Deep Learning for Symbolic Mathematics
이번 글에서는 ICLR’20에서 spotlight accepted된 논문 Deep Learning for Symbolic Mathematics을 리뷰해보겠습니다.
Introduction
Symbolic Mathematics (혹은 symbolic computation)는 컴퓨터를 이용하여 기호로 표현된 다양한 수학적 대상들을 다루는 분야입니다. 예를 들어 $x + 1$ 과 $1 + x$ 가 동일한 식이라는 것을 컴퓨터가 자동으로 알아내거나 y에 대한 방정식 $x^2y - 2x + 4 = 0$을 기호 $x$를 이용해 정확하게 푸는 작업을 합니다. 과학 분야에서 주로 사용되는 Scientific Computing은 수치해석(numerical analysis)에 의존하여 approximation을 하지만, Symbolic Mathematics에서는 기호를 이용한 정확한 계산을 추구한다는 점이 근본적인 차이입니다. Mathematica, Maple, Wolframalpha 등이 이 분야에서 나온 대표적인 소프트웨어들이며 이렇게 symbolic mathematics를 지원하는 프로그램을 Computer Algebra System(CAS)라 부릅니다. 그러므로 만약 deep learning이 symbolic mathematics을 푼다면 기존의 CAS 프로그램들이 주요 비교대상이 될 것입니다.
Symbolic Mathematics에서 풀고자 하는 문제들이 많이 있지만 이 논문의 저자들은 다음 두 문제를 deep learning으로 해결하고자 했습니다.
- Symbolic integration - 부정적분 구하기
- Solving differential equation - 미분방정식 해 구하기
결과적으로 이 논문에서 제시된 방법으로 기존의 CAS 프로그램들 (Mathematica, Matlab)을 outperform 했는데 어떻게 해결하였는지 하나씩 살펴보겠습니다.
Representation
저자들은 먼저 주어진 식(expression)을 다음과 같이 tree 형태로 변환하였습니다.
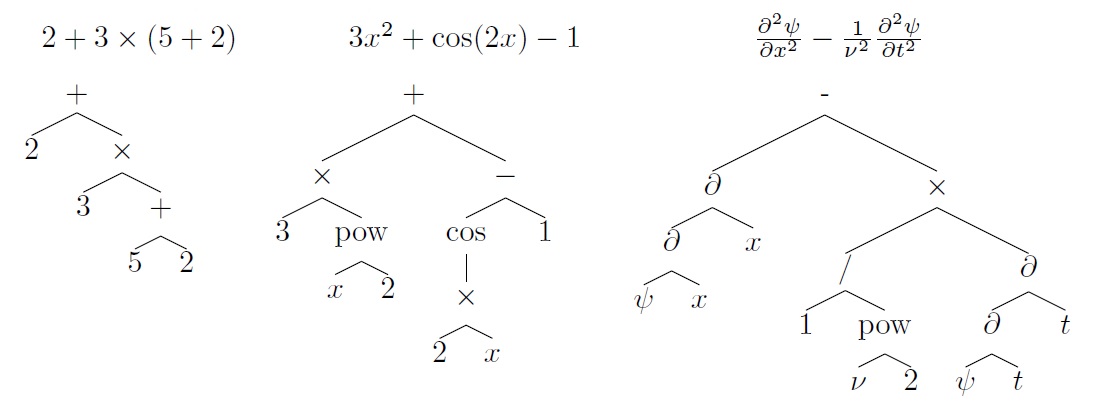
연산기호는 internal node에 숫자나 변수들은 leaf node에 위치함으로써 식의 계산 순서를 해치지 않고 정확하게 변환할 수 있습니다. 또한 이런 표현식의 장점은 불필요한 괄호를 없앨 수 있으며 또한 expression과 tree 사이에 일대일 대응이 성립한다는 점입니다.
다음으로는 변환된 tree를 전위순회하면서 다시 전위표현식의 형태로 바꾸었습니다. 예를 들어 $2+3\times(5+2)$ 는 $[+~2~\times~3~+~5~~2]$ 로 표현됩니다. 마찬가지로 tree와 전위표현식 사이에는 일대일 대응이 성립합니다. Sequence 형태로 바꾼 이유는 seq2seq 모델을 사용하기 위함이며, 중위나 후위표현식이 아니라 전위표현식으로 바꾼 이유는 전위표현식에서는 괄호가 필요없기 때문입니다. 따라서 모델이 학습할 때 complexity를 줄일 수 있습니다.
