Web Crawling & Scraping
Web Crawling & Scraping
Contents
- 웹 크롤링 & 스크레이핑이란?
- Beautiful Soup 사용법
- 로그인 및 크롤링
- 다양한 웹 데이터 형식
- 마치며
- 참고자료
웹 크롤링 & 스크레이핑 이란?
데이터 과학이나 머신러닝 분야에 관심이 많은 학생이라면 데이터를 구하는 과정에 있어서 적지 않은 어려움을 겪었던 적이 있었을 것이다. 많은 가공된 오픈 데이터들을 요즘은 쉽게 얻을 수 있지만, 막상 실제 데이터 분석작업을 해보려고 하거나, 실제 프로젝트를 진행해보려고 하면 원하는 오픈 데이터를 쉽게 찾기는 어렵기 마련이다. (오픈 데이터란 자유롭게 다운받고 사용할 수 있는 정형화되었고 잘 가공된 데이터를 말한다.)
따라서 인터넷 검색만으로 찾을 수 있는 여러 비정형화된 데이터들을 우리는 정형화시켜서 사용 가능한 데이터들로 만들 수 있는 실력을 길러야 한다. 그 방법의 가장 기본이 되는 것이 웹 크롤링과 스크레이핑이다. 우선 비정형데이터와 정형데이터의 차이는 무엇일까? 텍스트는 기본적으로 비정형 데이터로 순수 텍스트를 아무런 전처리 없이 사용하는 것은 사실 어려움이 따른다. 비정형 데이터에 대한 정의는 아래와 같다.
- 비정형 데이터(Unstructured Data)란 일정한 규격이나 형태를 지닌 숫자 데이터와 달리 그림이나 영상, 문서처럼 형태와 구조가 다른 구조화 되지 않은 데이터를 가리킨다.
우리는 데이터 분석을 위해 비정형 데이터의 정형화가 요구된다. 그리고 이 과정을 전처리라고 부른다. 전처리의 가장 기본적인 단계가 바로 웹 크롤링과 스크레이핑이 된다. 각 방법에 대한 정의는 아래와 같다.
- 크롤링 : 프로그램이 웹 사이트를 정기적으로 돌며 정보를 추출하는 기술
- 스크레이핑 : 웹 사이트에 있는 특정 정보를 추출하는 기술
대부분의 웹에 공개된 정보는 HTML의 형식으로 작성되어 있기 때문에, 데이터를 받아와 저장하기 위해서는 데이터를 가공하는 과정이 필수적입니다. 따라서 크롤링과 스크레이핑은 단순히 웹에서 데이터를 추출하는 것 뿐만 아니라 각종 작성 형식의 구조를 분석하는 작업도 포함이 된다.
또한 로그인해야 유용한 정보에 접근이 가능한 사이트들도 많기 대문에 이럴 때 접근하는 방법 또한 소개해보려고 합니다.
데이터 받아 가공하기
앞으로의 모든 코드는 python 3.7 버전을 사용했고, 웹페이지에 요청을 보내는 패키지로 urllib.request 또는 requests 가 존재하는데 여기서는 requests를 사용했습니다. 그리고 html 분석용으로 beautifulsoup 패키지를 사용했습니다.
import sys
sys.version
'3.7.3 (default, Mar 27 2019, 17:13:21) [MSC v.1915 64 bit (AMD64)]'
import requests
from bs4 import BeautifulSoup
현재 코로나 바이러스 문제가 매우 이슈가 되고 있으므로, 우리나라의 코로나 실황으로 알아보도록 하겠습니다. 보건복지부 코로나 바이러스 동향 사이트인 http://ncov.mohw.go.kr/ 에서 시도별 확진환자 현황을 자세히 보기를 누르면 나오는 웹 페이지를 읽어보자.
url = 'http://ncov.mohw.go.kr/bdBoardList_Real.do? brdId=1&brdGubun=13&ncvContSeq=&contSeq=&board_id=&gubun='
req = requests.get(url)
html = req.text
위의 코드를 실행하면 html 안에 우리는 text형식으로 웹페이지의 html 코드를 모두 받아오게 된다. 이 html은 출력으로 확인할 수 있고, 실제 웹페이지에서 F12를 눌러서 확인해 볼 수 도 있다.
