data science 매출분석
DataScience - 2
Contents
1. Review
2. Task
3. Data visualization
4. Data analysis
5. Predict
6. Conclusion
1. Review
이전 포스팅에서 데이터 사이언스가 어떤 주제인가를 다루었다.
실제로 매우 유명한 데이터셋을 가지고 데이터를 import 하는거에서 부터 plotting, check outlier 등
가장 기본적인 tool의 사용법을 익혔다. 유명한 데이터셋이기 때문에, 어떤 방법이 옳고 효율적인지를 직관적으로 이해할 수 없었다.
이번에는 좀 더 발전해서, 많이 접해보지 못했던 데이터셋에 대해서 어떻게 data 를 직관적으로 visualize 하고 analysis 할지를 알아보고자 한다.
2. Task
우선 이번에 다룰 data에 대해 설명하고자 한다.
설명하기 전에 데이터를 구하는 과정 또한 데이터 사이언스에서 매우 중요한 덕목이다.
Data scientist 들이 데이터분석을 하고자 할 때, 원하는 만큼의 데이터가 제공될 수도 아닐 수 도 있고,
그 데이터가 양질의 데이터일 수도 아니면 outlier 투성이일 수도 있다.
따라서 양질의 많은량의 데이터를 확보하는 것은 매우 중요한 문제로 다가온다. 이에대해서는 다음에 또 얘기해보도록 하겠다.
작성자가 구한 데이터는 free dataset이 아니어서 link를 통한 공개는 불가하지만 어느 곳에서나 접할 수 있고 쉽게 구할 수있다.
바로 상점의 매출정보이다. 상점의 매출정보로는 fix된 기간동안 여러개의 상점에 대해 실제 거래된 내역이 제공된다.
이런 data는 구글 free dataset에 검색을 해도 쉽게 나오는 data이므로 잘 찾아보길 권한다.
우리가 하고자 하는 목표는 상점의 거래내역정보를 통해서 미래 100일간의 매출을 예측하게 된다. 그 금액을 통해 그 상점의 미래 가치를 예측, 그 가치를 담보로 가치에 맞는 금액을 계산하여 대출을 진행하게되고, 실제 매출에 따른 기대 수익을 판별하고자 한다.
3. Data visualization
데이터를 visualize 하는 것에 대한 중요성은 이전 포스트의 data를 plotting하는 과정을 통해 설명했다.
데이터를 통해 어떤 작업을 하기전, data에 대한 이해가 필요하고 이를 가장 효율적으로 도와주는 것이 data visualize 라고 할 수 있다.
이번에 다루게 되는 dataset에 대해서 생각해보자, 주어진 dataset에는 상점id, 날짜, 시간, 금액, 할부개월, 휴일정보가 주어진다. 정작 매출 예측에 상점id, 날짜 또는 시간은 중요하지 않다. 따라서 데이터를 다음과 같이 가공해준다.
data = pd.read_csv('train.csv')
sub = data[['store_id', 'date', 'amount', 'installments','days_of_week','holyday']]
ss = sub[sub['store_id'] == 0]
위 코드로 ss dataFrame에는 store_id가 0인 store의 매출정보가 들어가게 된다.
다음으로 data를 살펴보면 같은 날에 여러건의 내역정보가 들어있는 것을 확인할 수 있다. 이들을 합쳐서 각 날짜별 매출의 정도를 파악하기 위해서 또 코드를 작성해준다.
ndata = pd.DataFrame(data = [[ss.loc[0]['date'], ss.loc[0]['amount']]], index = [0], columns = ['date', 'amount'])
cnt = 0
for idx, row in ss.iterrows():
if(flag == False):
flag = True
else:
if(row['date'] != bef['date']):
a = pd.DataFrame(data = [[row['date'],row['amount']]], index = [len(ndata.index)] , columns = ['date', 'amount'])
ndata = ndata.append(a)
#print(ndata)
else:
num = ndata.loc[len(ndata.index)-1,'amount'] + row['amount']
ndata.loc[len(ndata.index)-1, 'amount'] = num
#print(ndata)
bef = row
cnt = cnt + 1
print(ndata)
이제 ndata라는 DF에는 store_id가 0인 상점의 날짜별 매출 내역이 주어진다. 이제 이 매출내역을 그래프로 visualize 하여 살펴보자.
plt.plot(ndata['date'],ndata['amount'])
다음과 같은 그래프가 형성됨을 알 수 있다.
