AI tutorial - Image Classification
AI tutorial - 1 . Image Classification
Contents
- 들어가며
- 이미지 분류기란?
- Pytorch로 만든 이미지 분류기
- 발전 방향
- 참고
들어가며
인공지능 분야에 대한 관심과 발전이 비약적으로 상승하고 있는 시대입니다. 인공지능의 시대라고 할 정도로 인공지능은 우리의 삶에 도움을 주고 있고, 그 정도도 끊임없이 상승하고 있죠. 비전공자 또는 일반적인 사람들도 인공지능에 대해 알고자 하고, 공부하고자 하는 사람이 늘어났습니다.
인공지능을 발전시킨 딥러닝, 머신러닝 기술들은 현재진행형 상태입니다. 많은 연구가 진행되고 있고, 성능을 계속 향상시키는 논문들이 발표되고 있습니다. 속도는 빠르게, 정확도는 높여가는 방향으로 말입니다. 사실 AI 기술들을 사용하기 위해서, 직접 코딩을 해야하거나 모델을 만들어야 하거나 하는 필요성은 전문분야의 사람이 아니라면 꼭 필요하지는 않습니다. 요즈음에는 각종 클라우드 서비스에서 모델들을 모두 제공하고 있고, 그냥 가져다가 쓰기만 하면 되기 때문입니다. 하지만 이에 익숙해지면, Custom 하고 싶은 기술들을 사용할 때 분명히 힘들 것이고, 제대로 된 내용을 모르는 채로 진행하는 것은 별로 의미가 없다고 생각을 했습니다.
AI 분야에는 여러가지 분야가 있습니다. Image Classification, Object Detection, Semantic Segmentation, Neural Style Transfer, Word2Vec(word embedding), Natural Language Processing, Variational Auto Encoder, Cycle GAN, Speech Recognition 등 수많은 종류가 있습니다. 이 뿐만 아니라 Reinforcement Learning도 한 분야를 차지합니다. 저는 이러한 여러가지 분야에 대해서 기본적인 진행되는 논리와 Custom 할 수 있는 코드들을 직접 작성해 보면서 도움이 될 수 있기 위해 글을 작성하게 되었습니다.
기초적인 딥러닝에 대한 기본 구동원리에 대한 지식이 있는 상태라고 가정을 하고 기본적인 AI 기술들을 다루며 튜토리얼 가이드라인을 작성한다는 생각으로 만들어 보았습니다.
이미지 분류기란?
처음으로 다루고자 하는 AI기술은 이미지 분류기로 선택했습니다. 가장 흥미를 가지기 좋은 기술이기도 하고, 쉽게 구현이 가능하며, 많은 연구가 진행된 분야이기 때문입니다. 발전 방향도 매우 무궁무진합니다. 유명한 스탠포드 대학교의 딥러닝 강의인 cs231n에서도 이미지 분류기를 처음에 설명하기도 합니다.
이미지 분류는 말 그대로 인공지능이 이미지들을 분류할 수 있도록 하는 것을 말합니다. 강아지와 고양이 사진을 사람에게 보여주었을 때, 우리는 기본적인 상식과 시각이미지를 통해서 사진을 구별해낼 수 있습니다. 하지만 컴퓨터입장에서는 두 사진을 어떻게 구별해야 할까요? 이미지는 W * H * C (W : width , H : height, C : channel (RGB그림의 경우 3))개의 픽셀값으로 이루어져있습니다. 이 픽셀값들을 바탕으로 연산을 통해 강아지인지 고양이인지 구별을 하게 됩니다.
그럼 이 상황에서 이미지를 분류하는데에 있어서 컴퓨터가 어려움을 가지는 이유는 무엇 때문일까요?
첫 번째로 가장 원초적인 문제입니다. 강아지 사진이 있다고 가정합니다. 컴퓨터는 단순히 숫자로 이루어진 grid를 보게 되는데, 강아지에 해당되는 숫자들만을 고려한다고 생각해봅시다. 이 숫자들이 멀리 떨어지면 떨어질 수록 신경망 내에서는 연관성을 부여하기 힘들어집니다. 즉 pixel 레벨에서 semantic level 로 올라가는 단계에서 어려움을 가지게 됩니다.