NLP architecture 중에는 tree에서 tree로 변환하는 Tree-RNN 도 있는데 저자는 seq2seq를 사용하였습니다. 저자의 설명에 따르면 tree-to-tree 모델이 seq2seq에 비해 많이 느리기 때문에 seq2seq를 사용하였다고 합니다. 하지만 tree-to-tree모델도 같이 실험해서 비교하면 더 좋았을 것 같은데 그 점은 아쉽습니다.
Dataset Generation
저자들은 Rubi(Rule-based Integration) 과 같은 공개된 데이터를 사용하지 않고 직접 데이터 셋을 만들어 냈습니다. 지금까지 공개된 데이터셋의 단점은 우선 데이터 수가 적고, Mathematica나 Matlab 등의 CAS 프로그램들이 풀지 못하는 데이터가 적다는 것입니다. 기존의 CAS 보다 성능을 높이려면 그들이 풀지 못하는 데이터가 필요합니다. 저자들은 직접 데이터를 만들어 냄으로써 상용 CAS 프로그램들이 풀지 못하는 데이터를 포함하여 총 4000만개에 해당하는 방대한 labeld data set을 구축했습니다.
Symbolic Integration Data Sets
적분 데이터셋은 다음과 같이 3가지 방법으로 구성하였습니다.
Forward Generation(FWD) Random tree를 생성하여 expression을 만들고 그것을 기존의 CAS 프로그램으로 적분하여 solution을 만듭니다. CAS 프로그램이 해결가능한 경우만 dataset에 포함됩니다.
Backward Generation(BWD) FWD의 단점을 극복하기 위해 solution에 해당하는 random tree를 먼저 만들고 그것을 미분하여 input expression을 만드는 방법입니다. 미분은 Sympy와 같은 library에서 rule-base로 정확하게 수행할 수 있습니다.
Backward Generation By Itegration By Parts(IBP) 하지만 BWD에도 단점은 있습니다. $f(x)=x^3 sin(x)$와 같이 간단한 함수들이 input으로 등장하는 경우가 매우 적게 됩니다. 왜냐하면 $f$의 적분은 $F(x)=-x^3 \cos(x) + 3x^2 \sin(x) + 6x \cos(x) -6 \sin(x)$ 로 random tree를 만들었을 때 나올 확률이 매우 작습니다. 즉, FWD는 input이 output에 비해 짧은 경향이 있지만 BWD는 input이 output에 비해 긴 경향이 있습니다. 이것을 해결하기 위해 부분적분(Integration by parts)으로 새로운 데이터를 만들 수 있습니다. $F$와 $G$를 random하게 만들고 그것의 미분 $f$와 $g$를 구합니다. 그러고 나서 만약 $fG$의 적분이 이미 dataset에 존재하면 다음과 같이 $Fg$의 적분도 구할 수 있습니다.$\int Fg = FG - \int fG$ $Fg$가 dataset에 있는 경우에도 마찬가지이며, 둘다 존재하지 않는 경우에는 단순히 $(f, F)$와 $(g, G)$를 dataset에 넣게 됩니다.
Differential Equation Data Sets
이 논문에서는 미분방정식 중에서도 1차, 2차 상미분방정식(Ordinary differential equation)에 초점을 맞추었습니다.
ODE1 미분방정식도 적분과 마찬가지로 backward generation으로 데이터를 만들었습니다. 다음 과정 처럼 만약 random하게 만들어낸 $y = f(x, c)$를 상수 $c$에 대해 풀 수 있으면 1차 상미분 방정식을 만들어 낼 수 있습니다.
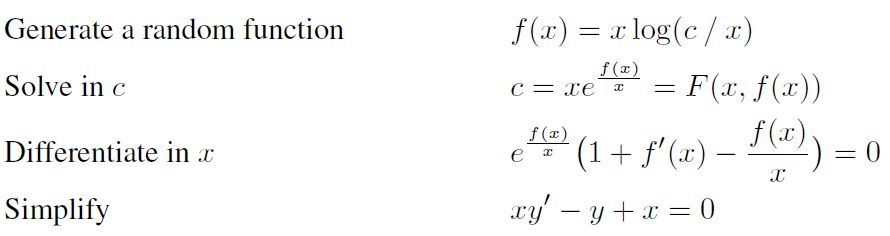
$c$에 대해 solvable한 $f$를 만들어내는 가장 간단한 방법은 random tree를 만든 후에 leaf node 하나를 상수 c로 바꾸는 것입니다. 그러면 그 leaf node를 기준으로 모든 연산을 역으로 취해주면 $c = F(x, y=f(x))$ 꼴의 식을 만들 수 있고 이를 $x$에 대해 미분해주면 미분방정식을 얻습니다.
