Demand-based FTL
Introduction
안녕하세요?
저번 글에서는 flash에서 사용되는 FTL에 대하여 알아보았습니다.
Flash의 특수한 특성 때문에 성능 향상을 꾀하기 위해서는 FTL이라는 기법을 사용해야 하며, page 단위로 mapping table을 저장하는 page-level FTL과 block 단위로 mapping table을 저장하는 block-level FTL이 있으며 전자는 많은 메모리가 필요하다는 점, 후자는 속도가 느리다는 점이 단점이었습니다.
또, 둘을 적절히 섞은 Hybrid Mapping이라는 방법을 사용할 수 있으며, 이 경우 merge operation을 진행해주어야 한다는 점이 주요 특징이었습니다.
이번 글에서는 hybrid mapping을 조금 더 발전시킨 Demand-based FTL(DFTL)이라는 기법에 대해 소개해보겠습니다. DFTL은 간단한 아이디어만 적용했음에도 현재까지도 최고의 효율을 내는 FTL 중 하나로 평가받고 있습니다.
2009년 ASPLOS에 발표된 DFTL: A Flash Translation Layer Employing Demand-based Selective Caching of Page-level Address Mappings라는 논문을 리뷰하며, DFTL에 대해 알아보도록 하겠습니다.
Flash에 관심이 있으신 분이라면, 꼭 한번은 읽어보아야 할 정석과도 같은 논문입니다.
Architecture
DFTL은 page-level FTL을 사용하여 좋은 성능은 유지하였습니다. 동시에 page-level FTL의 단점인, mapping table을 저장하기 위한 많은 양의 메모리가 필요하다는 문제를 해결하였습니다.
해결 방법은 매우 간단한데, mapping table의 전체는 flash에 저장하고 일부만을 SRAM에 저장하여 requests가 올 때마다 동적으로 load 또는 unload를 하며 사용하는 간단한 방법을 사용하였습니다.
저장장치에 들어오는 requests 또한 결국은 같은 요청이 반복해서 들어오는, temporal locality가 굉장히 높기 때문에 이러한 특성을 최대한 사용하도록 설계되었습니다.
Mapping table의 크기는 page의 크기에 비하면 굉장히 작은 수준(0.2% 정도)이기 때문에, 이를 flash에 저장하는 것은 큰 오버헤드가 되지는 않습니다.
아래부터는 실제 data가 저장되어 있는 page를 data-page, mapping 정보를 저장하는 page를 translation-page라고 하고, translation-page로 구성된 block은 translation-block, data-page로 구성된 block은 data-block이라고 부르겠습니다.
Address Translation
Mapping table 중 SRAM에 저장된 부분을 CMT(Cached Mapping Table)라고, translation-page들의 주소를 저장하는 부분을 GTD(Global Translation Directory)라고 하겠습니다.
요청된 mapping information이 CMT에 존재할 경우, 그 정보를 이용해 바로 read/write를 수행하면 됩니다. 아주 간단합니다.
SRAM에 저장이 되어 있지 않을 경우, translation-page에 저장되어있는 mapping information을 CMT로 fetch해야 합니다. 이를 위해 CMT에 있던 하나의 mapping information을 victim으로 설정한 뒤 제거해야 합니다.
Victim이 SRAM에 fetch된 후로 아무런 변경이 없었다면 바로 제거하면 되지만, 변경이 있었다면 translation-page의 내용을 바꾸어주어야 하기 때문에 GTD가 가리키는 주소로 이동하여 page를 read, update, write하는 과정이 필요합니다.
이에 따른 성능 하락이 어느 정도인지를 계산해봅시다. CMT miss가 발생할 때마다 두 번의 page read, 한 번의 page write를 수행해야 합니다. 하지만 temporal locality가 충분하다면 CMT miss는 그리 자주 일어나지 않습니다.
Garbage Collection
Page-level FTL에서는 garbage collection(GC)을 진행주어야 합니다. 일반적으로는 victim block을 찾은 후 거기 있는 데이터를 다른 곳에 write한 뒤 erase를 해주면 되지만, DFTL은 translation-block의 존재 때문에 GC가 조금 더 까다로워집니다.
Write와 update가 계속 진행될수록 사용가능한 physical block의 개수는 줄어들게 됩니다. DFTL은 $GC_{threshold}$라는 값을 가지는데, 사용중인 physical block의 갯수가 이 값을 초과할 경우 GC를 진행한다.
어떠한 Block이 victim으로 설정되었을 때, 이 block이 translation-block인지 아니면 data-block인지에 따라 진행해주어야 할 것이 다릅니다.
첫째로 victim이 translation-block일 경우 valid page를 새로운 block에 copy한 뒤, GTD의 정보를 변경된 translation-page들의 주소로 변경해주면 됩니다.
반면, victim이 data-block일 경우 동작이 조금 더 복잡해집니다. 마찬가지로 Valid page를 새로운 block에 copy해주어야 하지만 이 경우 mapping table에서 대량으로 값 변경이 일어나기 때문에, 관련된 CMT와 translation-page들을 모두 바꾸어 주어야 합니다.