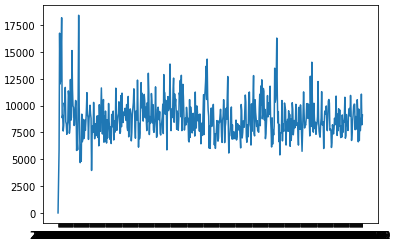
평균 10000 값을 유지하는 것을 쉽게 시각적으로 확인할 수 있다.
4. Data Analysis
그렇다면 이제 다른 feature들도 살펴보자. holyday 즉 휴일 feature를 집중적으로 살펴보자.
먼저 가공한 코드와 그 결과를 그래프로 나타낸 그림과 함께 설명해보겠다.
ss.head()
print(ss[ss['holyday'] == 1]['amount'].mean())
print("max : " ,ss[ss['holyday'] == 1]['amount'].max())
print("min : " ,ss[ss['holyday'] == 1]['amount'].min())
print(ss[ss['holyday'] == 0]['amount'].mean())
print("max : " ,ss[ss['holyday'] == 0]['amount'].max())
print("min : " ,ss[ss['holyday'] == 0]['amount'].min())
tt = ss[ss['holyday'] == 1]['amount']
# plt.boxplot(tt)
plt.subplot(1,2,1)
plt.hist(tt)
tt = ss[ss['holyday'] == 0]['amount']
plt.subplot(1,2,2)
plt.hist(tt)
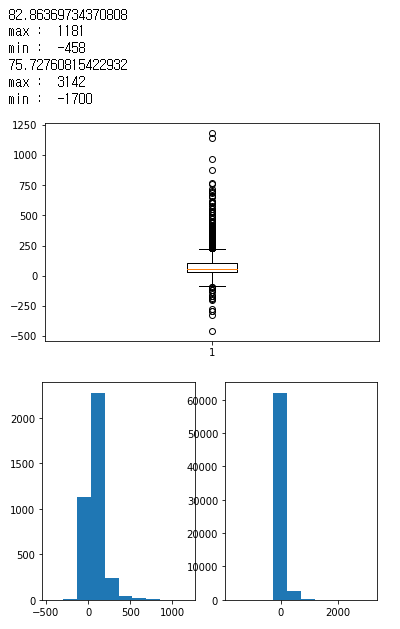
위에 표시한 값은 holyday 즉 휴일때 매출의 최댓값과 최솟값 그리고 평균값이다.
아래에 표시한 값은 휴일이 아닐때 매출의 최댓값과 최솟값 그리고 평균값이다.
수치상 확인할 수 있듯이 평균값에서 holyday 즉 휴일일 때 매출이 더 많았다는 점을 알 수 있다.
휴일에 따른 매출정보가 왜 중요한지 궁금할 수 있다. 우리가 구하고자 하는 미래의 매출값은 상점에 대한 수요와 공급에 영향을 받는다.
공급에 문제가 없는한 수요가 중요한데 즉 상점의 평균 매출이 중요하게 된다.
하지만 휴일에 사람이 많거나 적어서 평일보다 매출이 더 크게 나올 수 있고, 이를 같은 weight로 신경망에 집어넣게 될 경우에 잘못된 결과를 도출해낼 수 있다.
즉 보여지는 것처럼 휴일에 평균 매출이 크기 때문에 만약 평일 매출에 1의 weight를 주었다면 weight_holyday는 1보다 작은값을 주어야 할 것이다.
이제 feature에 대한 정보와 그 중요도를 책정하는 방법을 확인했다. 그렇다면 실제 매출액을 자세하게 분석해보자.
먼저 앞선 포스팅에서 data feature의 PCA를 구하는 과정을 간략하게 소개했다.
