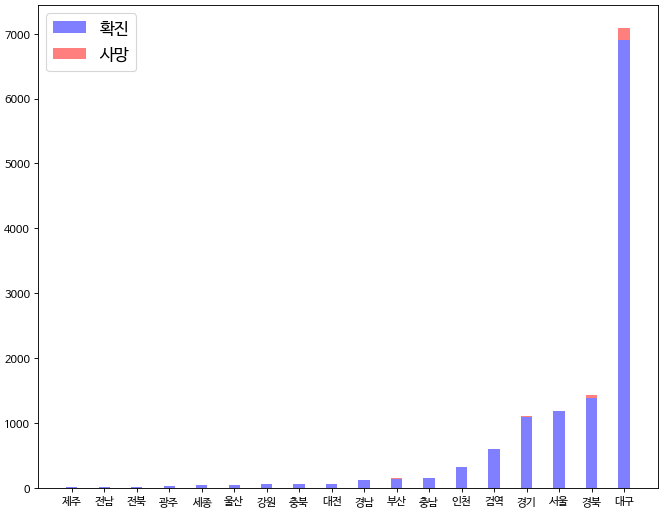
위처럼 바 위에다가 추가적인 속성을 붙여서 표현할 수 도 있다. 상대적인 길이나 비율을 볼 때 용이하며, plt.bar에 있는 ‘bottom’ 이라는 속성을 이용해서 구현 가능합니다.
이번에는 folium 이라는 패키지를 이용해서 지도상에 확진환자 상태를 표시하는 방법을 설명해보겠습니다.
import folium
df['lat'] = 0.0
df['lon'] = 0.0
df.loc['제주','lat'] = 33.507
df.loc['제주','lon'] = 126.525
df.loc['전남','lat'] = 34.694
df.loc['전남','lon'] = 126.976
df.loc['전북','lat'] = 35.774
df.loc['전북','lon'] = 127.099
df.loc['광주','lat'] = 35.128
df.loc['광주','lon'] = 126.850
df.loc['세종','lat'] = 36.551
df.loc['세종','lon'] = 127.303
df.loc['울산','lat'] = 35.516
df.loc['울산','lon'] = 129.322
df.loc['강원','lat'] = 38.079
df.loc['강원','lon'] = 128.284
df.loc['충북','lat'] = 36.756
df.loc['충북','lon'] = 127.602
df.loc['대전','lat'] = 36.263
df.loc['대전','lon'] = 127.404
df.loc['경남','lat'] = 35.295
df.loc['경남','lon'] = 128.389
df.loc['부산','lat'] = 35.160
df.loc['부산','lon'] = 129.113
df.loc['충남','lat'] = 36.566
df.loc['충남','lon'] = 126.617
df.loc['인천','lat'] = 37.484
df.loc['인천','lon'] = 126.652
df.loc['검역','lat'] = 37.480
df.loc['검역','lon'] = 130.986
df.loc['경기','lat'] = 37.194
df.loc['경기','lon'] = 127.255
df.loc['서울','lat'] = 37.590
df.loc['서울','lon'] = 127.002
df.loc['경북','lat'] = 36.652