두 번재는 이미지 자체의 문제입니다. 강이지와 고양이를 구별하고자 할 때, 우리는 강아지, 고양이만 딱 있는 사진을 이용하는 것이 아니라 배경이 포함된 사진을 사용하게 될 것입니다. 또한 빛 등의 요소로 인해 강아지나 고양이의 일부가 누락되는 이미지일 수도 있습니다. 사람의 경우 꼬리나 얼굴만 보고도 강아지 고양이를 구별해낼 수 있지만 꼬리만 나온 사진을 학습된 인공지능이 잘 구별하기는 어렵습니다.
이를 해결하기 위해서 여러가지 노력들이 진행중입니다. 윤곽선을 미리 뽑아내고 classification을 진행하는 것도 하나의 방법이 될 수 있고, transform(rotation, scale) 같은 형태는 정형화된 모양으로 만들어낸 후 분류를 학습하는 것도 연구되었습니다.
기본적으로 주어지는 이미지 X가 있고, 이 X로 부터 feature들을 뽑아내게 됩니다. feature(특징)이란 이미지에서 얻어낼 수 있는 고유한 패턴을 의미한다고 얘기할 수 있습니다.
이미지에 나타나게 되는 가로선 도는 세로선 만을 뽑아낸 것도 하나의 featuer map이 될 수 있고 이미지에 나타나는 어떤 패턴만 뽑아진 것도 그 이미지의 feature가 될 수 있습니다.
이 feature을 뽑아내는 함수를 f라 하고 feature를 바탕으로 분류값을 도출해내는 함수 g가 있습니다. 저희가 하고자하는 것은 바로 g(f(X)) 를 이미지 분류값에 맞추게 하는것입니다.
사실 이 g 함수에서는 각 분류별로 확률p를 도출해내게 됩니다. 이 이미지가 이 분류일 확률을 계산해내는 것이죠. 그래서 가장 높은 확률을 가지는 분류를 결과값으로 출력하게 됩니다.
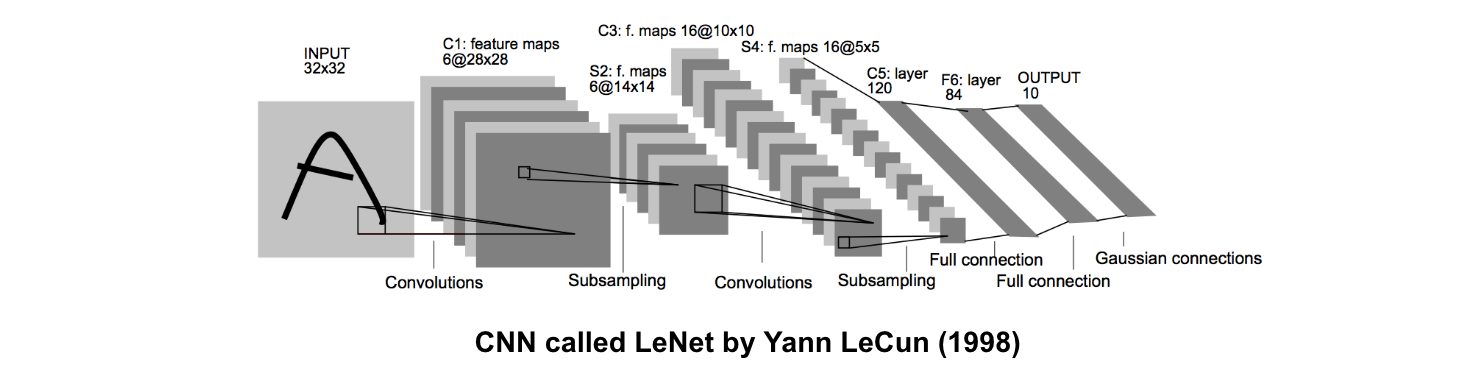
위 이미지는 위에 간략히 설명한 내용을 가장 잘 표현해주는 그림으로 LeNet 이라는 CNN구조를 소개한 논문에서 발췌했습니다. 기존의 이미지를 Convolution을 통해 6개의 feature maps를 만들어 내게 되고 subsampling 후에 다시 16개의 maps를 만들고 그 후에는 FC(fully connected layer)를 통해서 각 분류값별 확률을 도출해내게 됩니다.