PCA 즉 주성분요소분석은 주성분요소를 구하는 것으로 시작된다. 이 때 주성분요소는 data들의 분산을 가장 잘 설명할 수 있는 요소들로 계산이되며
이 때 그 요소들을 우리는 eigen vector를 사용했었다. 이 때 나오는 eigen vector를 우리는 유심히 살펴보고자 한다.
eigen vector, eigen value 각각 고윳값 벡터, 고윳값 은 행렬로 표현된 data feature set을 어떤 선형변환이라고 생각할 때,
그 변환에 의해 방향은 보존되고 그 scale만 변화되는 고유 방향 벡터값을 의미한다. 즉 기존 변환행렬(feature set)의 크기가 N * M 이라고 가정할 때, m개의 feature에 대해 data들을 표현하게 된다.
이 때 고유벡터와 고윳값을 통해서 새로운 data feature들을 생성해 낼 수 있는 것이다.
수식적인 부분은 다음 포스팅에서 STL 분해(Seasonal and Trend decomposition) 의 수학적 이해와 함께 설명을 하고
실제 python에서 고윳값과 고윳값 벡터를 구하는 방법을 살펴보자.
import numpy as np
print(ndata.head())
XX = x[:,0:1].detach().numpy()
print(XX.shape)
YY = np.array([ndata['amount'], ndata['holyday'] * model.weight.data.numpy()[0][1]])
ZZ = y.detach().numpy()
ZZ = ZZ.reshape(591,1)
print(YY.shape)
U, s, Vt = np.linalg.svd(YY,full_matrices = False)
np.diag(s)
U = U.dot(np.diag(s)).dot(Vt)
plt.figure()
ZZ = ZZ.reshape(1,591)
T = U[0] - ZZ
T = T.reshape(591,1)
#plt.plot(XX,T)
plt.plot(XX[1:50],U[0][1:50],'b')
ZZ = ZZ.reshape(591,1)
plt.plot(XX[1:50],ZZ[1:50],'r')
위 코드에서 U, s, Vt = np.linalg.svd(YY,full_matrices = False) 부분이 고윳값, 고유벡터를 구하는 부분으로 numpy에서 라이브러리를 제공한다.
주요하다고 생각하는 amount 와 holyday를 가지고 진행하였고 고윳값벡터로 표현된 매출 변화도는 파란색으로, 기존 메출변화를 빨강색으로 표시했다.
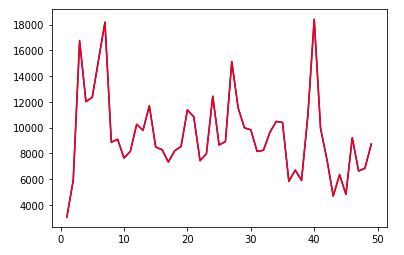
차이가 없어보이지만 plt.plot(XX,T) 부분을 실행하게 되면 T에는 두 매출변화도의 값 차이를 그래프로 나타낸 것으로 다음과 같이 변화가 있는 것을 확인할 수 있다.
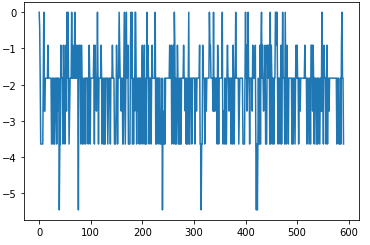
YY 를 선언하는 위치에서 model.weight.data.numpy()[0][1]을 holyday feature값에 곱하는 부분이 있다.
이를 통해서 T에서 나타나는 변화차이가 더 뚜렷해지는 것을 확인할 수 있는데, 기존에는 holyday값이 0 or 1 뿐이므로, 사실 amount 값에 비해
중요한 feature로 계산상 해석되기 힘들다. 따라서 가중치값을 곱해주었다.
사실 정규화를 한 값에서 출발하는 것도 한 방법이지만, linear regression 학습을 통해서 가중치값을 구해 곱하는 방식을 선택해보았고,
간단한 linear regression 코드는 다음과 같다.