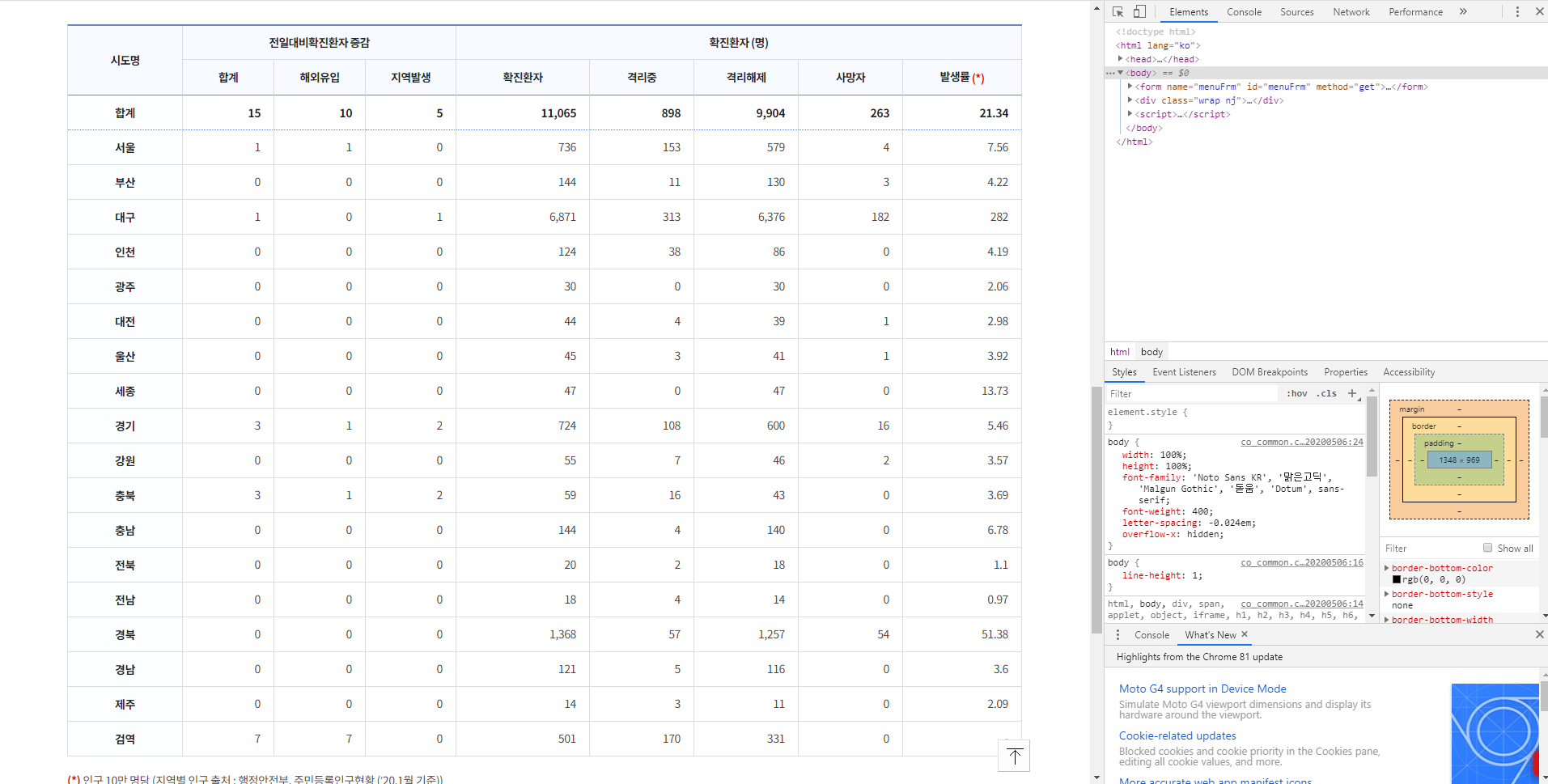
F12를 누르게 되면 위에 보이는 사진의 오른쪽 부분처럼 그 해당 웹페이지의 html코드가 나오게 된다. 우리는 이 부분의 text를 받아온 것이다. 이제 사진의 왼쪽 부분인, 테이블 형태의 데이터를 한 번 저장해보려고 한다. 웹페이지에서 Ctrl+Shift+C를 누르고 테이블을 선택해주면,