자세한 각 layer별 설명은 코드와 함께 아래에서 설명을 해보겠습니다.
Pytorch로 만든 이미지 분류기
우선 데이터의 경우 kaggle에 있는 cat-vs-dog 데이터를 사용했습니다.
import os
import torch
import torch.nn as nn
import torchvision
import matplotlib.pyplot as plt
from torch.utils.data import Dataset, DataLoader, ConcatDataset
from torchvision import transforms
from PIL import Image
커스텀 데이터를 사용할 경우에 class를 선언해주고, torch에서 제공하는 Dataset 과 DataLoader함수를 사용해주면 됩니다. 이 때 Dataset format을 사용하기 위해서 class에는 init, len, get_item 이 있어야합니다.
len의 경우 Dataset의 크기를 리턴해주어야 하고, get_item의 경우에 i번째 샘플을 찾는데 사용하게 됩니다.
class CustomData(Dataset):
def __init__(self, file_list, dir, transform = None):
self.file_list = file_list
self.dir = dir
self.transform = transform
if 'dog' in self.file_list[0]:
self.label = 1
else:
self.label = 0
def __len__(self):
return len(self.file_list)
def __getitem__(self, idx):
img = Image.open(os.path.join(self.dir, self.file_list[idx]))
if self.transform:
img = self.transform(img)
img = img.numpy()
return img.astype('float32'), self.label
코드에 표기된 transform 인자를 통해서 데이터셋의 전처리과정을 넣어줄 수 있습니다. 주어진 이미지 크기가 모두 동일하지 않기 때문에, 아래와 같은 전처리 transform을 정의해줍니다.
data_transform = transforms.Compose([
transforms.Resize(256),
transforms.ColorJitter(),
transforms.RandomCrop(224),
transforms.RandomHorizontalFlip(),
transforms.Resize(128),
transforms.ToTensor()
])
이제 다운로드 받은 데이터를 불러와서 선언해줍니다.
train_dir = './data/train/train'
test_dir = './data/test/test1'
train_files = os.listdir(train_dir)
test_files = os.listdir(test_dir)
cat_files = [tf for tf in train_files if 'cat' in tf]
dog_files = [tf for tf in train_files if 'dog' in tf]
cats = CustomData(cat_files, train_dir, transform = data_transform)
dogs = CustomData(dog_files, train_dir, transform = data_transform)
catdogs = ConcatDataset([cats, dogs])
trainloader = DataLoader(catdogs, batch_size = 32, shuffle=True, num_workers=0)
Dataset의 경우 현재 {image : image , Label : label} 형태의 tuple로 선언이 되어있습니다.
또한 DataLoader라는 함수를 이용해서 pytorch 에서는 학습을 진행하게 됩니다. Dataloader는 데이터를 묶는 과정과, 섞는 과정 그리고 multiprocessing을 이용할 경우 데이터를 불러오는 것을 모두 제공해주는 iterator라고 생각주면 된다.
실제 데이터값을 확인해 보기 위해서는 catdogs[i] 를 출력해주면 됩니다. image를 보기 위해서는 catdogs_i_0 값을 numpy array로 받아온 다음에 plt.imshow() 를 이용해서 이미지를 찍어낼 수 있습니다.
이 때 주의할 점은 pytorch dataset의 경우 C * W * H 즉 채널이 앞부분에 있습니다. plt의 경우에 채널이 마지막 인자로 들어가야 하므로, plt.imshow(np.transpose(npimg, (1, 2, 0))) 구문이 필요하게 됩니다.