q = np.arange(len(ndata.index)).reshape((len(ndata.index), 1))
tmp = np.array(ndata['holyday']).reshape(591,1)
q = np.append(q, tmp, axis = 1)
x = torch.tensor(q,dtype=torch.float64,requires_grad= True)
y = torch.tensor(ndata['amount'].values , dtype=torch.float64, requires_grad = True)
from torch import nn
model = nn.Linear(in_features=2, out_features=1, bias=True)
model.double()
criterion = nn.MSELoss()
optimizer = torch.optim.Adam(params=model.parameters(), lr=0.1)
for step in range(2000):
prediction = model(x)
loss = criterion(input=prediction, target=y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if step % 100 == 0:
print(step)
pass
prediction = model(x)
loss = criterion(input=prediction, target=y)
plt.clf()
plt.xlim(0, 591)
plt.ylim(0, 20000)
plt.scatter(x[:,0:1].data.numpy(), y.data.numpy())
plt.plot(x.data.numpy(), prediction.data.numpy(), 'b--')
print(loss)
print(model.weight)
plt.show()
다음은 linear regression 의 결과이다.
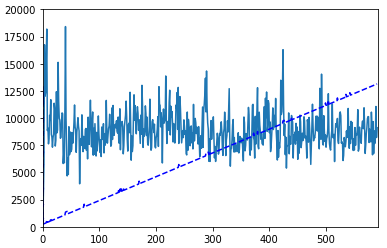
이는 SVD의 효율성을 증가시킨것을 실제로 확인할 수 있다.
그렇다면 SVD는 왜 사용할까? 우리는 PCA로 요소들을 분석할 때, PCA가 기존 feaure들보다 더 data들을 잘 나타내기 때문이다
우리는 날짜별 매출현황을 알고 싶지만, holyday란 요소의 중요도에 따라 그 요소가 가미된 정보를 보고자 한다.
3차원 plot으로 보여주게 될 경우 우리는 사실상 그 주요도를 확인할 수 없다. 따라서 holyday에 영향을 받은 새로운 요소들을 구해서
날짜별 매출현황을 더 깔끔하고 부드럽게 보여줄 수 있는 것이다.
feature 의 개수가 많거나 그 feature가 실제 amount값에 영향을 많이 끼칠 수록 그래프의 변화도는 더 커질 것을 알 수 있다.
5. predict
이제 매출 예측을 진행해 보자. 매출 예측은 ETS 모델을 통해서 예측해보았다. ETS 모델의 소개와 수식적인 부분또한 다음에 다루도록 하고
실제 ETS의 구현을 살펴보겠다. 기존의 data를 R에 import 해서 사용하였고 우선 코드부터 살펴보자
library(xts)
library(forecast)
x <- read.csv("filename.csv")
class(x$Date)
x$Date = as.Date(x$Date,format="%d/%m/%Y")
x = xts(x=x$Amount, order.by=x$Date)
x.ts = ts(x, freq=365, start=c(2016, 349))
plot(forecast(ets(x.ts), 100))
R답게 패키지로 모든 것이 해결가능하다. 중간에 x$Date를 date형으로 변경시키기 위해 as.Date() 가 사용되는데,
이 때 format = “%d/%m/%Y” 로 되어 있는 것을 확인할 수 있을것이다. 위의 python코드에서 아래에 다음 코드를 추가해주면 된다.
print(ndata.shape)
ho = pd.DataFrame({"date":ndata['date'], "amount":ndata['amount']})
po = pd.DataFrame()
from dateutil.parser import parse
for idx, row in ho.iterrows():
dt = parse(row['date'])
#print(dt.strftime('%d/%m/%Y'))
a = pd.DataFrame(data = [[dt.strftime('%d/%m/%Y'),row['amount']]], columns = ['Date', 'Amount'])
po = po.append(a)
print(po)
po.to_csv("filename.csv", index=False, mode='w')
이 작업을 해주는 이유는 R의 경우에 지원되는 format이 정해져 있고, feature(Header)의 첫글자가 대문자가 아닌 경우 class를 잘 인식 못할 경우가 발생한다.
따라서 이를 변경해주는 작업을 거쳤다.
이제 위의 R코드의 결과를 확인해보자.