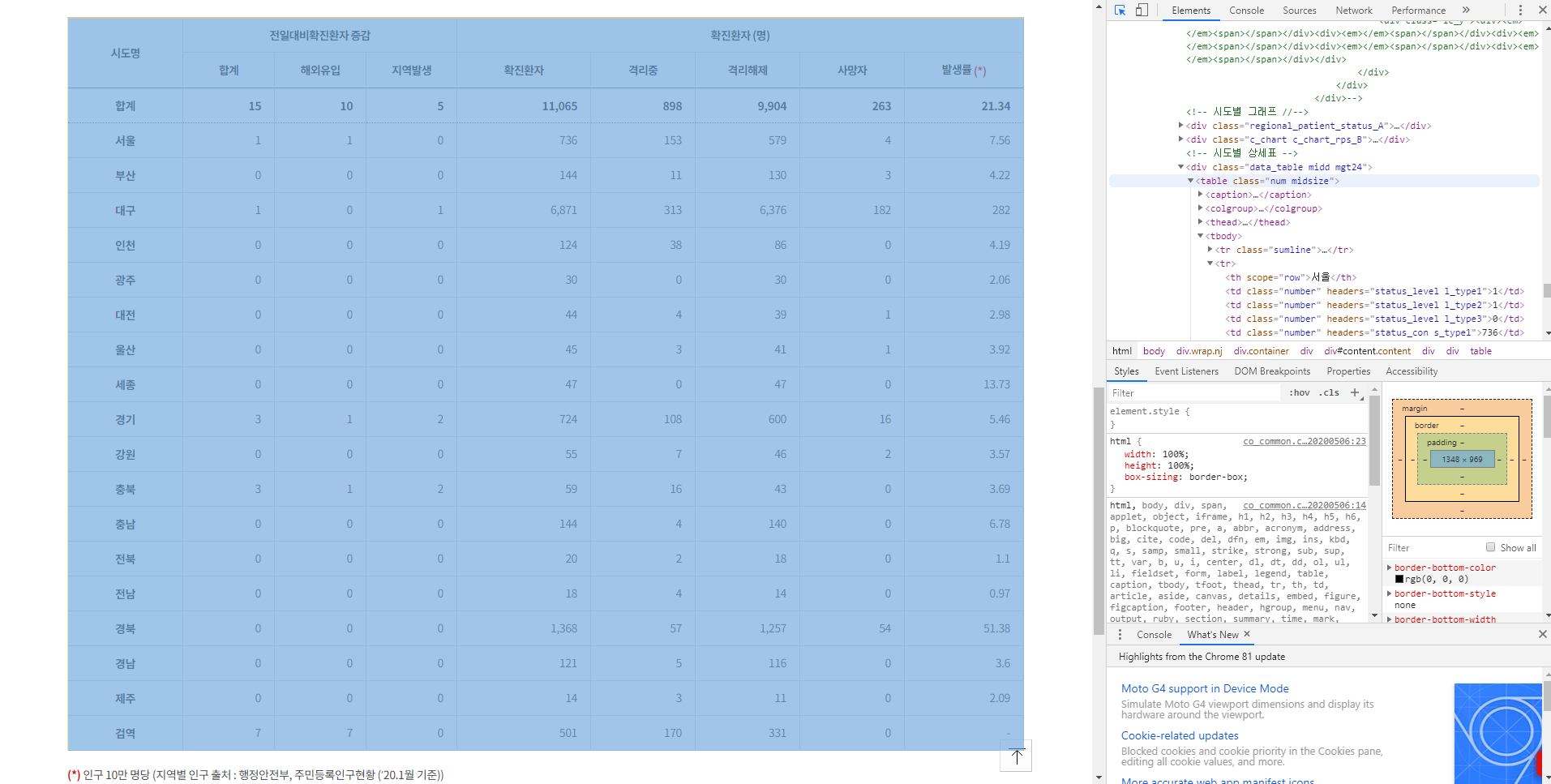
위의 사진 처럼 html의 해당 코드 부분이 선택되게 된다. 우리는 집중해서 봐야할 부분이 바로 <table class = "~~"> 하는 부분이다. 이부분을 이용해서 BeautifulSoup를 통해 해당 부분만 불러올 수 있게 된다. 아래 코드를 참고하자.