df.loc['경북','lon'] = 128.828
df.loc['대구','lat'] = 35.826
df.loc['대구','lon'] = 128.527
center = [37.541, 126.986]
m = folium.Map(location=center, zoom_start=10)
for index, row in df.iterrows():
folium.Circle(
location = (row['lat'],row['lon']),
tooltip = row['row'],
fill_color='#ff00ff',
radius = row['확진환자']*10
).add_to(m)
m
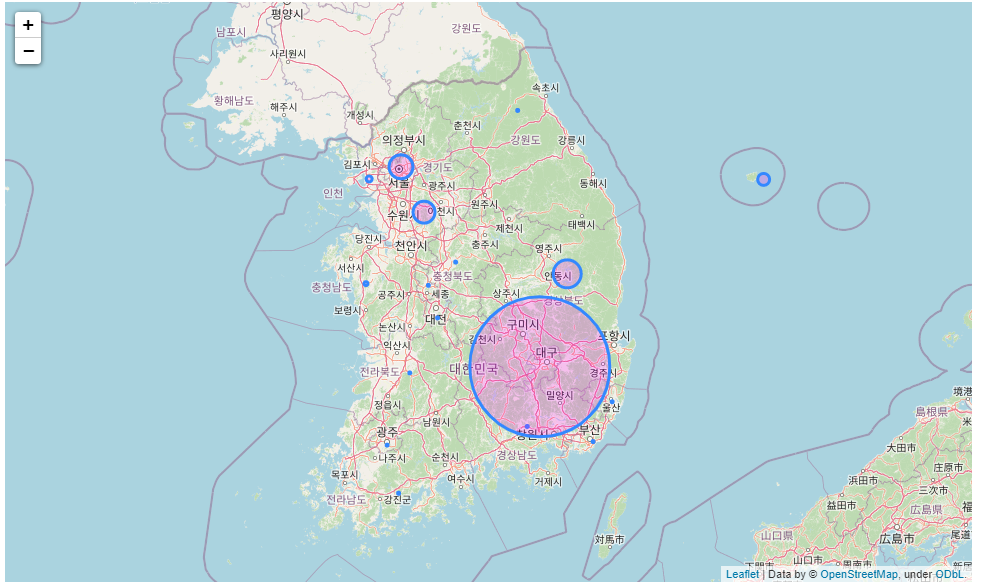
folium.Map 과 folium.Circle을 이용해 확진환자의 양을 지도상에 표기하는 방식이다. folium 에는 이렇게 실제 지리학적인 위치를 이용해서, 단순히 원 뿐만 아니라 선, 도형 또는 마커를 이용해서, 표기할 수 있는 장점이 존재한다. 지역별 확진환자를 시각적으로 가장 잘 볼 수 있는 이미지이다.
이번에는 bubble plot 이라는 것을 알아볼 텐데, bubble plot은 index 별 원을 두가지 attribute에 대해서 scatter 하게 되는데, 점이 radius 를 가지는 plot이다. scatter plot에서 상관관계를 잘 알아볼 수 있다면, bubble plot은 상관관계 뿐만 아니라, 해당하는 3번째 attribute에 대해서도 비교가 가능하다는 장점이 있다.
import plotly.express as px
import cufflinks as cf
fig = px.scatter(df, x="확진환자", y="사망자", size="격리중", color="row", hover_name="row", log_x=True, size_max=60)
fig.show()
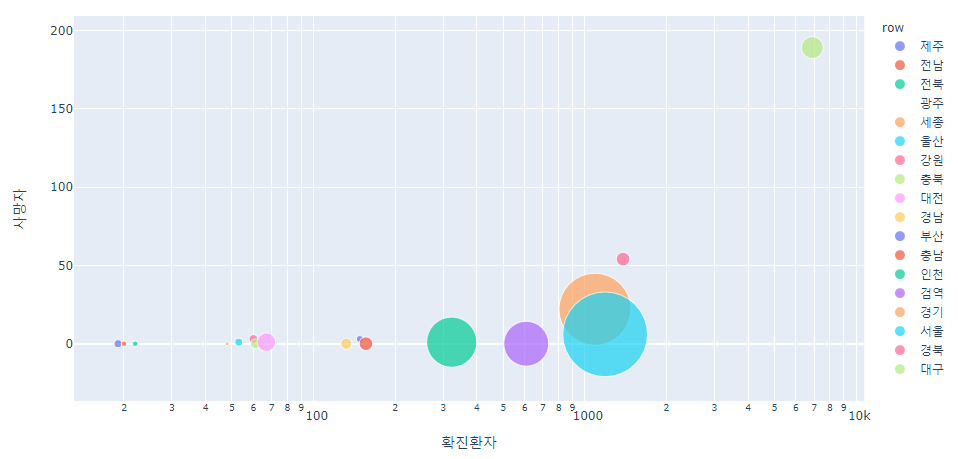
위와 같은 형태로 각 원의 중심은 확진환자와 사망자 수의 상관관계를 나타내며, 원의 크기는 현재 격리중인 사람 수를 표현하고 있다. 즉 3가지의 정보를 효과적으료 표현해줄 수 있는 것이다. bubble plot에서는 color를 군집별로 다르게 해줄 수 있는데, 지금은 row값(지역) 마다 모두 색을 다르게 했지만, 만약 대륙별로 또는 지역을 크게 나누어 준다면 같은 군집간에는 같은 색깔로 표현가능하다는 장점도 존재한다.