이 과정에 순간적으로 엄청나게 많은 시간이 소모되기 때문에, DFLT은 lazy copying과 batch updates라는 기법을 이용합니다. 사실 기법이라고까지 부르기는 힘들고, 정말 간단한 최적화입니다.
Lazy copying은 CMT에 존재하지 않는 address information의 변경을 조금 미루는 것입니다. SRAM의 수정은 빠르게 진행할 수 있지만 flash에 저장된 mapping information의 수정은 정말 많은 시간이 소요되므로 SRAM부터 수정하는 것이 합리적입니다.
이후 나중에 CMT에 저장되지 않은 address information을 변경하는데, 이 때 data-block에 속한 page들 중 같은 translation-page에 address information이 저장된 page들이 많이 존재하기 때문에 이를 한번에 수정해줄 수 있습니다. 이를 batch update라고 합니다.
이러한 기법들을 이용한 DFTL은 기존의 FTL scheme들에 비해 다음과 같은 이점을 가집니다.
-
Full Merge: 다른 FTL들은 full merge를 진행하며 많은 시간을 소모하지만, DFTL은 기본적으로 page level mapping이기 때문에 full merge를 할 필요성이 없습니다.
-
Partial Merge: DFTL은 같이 access되는 page들을 같은 physical block에 저장하기 때문에, 자동으로 hot block과 cold block을 나누게 되는 효과가 있으며, workload의 변경이 일어날 때 더 유연하게 적응 가능합니다.
-
Random Write Performance: 1번과 마찬가지로, DFTL은 full merge를 할 필요가 없기 때문에 random write performance 또한 훌륭합니다.
-
Block Utilization: 만약 working-set size가 flash size보다 훨씬 작을 경우, 기존의 FTL들은 update시 log block만을 사용하기 때문에 전체적인 utilization이 좋지 않지만 DFTL은 모든 block을 사용 가능하기 때문에 block utilization도 좋습니다.
Evaluation
Evaluation은 Financial, Cello99, TPC-H, Web Search 4가지 workload를 사용하여 진행하였습니다.
Financial는 금융 기관에서 사용하는 application, Cello99는 Time sharing server, TPC-H는 복잡한 database query를 처리하는 benchmark, Web Search는 web engine의 trace입니다.
성능 비교는 FAST, DFTL, Baseline 3가지 FTL을 비교하였습니다. FAST는 hybrid FTL로 기존의 state-of-the-art입니다. Baseline은 page level FTL을 나타내며, 가장 성능이 좋을 수밖에 없습니다.
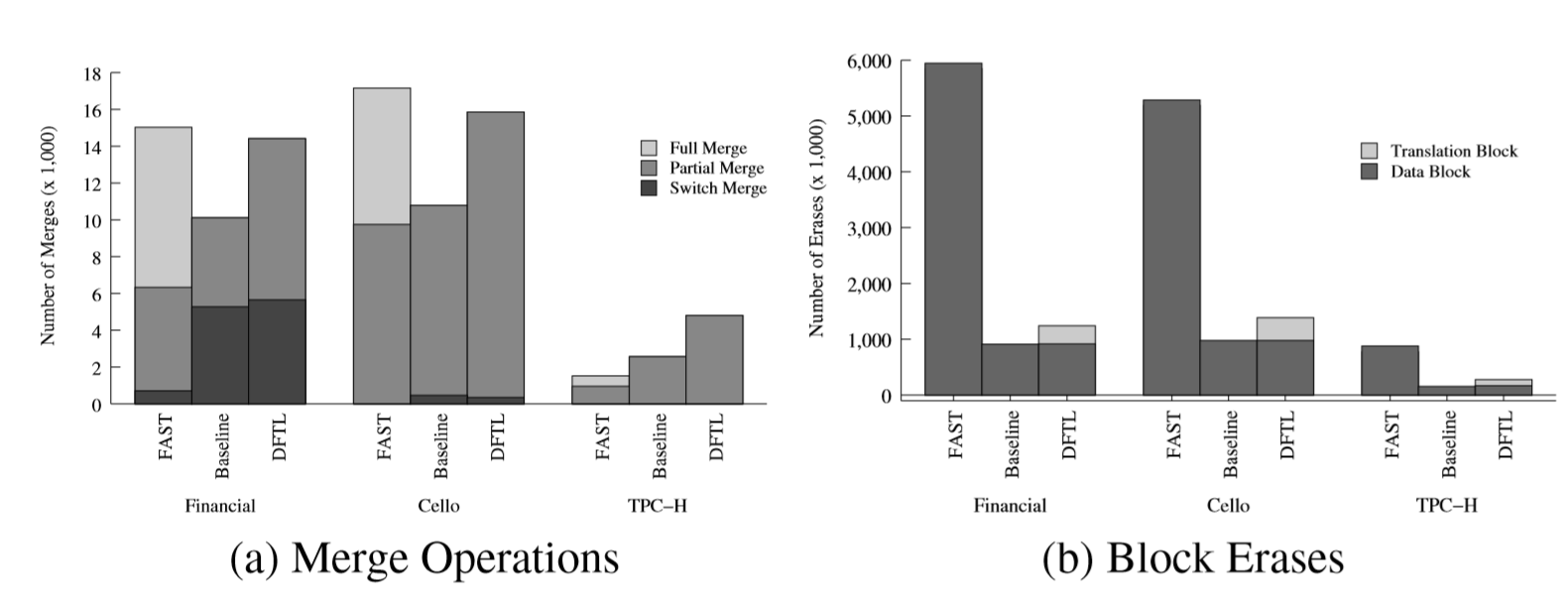
위 그림은 merge와 erase의 횟수를 나타낸 그림입니다. 먼저 switch merge를 보면, hybrid FTL은 블록 내 page가 연속해 있어야만 가능하다는 제약이 있었지만 DFTL은 그러한 제약이 없어 훨씬 더 많은 횟수가 발생하였습니다.