이제 학습에 사용할 모델을 선언해주어야 합니다. torchvision에 내장되어있는 model을 그냥 불러와서 사용해도 되고, model을 직접 선언해주어도 상관 없습니다.
직접 모델을 사용할 경우 nn.module을 상속받는 class를 만들어주어야 합니다. 이 때 선언하는 함수로, init과 forward 함수를 반드시 포함해주어야 합니다. nn에는 아래와 같은 모듈들이 미리 정의되어 있어서 사용을 해주면 편리하게 모델 구성을 해줄 수 있습니다.
- nn.Conv2d(input_channels, output_channels, kernel_size, stride, padding) : convolution layer를 만들 때 용이
- nn.MaxPool2d() : pooling을 할 대 사용한다.
- nn.Sequential() : 순서대로 안에있는 모델을 적용하고 싶을 때 사용한다
- nn.Linear(input, output) : 으로 Fully Connected로 연산을 할 때 사용한다.
이 외에도 Dropout, Relu 등 여러가지가 존재한다. pytorch reference를 참고해주면 된다.
모델을 불러올 때는 그냥 torchvisions.models 에서 불러오게 되고, classifier와 optimizer만 정의를 따로 해주면 됩니다.
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(cnn.parameters(), lr=learning_rate)
이후 각종 hyper parameter들을 세팅해주고 돌릴 epoch수를 지정해준후에 학습을 시작한다.
for epoch in range(num_epochs):
tloss = 0.0
for i, data in enumerate(trainloader):
x, label = data
if use_cuda:
x = x.cuda()
label = label.cuda()
model_output = MyModel(x)
loss = criterion(model_output, label)
optimizer.zero_grad()
loss.backward()
optimizer.step()
tloss += loss.item()
zero_grad()의 경우 역전파를 실행하기 이전에 변화도를 0으로 만들어 주어야 한다.
학습과정을 출력하고 싶다면 loss 와 accuracy list를 만들어주어서 특정 에폭마다 출력해주면 된다.
if itr%ptr == 0:
bef = torch.argmax(output, dim=1)
hap = bef.eq(labels)
acc = torch.mean(hap.float())
print('Epoch {}/{} Iteration {} -> Loss: {:.3f}, Accuracy : {:.3f}'.format(epoch+1, epochs, itr, tloss/ptr, acc))
loss_list.append(tloss/ptr)
acc_list.append(acc)
tloss = 0
itr += 1
끝나고 난 후에는 loss 변화와 accuracy 정확도 변화를 plot해준다.
plt.plot(loss_list, label='loss')
plt.plot(acc_list, label='accuracy')
plt.legend()
plt.title('loss and accuracy')
plt.show()
추가적인 팁으로 시간 관계상 학습을 어느정도 진행한 후에 다시 진행하고 싶은 경우가 있다. 학습에 몇일이 소요되는 경우 이 방법을 사용하게 되는데, 모델을 저장한 후에 다시 불러오는 방식을 사용한다.
## 저장하기
file_path = 'model_parameter.pth'
torch.save(model.state_dict(), file_path)
## 불러오기
model.load_state_dict(torch.load(file_path))
model.eval()
불러올 때 model은 기존에 사용할 모델 클래스이여야 한다는 사실에 유의해야한다.
학습 과정에서는 Train Loss 는 최대 0.101 까지 감소하고 Accuracy는 0.916 까지 상승했다.