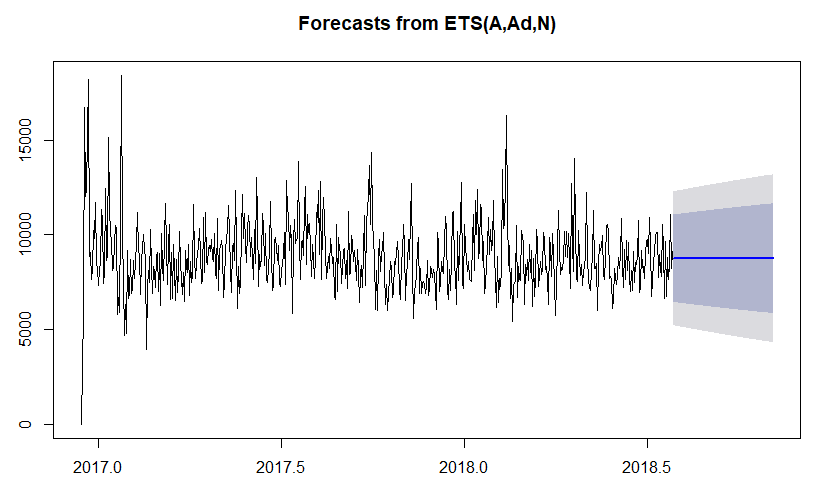 보여지는 Boundary는 예측된 값의 오차 범위를 의미한다. 결과가 보다 직관적이지 못함을 알 수 있다.
보여지는 Boundary는 예측된 값의 오차 범위를 의미한다. 결과가 보다 직관적이지 못함을 알 수 있다.
ETS예측에는 ARIMA Seasonal, ARIMA Non Seasonal, AVERAGE SEASONAL ETS AND ARIMA , ETS Seasonal, ETS Non Seasonal 5가지 방법이 있다.
자세한 내용은 다음 포스팅에서 다루기로 하고 이를 우리는 Microsoft Azure에서 제공되는 ML toolkit을 이용할 수 있다.
Microsoft Azure ML ETS forecast.
앞선 R 코드에서 추출된 CSV파일을 추가만해주면 된다. 실행한 결과 5개알고리즘에 대해서 모두 예측값을 보여주고 그 예측값은 다음과 같다.
Visualize 한 결과는 다음과 같다.
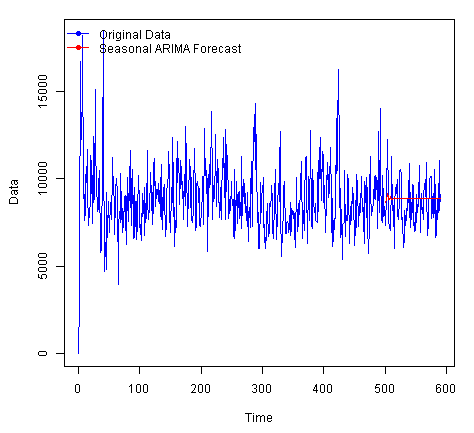
앞선 R코드에서 예측한 결과보다 좀더 앞부분에 detail한 결과를 얻을 수 있다.
하지만 생각보다 우리가 원하는 결과가 아님을 알 수 있는데 이는 ETS 예측자체가 시계열 데이터에 대해서 연도별 또는 계절별 구간의 변화를 파악해서 예측하는 것이어서, 구간의 특징이 없거나, 약한 경우 좋은 결과를 예측하지 못할 수 있다.
6. Conclusion
이번 포스팅에서는 상점의 매출데이터를 바탕으로 앞으로의 매출을 예측하는 데이터 분석을 진행했다. 원하는 퀄리티의 예측값을 얻진 못했지만 데이터과학 분야에 있어서 여러 접근방법을 배우는 좋은 기회였다.
데이터를 찾는 과정부터 시작해서 그래프를 통해 데이터를 이해하고 이상치나 잡음을 체크하는 작업을 가졌다. 그리고 데이터 분석과정에서는 고윳값 분해를 통해서 데이터의 주요한 feature를 골라내었고, 각 feature가 가지는 영향력을 확인했다.
예측 과정에서는 앞선 선형회귀 방식도 사용해 보았고, ETS 모델을 이용해서 예측을 진행했다. ETS 모델의 경우 지수평활법을 기반으로 시간의 흐름에 따른 분석을 통해 예측을 진행한다.
이번에 다루지 못한 STL 데이터 분해와 ETS 모델의 원리는 다음에 파악해보고, 매출액 data 들을 더 제대로 살펴보는 시간을 가져보겠다.