또한 DFTL은 비용이 비싼 full merge를 partial merge로 대체하게 됩니다. TPC-H workload를 보면, DFTL이 가장 많은 횟수의 merge를 발생시켰지만 대부분이 partial merge이므로 full merge가 있는 FAST보다 좋은 성능을 내게 됩니다. 오른쪽의 block erase 횟수는 더 적은 것을 확인할 수 있습니다.
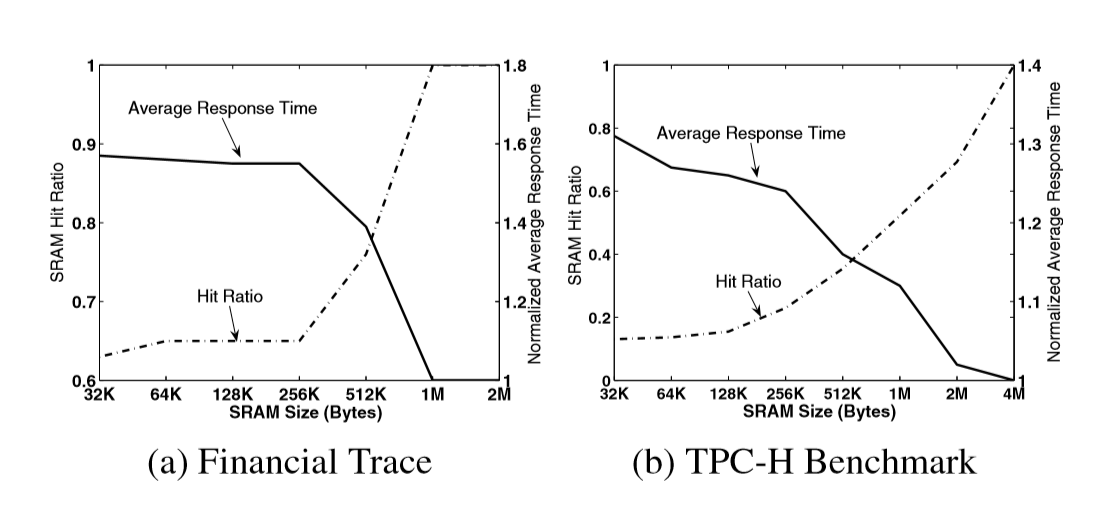
위 그림은 SRAM size에 따른 hit-ratio와 평균 응답시간을 나타낸 그래프입니다. SRAM size를 늘리면 당연하게도 성능이 향상된다. Minimal한 수준의 SRAM을 유지한다면 hit ratio는 temporal locality가 존재하는 financial trace에서는 63% 정도, locality가 적은 TPC-H에서는 20% 미만이었지만 SRAM size를 늘려줄수록 Hit ratio는 증가하고 average response time은 감소하는 것을 확인할 수 있습니다.
마치며
DFTL에 관한 내용은 어떠셨나요? 사실 논문에서 적용된 기법이 크게 새로울 것 없는 OS의 paging과 거의 유사한 방법이기 때문에 실망하신 분들도 계실 것 같습니다.
또, DFTL이 완벽한 해결책은 아닌 것을 누구나 쉽게 알 수 있습니다. 예컨대 항상 CMT miss가 나도록 workload를 worst하게 구성한다면 굉장히 낮은 성능을 보이게 만들 수 있습니다.
하지만 현실에서 flash를 정상적으로 사용할 때는 이러한 일은 거의 발생하지 않고, 그러한 이유에서 evaluation 또한 현실에서 구한 trace를 통해 측정하는 것을 확인할 수 있습니다.
수학적으로 우아한 것 해법이 아닌, 공학적인 관점에서의 접근이라 마음에 걸릴 수 있지만, 사실 완전한 답이 없는 문제의 경우 이런 식으로 일반적인 상황에서 잘 동작하도록만 해주어도 높은 성과로 볼 수 있다고 생각합니다.
지금까지 읽어주셔서 감사하며, 틀린 내용이나 질문이 있으시다면 sslktong@dgist.ac.kr로 연락주시기 바랍니다.
감사합니다.
아래는 글을 쓸 때 참고한 문서들입니다.