soup = BeautifulSoup(html, 'html.parser')
tables = soup.find_all('table',{'class':'num midsize'})
head = tables[0].find('thead')
body = tables[0].find('tbody')
BeautifulSoup를 이용해 html text를 html.parser을 이용해서 soup가 판단할 수 있게 나눠준다. table을 모두 찾아내는데, class 변수가 ‘num midsize’ 인 것을 찾아 내는 것이다. 이 웹페이지에서는 해당하는 테이블이 하나 뿐이므로 find를 써도 무방하다.
그 후에 tables에는 찾아낸 table의 html코드가 들어가게 된다. 우리는 여기서 다시 한 번 head (indices) 들과 body(실제 data) 로 나누어 주게 된다.
<thead>
<tr>
<th rowspan="2" scope="col">시도명</th>
<th colspan="3" id="status_level" scope="col">전일대비<br/>확진환자 증감</th>
<th colspan="5" id="status_con">확진환자 (명)</th>
</tr>
<tr>
<th id="l_type1" scope="col">합계</th>
<th id="l_type2" scope="col">해외<br/>유입</th>
<th id="l_type3" scope="col">지역<br/>발생</th>
<th id="s_type1" scope="col">확진<br/>환자</th>
<th id="s_type2" scope="col">격리<br/>중</th>
<th id="s_type3" scope="col">격리<br/>해제</th>
<th id="s_type4" scope="col">사망자</th>
<th id="s_type5" scope="col">발생률<br/><span class="txt_ntc_bold"> (*)</span></th>
</tr>
</thead>
<tbody>
head 부분을 출력해보면 위와 같이 나타나게 된다. 우리는 여기서 2번째 tr 파트의 th 별 값들을 필요로 한다. 아래 코드를 작성해보자.
columns = head.select('tr')[1].select('th')
columnlist=[]
for column in columns:
columnlist.append(column.text.split(' ')[0])
우선 head 에서 tr 들을 select 해준 다음 2번째 (0번지부터 시작하므로 [1]에 저장된다.) 파트에서 th를 다시 select해준다. 그 후 columnlist에 해당 값들을 넣어주게 된다. 이 후 columnlist를 실제로 출력해보면
['합계', '해외유입', '지역발생', '확진환자', '격리중', '격리해제', '사망자', '발생률']
이렇게 이쁘게 column 명들이 들어가게 된다. split의 경우 마지막 column 인 발생률이 ‘발생률 (*)’ 형태로 존재하므로 ‘ ‘로 잘라서 앞부분을 넣는 방식으로 편집해준 모습이다.
그럼 이제 같은 방법으로 body 또한 해체 시켜준다.
rows = body.select('tr')
rowlist=[]
datalist=[]
datas=[]
for row in rows:
rowlist.append(row.select('th')[0].text)
datas = row.select('td')
for data in datas:
datalist.append(data.text)
def divide_list(l, n):
for i in range(0, len(l), n):
yield l[i:i + n]
n = 8
result = list(divide_list(datalist, n))
body 부분을 출력해 보면, 지역 이름이 th 에 들어있고, 해당하는 값들은 tr에 있는 것을 확인할 수 있다. 따라서, rowlist에는 th에 해당하는 지역이름들을 넣어주고, datalist 에는 값들을 넣어주었다. 그 후에 각 지역별로 8개의 값이 해당되므로 divide_list라는 함수를 만들어서 8개씩 잘라서 result에 넣어주는 모습이다.