ODE2 2차 상미분방정식도 비슷합니다. 마찬가지로 random tree를 만든 후에 상수 $c_1$과 $c_2$를 leaf node 하나 씩과 치환합니다. 다음 과정 처럼 식을 $c_2$와 $c_1$에 대해 풀어주면서 두번 미분을 해주면 2차 상미분 방정식을 얻을 수 있습니다.
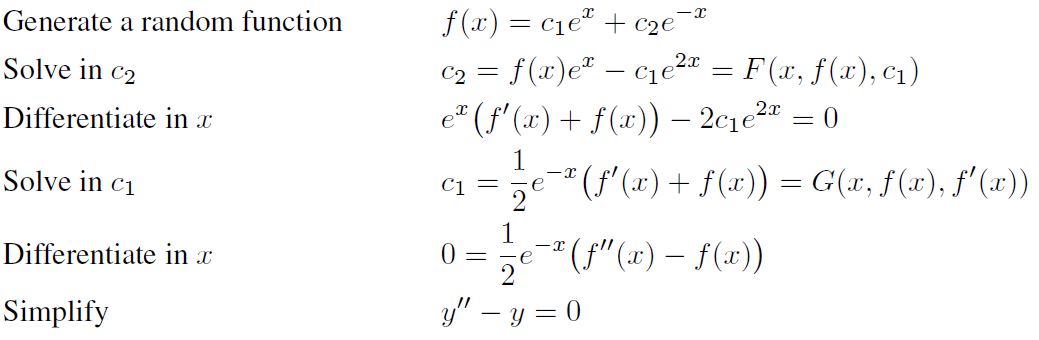
하지만 이 경우에는 $c_1$에 대한 solvability가 보장되지 않기 때문에 $c_1$에 대해 solvable한 경우에만 dataset을 만들 수 있습니다. 저자들의 주장에 따르면 random하게 만든 tree에서 실험결과 약 절반 정도 dataset을 만들 수 있었다고 합니다.
Dataset result
다음은 data generation에 사용된 숫자, 변수, 연산기호 들입니다.

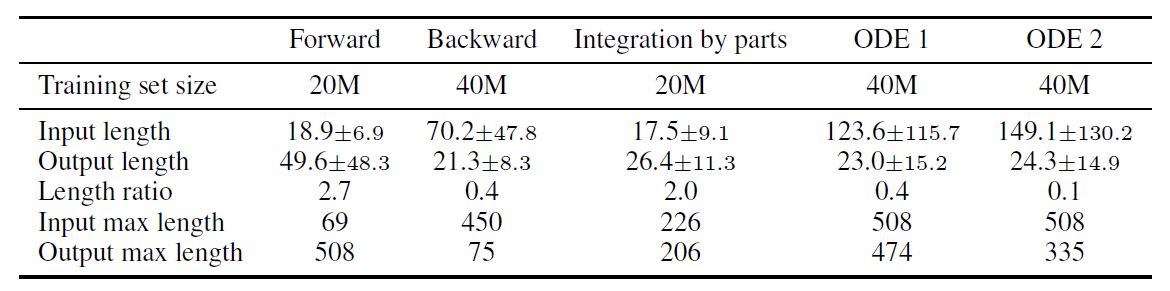
다음은 generated된 data의 크기와 input/output의 length를 비교한 표입니다. 위에 언급한 것처럼 backward 방식은 input이 길고, forward는 output이 긴 것을 볼 수 있습니다. 흥미롭게도 IBP(부분적분) 방식은 backward로 만들어냈음에도 불구하고 forward 처럼 output이 긴 것을 확인할 수 있습니다. 즉, IBP를 dataset에 포함시킴으로써 forward와 backward의 단점을 일부 커버할 수 있습니다.