이제 test data에서 학습된 모델의 역량을 시험해보아야 합니다. 시험용 자료들도 이미지 파일이 동일한 format으로 이루어져 있지 않으므로 testtransform을 정의해줍니다.
test_transform = transforms.Compose([
transforms.Resize((128,128)),
transforms.ToTensor()
])
test_dir는 앞서 미리 정의를 해놓았기 때문에 바로 test 데이터를 불러와서 Dataset class 형으로 만들어줍니다.
test_files = os.listdir(test_dir)
testset = CatDogDataset(test_files, test_dir, transform = test_transform)
testloader = DataLoader(testset, batch_size = 32, shuffle=False, num_workers=0)
그 후에는 만들어진 모델을 model.eval()을 해준 후에, 테스트 데이터에 대해서 다 연산을 하면 됩니다.
model.eval()
fileIdx = []
Result = []
for x, Idx in testloader:
with torch.no_grad():
x = x.to(device)
output = model(x)
ans = torch.argmax(output, dim=1)
fildIdx += [num[:-4] for num in Idx]
Result += [p.item() for p in ans]
submission = pd.DataFrame({"id":fileIdx, "label":Result})
submission.to_csv('mySubmission.csv', index=False)
output = model(x) 를 통해서 class 갯수만큼의 숫자를 갖는 배열을 받아옵니다. 이는 각 class 별 predict한 확률을 나타내게 되고(여기서는 dogs & cat 이므로 2개) torch.argmax 를 통해서 그 중 큰 값을 선택해서 리스트에 저장후에 출력하게 됩니다.
결과값을 이미지와 함께 미리 확인해보고 싶다면 앞서 알려드린 plt.imshow(np.transpose(sample, (1,2,0))) 를 사용해주면 됩니다.
아마 결과를 확인해보시면 train에서 나왔던 Accuracy가 나오지 않습니다. 매우 처참한 결과입니다. 이는 training set에 너무 overfitting 되었기 때문입니다.
아마 validation set을 사용하면 약간의 성능향상을 기대할 수 있겠지만, 이미지 분류 자체가 data에 영향을 매우 많이 받습니다. 배경값들이 모두 계산에 사용되기 때문에 문제가 될 수 밖에 없습니다. 이를 해결해주기 위해서는 아마 object Detection 이라는 항목을 추가해야합니다. 내가 찾고자 하는 개나 고양이가 어디에있는지 윤곽을 그려준 후에 거기서 이미지 분류를 진행하는 방식이죠.
발전 방향
이미지 분류는 아직 성능 향상 가능성이 무궁무진합니다. 우선 앞서 보신듯이 과적합 문제가 해결해야할 첫 번째 임무입니다. 이는 많은 방법들이 연구되었는데요, Dropout 도 한 예시가 될 수 가 있고, Data expansion, Preprocessing도 좋은 방법이 됩니다. Image Classification의 경우 아래와 같은 진척도를 거쳐왔습니다.
-
2016년 이전 : AlexNet, VGG, GoogLeNet, ResNet, DenseNet, SENet
-
2016년 말 - 2018년:
AutoML을 이용해 Neural Architecture Search를 이용해 최적의 구조를 찾는데 집중
-
2018년 - 2019년 초중반:
AutoML에서 찾은 구조를 기반으로 하이퍼 파라미터 또는 각종 기법으로 추가를 하며 성능을 향상시킴
-
2019년 초중반:
수십억장의 web-scale extra labeled images등 무수히 많은 데이터를 잘 활용하여 ResNext로도 SOTA 달성
- Billion-scale semi-supervised learning for image classification (2019.05)
- Fixing the train-test resolution discrepancy (2019.06)
-
2019년 말: Labeled web-scale extra images대신 web-scale extra unlabeled images를 써서 self-training을 활용해 SOTA 달성
20년대에 이르러서도 Image Classification은 많은 연구자들이 성능을 향상시키려고 박차를 가하고 있습니다. 저는 다음에는 Object Detection을 다뤄보고자 합니다. Image Classification과 밀접한 관련을 가지고 있으므로 좋은 주제가 될 것 같습니다.
참고
[hoya012님 블로그] https://hoya012.github.io/blog/Self-training-with-Noisy-Student-improves-ImageNet-classification-Review/?fbclid=IwAR2Z3v3aBDS1Zc-UEG2YCdmrdlqJG3qn4_qubVoLYvJPjXNYZKsLklXTA1s
[캐글 cat vs dog] https://www.kaggle.com/c/dogs-vs-cats