이제 값들을 모두 긁어왔으므로, pandas 를 이용해 데이터 프레임을 만들려고 한다. 데이터프레임으로 테이블형태의 데이터를 관리해주면, 정렬 또는 분석등 여러가지 용이한 작업들을 편리하게 수행할 수 있다. 딕셔너리 변수를 만든 후에, from_dict함수를 사용해서 넣어주면 된다. 아래 코드를 참고하자
my_dict = {}
i = -1
for res in result:
i = i + 1
my_dict.update({rowlist[i]:{columnlist[0]:res[0],
columnlist[1]:res[1],
columnlist[2]:res[2],
columnlist[3]:res[3],
columnlist[4]:res[4],
columnlist[5]:res[5],
columnlist[6]:res[6],
columnlist[7]:res[7]}})
df = pd.DataFrame.from_dict(my_dict, orient='index')
df.set_value(df['발생률'] == '-','발생률',0)
display(df)
rowlist[i] 에는 해당 지역명이 들어있고, columnlist 에는 각 column 이름이들어있으며, res[] 에는 각 지역별 수치들이 들어있다. 위와 같이 dataframe을 만들어 준 후에, 발생률에 누락된 ‘-‘ 값이 있으므로 0으로 치환해준 모습이다. display를 해주면 아래와 같이 우리가 원하는 테이블을 얻어낼 수 있다.
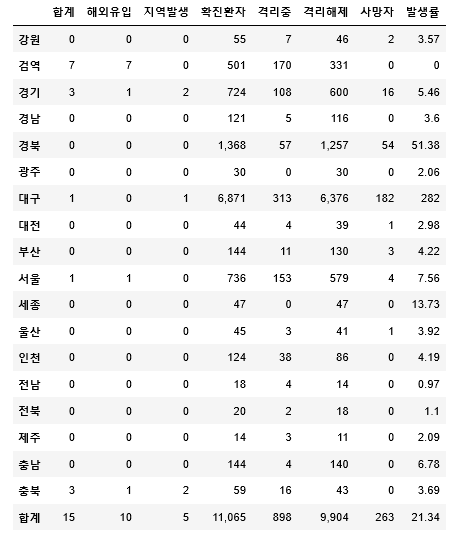
이제 아쉬운 부분이 있다면 현재 데이터들이 text형태로 존재한다는 것이다. 이를 바꿔주기 위해서는, astype으로 바꿔주거나, to_numeric 함수를 사용할 수 있다. 우선 ‘,’ 가 존재하므로 앞서 my_dict.update 부분 위에다가 콤마를 삭제하는 코드를 넣어준다.
def erasecomma(s):
if s == None:
return 0
elif s != None:
return s.replace(',', '').strip()
# =================================================
for j in range(0,8):
res[j] = erasecomma(res[j])
# =================================================
그리고 to_numeric으로 모두 값들로 바꿔준 다음에, 확진환자를 기준으로 내림차순 정렬을 해보자.
for column in columnlist:
df[column] = pd.to_numeric(df[column])
df.sort_values(by='확진환자',axis=0,ascending=False)
여기에 사망률이라는 column을 추가하고 싶다면 아래와 같이 추가해주면된다.
df['사망률'] = df['사망자']/df['확진환자']
df.sort_values(by='사망률',axis=0,ascending=False)
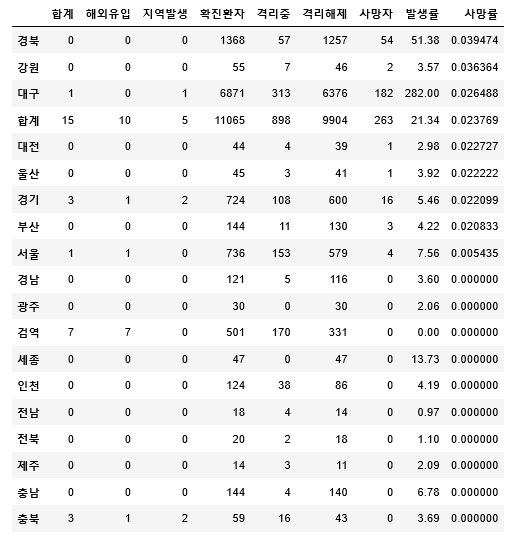
사망률로 정렬된 최종 모습이 나왔다.