이번에는 color map이다. heat map 이라고도 하는데, 색깔을 이용해 요소들의 상관관계를 표현해주는 시각화 방법이다. 데이터로는 이제 COVID 데이터 말고 많이 사용되는 유명한 데이터 셋을 이용해 보겠다.
유명한 데이터 셋의 경우 패키지를 이용해서도 쉽게 다운 받을 수 있는데 seaborn 패키지를 이용해보겠다. seaborn 역시 데이터 시각화 패키지이다.
import seaborn as sns
titanic = sns.load_dataset("titanic")
flights = sns.load_dataset("flights")
flights 데이터의 경우 여객 운송 데이터로, heatmap을 보여줄 수 있는 좋은 데이터 셋이다. 데이터는 year, month 그리고 passengers 세가지 특성이 존재한다. 따라서 year, month 에 대한 탑승객 수를 그래프로 표현해 줄 수 있다.
flights_passengers = flights.pivot("month", "year", "passengers")
sns.heatmap(flights_passengers, annot=True, fmt="d", linewidths=1)
plt.show()
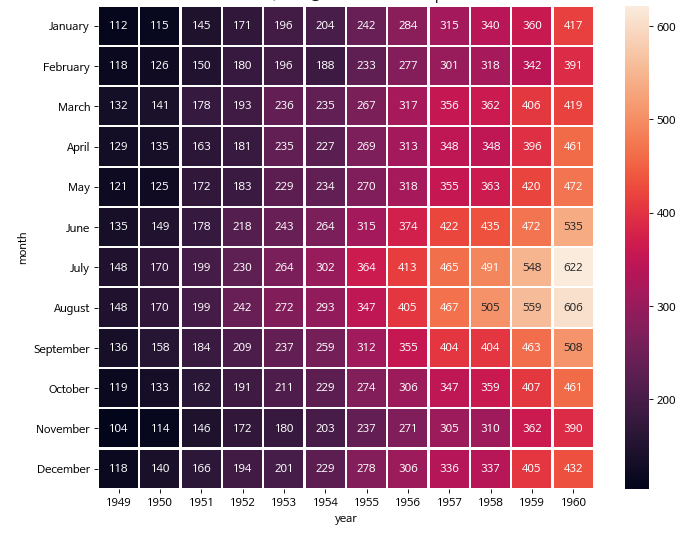
마치며
이번 글에서는 Data Visualization 에 대해 다루어보았다. 데이터를 시각화 하는 과정은 위에서 다루었듯이 매우 중요합니다. 빅데이터 시대인 만큼 방대한 양의 데이터에서 데이터 사이언티스트들은 자신이 필요로 하는 정보롤 뽑아낼 줄 알아야 하며, 그것의 바탕이 시각화 이다. 시각화 과정에서 우리는 가설을 세우고, 그 가설을 후에 통계학적 모델을 이용해 검정하게 된다. 이 때 우리는 보통 여러가지 통계학적 가정(정규분포, 등분산)을 하고, 이에 따라 변인들간의 관계를 여러가지 검정방법을 거쳐 검증하게 된다. (t-test, f-test , chi-square , regression 등) 이 포스트에서 소개 되지 않은 여러가지 시각화 패키지들이 존재하며, 3개 이상의 변인을 다룰 때는 또 색다른 형태의 plot을 보여주어야 할 수 도 있다. 물론 데이터사이언티스트라고 꼭 이런 여러가지 패키지를 모두 다룰 필요는 없지만 각 패키지 마다 장점 또는 단점들이 존재하므로, 어떤 plot은 어떤 패키지를 사용할 지, 어떤 데이터에는 어떤 plot을 통합해서 사용할지 등을 미리 결정하고 진행하면 매우 순조롭게 진행할 수 있다.
참고자료
http://www.secmem.org/blog/2020/05/19/Web-Crawling/
https://en.wikipedia.org/wiki/Exploratory_data_analysis
https://en.wikipedia.org/wiki/Data_visualization