Model
네트워크 아키텍쳐는 Attention Is All You Need에서 소개된 seq2seq 모델을 사용하였습니다. Attention은 seq2seq 모델의 성능을 크게 올려주는 기법으로 Cold Fusion에서도 간략히 소개된 바 있습니다. 기존의 seq2seq 모델은 input sequence를 context vector로 바꾸는 encoder와 context vector 하나를 받아서 output sequence로 바꾸는 decoder로 이루어져 있습니다. 하지만 Input이 길어짐에 따라 context vector로 부터 긴 output을 생성할 때 sequence의 local한 context를 prediction하기가 어려워집니다. 이를 해결하기 위한 개념이 attention이고, 이는 전체 sequence의 context를 볼 뿐만 아니라 local한 context를 볼 수 있게 해줍니다.
모델이 inference를 할 때는 beam search 기법을 사용했습니다. beam search는 attention과 마찬가지로 seq2seq 모델에서 자주 쓰이는 테크닉인데, output sequence의 각 문자를 차례로 만들 때 1개만 만들지 않고 score가 높은 top-k개를 계속 유지하며 최종 score가 높은 sequence를 선택하는 방법입니다. 이때 k를 1, 10, 50으로 바꿔가며 실험을 진행했습니다.
Seq2seq로 만든 output sequence가 전위표현식의 형태가 아니면 valid한 expression을 만들 수 없습니다. 이전 연관 논문에서는 이를 만족시키기 위해 여러 제한조건을 두었지만, 이 논문에서는 거의 대부분 valid한 경우였기 때문에 테스트단계에서 valid하지 않은 output은 단순히 잘못된 답으로 처리했습니다.
Result & Conclusion
다음 표는 위의 모델을 각 dataset으로 학습하여 얻은 test accuracy 결과입니다. Symbolic integration의 경우 beam size가 작아도 test accuracy가 상당히 높으며, ODE의 경우 beam size를 늘리자 test accuracy가 굉장히 높아졌습니다.

다음 표는 기존의 CAS 프로그램들과 BWD dataset에 대해 test accuracy를 비교한 표입니다. Symbolic integration과 differential equation 모두 BWD dataset에 대해서는 outperform 한 것을 볼 수 있습니다.
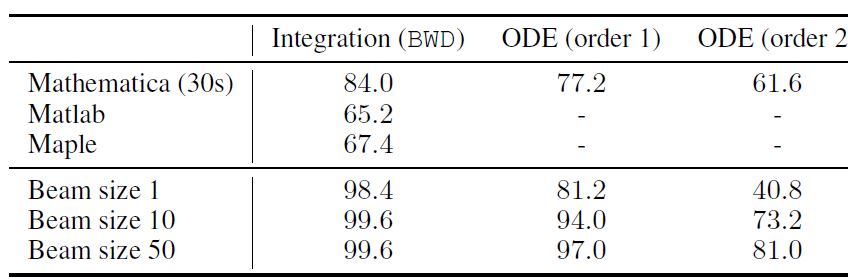
FWD의 경우에는 CAS의 test accuracy가 100%이므로 비교하는 것이 의미가 없지만, IBP 데이터에 대해서 비교를 안한 것은 살짝 아쉬운 부분입니다. 논문에 따르면 CAS와 비교를 할 때는 test set의 사이즈가 500밖에 안되는데, 그 이유가 mathematica가 solution을 구하는데 굉장히 오래걸리기도 하고 500인 경우와 5000인 경우에 accuracy에 큰 차이가 없어서 500으로도 충분하다는 것이 저자의 주장입니다. IBP는 이전에 구축된 데이터가 있어야 만들 수 있으므로, 이렇게 작은 test set에서는 실험을 하지 못한 것 같습니다.
그럼에도 불구하고 이 실험결과는 중요한 의미를 가집니다. Deep Learning이 적분과 미분방정식을 좋은 성능으로 해결할 수 있다는 것을 보여준 첫번째 논문이고, 더 나아가 Mathematica나 Matlab이 풀지 못하는 dataset과 그것을 충분히 해결할 수 있는 deep learning model을 만들었다는 점이 큰 contibution이라 보여집니다.
마무리
지금까지 Deep learning으로 symbolic mathematics를 좋은 성능으로 해결할 수 있다는 것을 보여준 논문을 리뷰해보았습니다. 리뷰하는 과정에서 몇몇 디테일은 생략하였는데 더 자세한 내용이 궁금하신 분은 아래 참조에서 원 논문을 읽어보시길 바랍니다. 감사합니다.