물론 평상시 데이터의 경우 더 양이 많고 여러가지 데이터 가공기법이 필요할 수 있다. 대부분의 경우 위에서 사용된, split() / yield() / replace() / strip() 같은 함수들을 사용해 텍스트들을 편집해주는 방법을 잘 익혀두면 매우 도움이 된다.
로그인 및 크롤링
크롤링의 linux 나 mac OS에서는 별도의 프로그램인 cron이라는 것을 이용해서 정기적 데이터 추출을 하는 반면 Windows에서는 작업스케쥴러라는 내장된 프로그램을 통해, 작업을 만들고, 트리거를 설정한 후에 실행할 스크립트를 지정해주면 간단하게 해결가능합니다. linux에서 cron을 사용할 때에는 우선 cron을 설치하고, crontab 파일을 [작업 예약 시간] – [실행할 프로그램(파이썬)] – [실행할 대상(파이썬 스크립트 경로)] 순으로 작성해서 넣어주면 간단하게 해결이 가능합니다.
이제 로그인 기법에 대해 알아보려고 합니다.
웹페이지에 로그인해서 데이터를 받아오고 싶다면 우선 웹페이지에 로그인을 할 때 어떤 방식으로 처리가 되는지를 잘 알고 있어야 합니다. 로그인의 경우 대부분 초기화면 html 에서 각 해당 아이템 (id / password) 에 자신의 아이디 비밀번호를 입력하고, 로그인 버튼을 누르게 됩니다. 그러면 대부분의 경우 POST 형식으로 (id / password)를 지닌 채로 로그인 request를 하게되고, 로그인정보가 알맞는지 데이터베이스와 연동되어 확인하는 php 파일을 거쳐서, 로그인 후의 페이지인 html 코드로 돌아오게 됩니다.
전체적인 틀은 모두 동일하지만, 네이버 등의 여러 포털 사이트의 경우에 대부분 다양한 보안 요소를 넣고 있어서 (암호화) 단순한 request를 이용해서는 접근이 쉽지 않습니다. 물론 이 글을 작성하면서 찾아본 결과 가능은 하므로 찾아서 공부해보시는 것도 도움이 될 것 같습니다.
하지만 Selenium 이라는 패키지를 이용해서, 쉽게 로그인을 하는 방법이 존재합니다. 여기서 Selenium 패키지는 단순히 웹을 실행시켜준다고 생각하면 된다. webdriver를 통해서 chrome을 실행시켜 우리가 로그인을 하듯이 진행을 하는 것이다. 아래 코드를 참고해보겠습니다.
from selenium import webdriver
driver = webdriver.Chrome('C:\chromedriver.exe')
driver.get('https://nid.naver.com/nidlogin.login')
driver.find_element_by_name('id').send_keys(USER)
driver.find_element_by_name('pw').send_keys(PASS)
driver.find_element_by_xpath('//*[@id="log.login"]').click()
(로그인 버튼의 경우에 name 인자를 가지고 하면 찾지를 못하는 문제가 발생해서 xpath 를 사용했다.) xpath 의 경우 F12를 누르고 Ctrl+Shift+C 를 한 상태에서 해당 코드 부분에 마우스 오른쪽 클릭을 하고 코드 부분에 들어가면 xpath 를 복사하는 탭이 존재한다. 위와 같은 형태로 실제 웹을 실행시켜버리는 것이다. 이 방법을 통해서 로그인을 한 후에 특정 홈페이지에 다시 들어가서, 위에서 진행한 방법대로 웹을 긁어오면 되는 것이다.
다양한 웹 데이터 형식
앞서 비정형 데이터에 대해 설명을 했다. 웹의 데이터 형식의 경우 매우 다양하게 존재한다. 우선 이 형식들을 표현하는 텍스트는 기본적으로 우리가 쉽게 읽을 수 있는 텍스트 데이터와, 바이너리 데이터로 나뉘어 진다. 바이너리 데이터의 경우에, 용량이 적어 더 효율적으로 데이터를 저장할 수 있지만 우리가 읽기 매우 불편하다.
그렇다면 이제 웹 페이지의 데이터의 경우 어떤 형식이 존재하는지 알아보자.
바로 XML / JSON / CSV 같은 형식들이 존재한다.
CSV파일은 앞서서 또 데이터 분석 때 많이 다루는 데이터 형태이고 매우 직관적이므로 넘어가고 남은 3개의 형식에 대해서 어떻게 불러서 읽는지 보여주려고 한다.
-
XML
XML은 똑같이 beautifulSoup로 접근해주면 된다.
xml = open(xmlfilename, "r", encoding = "utf-8").read() soup = BeautifulSoup(xml, 'html.parser') for key in soup.find_all(keyname): print(key)xml파일의 이름을 xmlfilename에 넣어주면된다. xml 파일은 url을 통해 request 또는 urlretrieve 같은 함수들로 불러올 수 있다. xml 코드 자체가 해당 요소 -> 내용 들의 구성으로 되어있으므로 keyname에 요소의 id를 넣어주면 우리가 원하는 부분을 찾아서 저장해 줄 수 있다.
-
JSON
json은 javascript에서 사용되는 객체 표기 방법을 기반으로 하는 데이터 형식입니다. 구조가 매우 단순해서 쉽게 이해할 수 있는 장점이 있습니다. 아래 코드를 참고해줍니다.
import urllib.request as req import os.path, random import json url = "https://api.github.com/repositories" savename = "practice.json" if not os.path.exists(url): req.urlretrieve(url, savename) items = json.load(open(savename, "r", encoding = "utf-8")) for item in items: print(item["name"])json 파일은 사실 json 형식의 파일을 단 한 번이라도 다루어 보았다면 매우 쉽게 이해할 수 있다. 웹페이지 호스팅 같은 작업을 하거나 API를 불러오거나 할 때 거의 무조건 이용되는 형식이다 보니 잘 알고 있으면 도움이 된다. 다음은 json 형태로 출력하는 방법이다.
info = { "name" : "jeongmin", "birth" : "1996-12-06", "mail" : { "naver":"cjmp1@naver.com", "google":"chlwjdals1996@gmail.com" } } s = json.dumps(info) print(s) -
CSV
CSV 파일은 (Comma-Separated Values) 의 약자로 단순히 데이터들을 comma로 분리해 놓은 것을 말한다. 첫 번째 행을 헤더로 사용하고 모든 데이터들을 콤마로 분리해 나열하는 식이다. pandas에서 제공하는 csv_read() 를 이용해서 읽어줄수 있고, Microsoft Excel 같은 프로그램에서도 읽는 방법을 제공한다.
마치며
사실 크롤링 / 스크레이핑 같은 경우 제대로 가르쳐 주는 곳이 적다. 대부분 major한 데이터 분석 과정이나, 머신러닝에 대한 강의는 많지만 이런 부분은 자기가 직접 찾아보면서 공부해야 하는 부분인지라 공부했던 부분을 정리해보면서 작성해 보았다. 물론 이 글을 작성하려고 하니 실제로 크롤링에 대해 다룬 게시글들이 어느 정도 생긴 것을 확인할 수 있었다. 이런 기본적인 기술들은 어떤 작업을 한다 하더라도 중요하다고 생각한다. 따라서 한 번 쯤은 깊이있게 공부해보는 것을 추천한다.
참고자료
위키북스 : 머신러닝 딥러닝 실전개발 입문