Kudeki Chain과 CUDA Programming
목차
- 개요
- Data Parallelism
- GPU 구조
- Kudeki Chain 문제 설명
- CUDA 프로그래밍 방법
- 최종 코드
- 마무리
- 참고 자료
개요
몇 달 전에 Kudeki Chain이라는 문제를 GPU를 사용해서 풀어보았다. 풀이를 간략하게 정리해서 개인 블로그에 포스팅을 했는데, 생각보다 GPU에 관심있는 독자가 많았다. 그래서 이번에는 GPU와 CUDA 프로그래밍에 대해 포스팅을 작성하여 내용을 공유하고자 한다.
Data Parallelism
Data Parallelism은 다른 데이터들에 대해 동일한 연산을 한 번에 계산하여 프로그램의 실행 시간을 줄이는 방법이다. 배열 A와 B를 더하고, 그 결과를 배열 C에 저장하는 프로그램을 예시로 생각해보자.
for(int i = 0; i < 1024; i++) c[i] = a[i] + b[i];
위 프로그램은 덧셈을 총 1024번 수행하기 때문에, 단일 CPU로는 1024번의 연산을 해야 한다. 이제 CPU가 1024개 있다고 해보자. 0번 CPU에는 a[0]과 b[0], 1번 CPU에는 a[1]과 b[1], … 1023번 CPU에는 a[1023]과 b[1023]의 값을 저장한다. 다음에 모든 CPU가 저장된 두 값을 더하고, 그 값을 배열 c에 저장한다. 이 방법대로 하면 덧셈 한 번을 할 정도의 시간만으로 크기 1024짜리 배열 2개를 더할 수 있다.
위와 같이, 서로 다른 데이터들에 같은 연산을 적용하는 방법을 Data Parallelism이라고 한다. 이 방법은 매우 많은 곳에 사용될 수 있다. 위와 같이 크기가 큰 배열에 같은 연산을 동시에 계산하는 경우나, 행렬 곱셈과 같이 동일한 연산을 다른 데이터에 대해 반복적으로 계산하는 경우가 그 예시이다. 특히 Deep Learning은 Data Parallelism을 사용하여 연산 시간을 대폭 줄일 수 있기 때문에, Data Parallelism에 사용되는 부품인 GPU는 Deep Learning을 빠르게 하기 위해 반드시 필요하다.
GPU 구조
GPU는 Data Parallelism을 효율적으로 하기 위한 부품이다. GPU는 내부에 1천개가 넘는 연산 장치가 있다. CUDA에서 각 연산 장치는 cuda core라고 불린다. 한 번의 연산을 할 때, 계산할 연산을 여러 개의 cuda core에 전송하는 것으로 연산을 수행한다. 예를 들어 GPU에서 배열 a와 b를 더하기 위해서는, a[i]와 b[i]를 i번째 cuda core의 레지스터에 저장한 뒤, 덧셈 연산을 모든 cuda core에 전송해 덧셈 연산을 수행하고, 그 값을 배열 c에 저장하는 것으로 이루어진다.
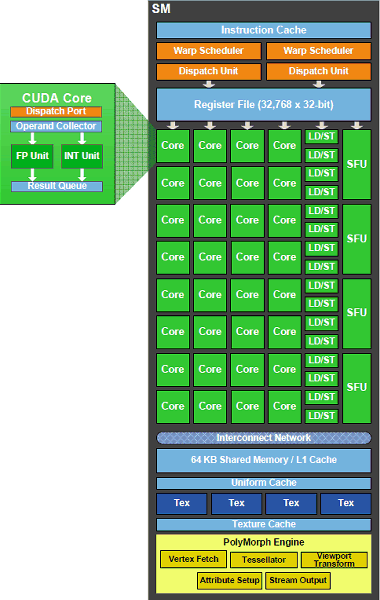
GPU의 cuda core들은 streaming multiprocessor(SM) 단위로 군집화 되어있다. 일반적으로 SM에는 32개의 cuda core가 있지만, GPU마다 그 개수는 다를 수 있다.. SM 내부의 cuda core들은 동일한 연산을 수행할 수 있게 설계되었기 때문에, 한 SM는 두 개 이상의 프로세스를 동시에 실행할 수 없다.
아래 그림은 GPU의 구조와 SM의 구조를 간략하게 표현한 것이다.
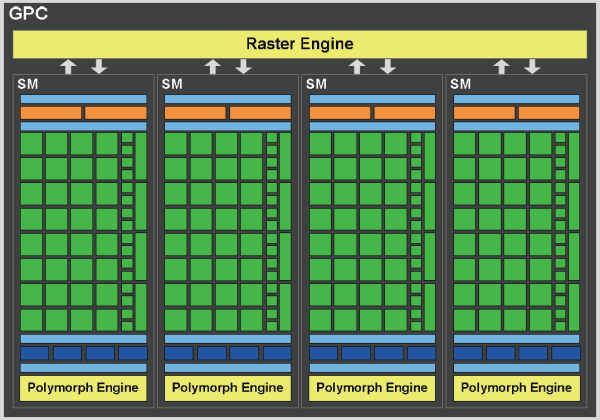
GPU에 작업을 전달할 때는 코드와, 해당 작업에서 필요로 하는 cuda core의 수, 그리고 한 block에 포함되어야 하는 cuda core의 수를 전달하게 된다. GPU에서는 프로세스에서 요청한 cuda core의 수를 처리할 수 있을 만큼의 SM을 배정하여 연산을 수행한다. 연산은 block 단위로 계산되기 때문에, block의 수에는 제한이 없으나 한 block에 포함되어야 하는 cuda core의 수는 GPU에 있는 cuda core의 수를 넘을 수 없다.
만약 한 block에 포함되어야 하는 cuda core의 개수가 32의 배수가 아닌 경우, cuda core의 개수가 SM의 cuda core 개수의 배수가 되도록 배정하게 된다. 이와 같이 배정을 위한 cuda core의 개수 단위를 warp라고 한다.
GPU에 있는 메모리에는 local memory, shared memory, register가 있다. Local memory는 모든 SM과, 연산을 하기 위한 CPU에서 접근할 수 있는 memory이다. Shared memory는 한 block에서만 참조할 수 있는 memory이다. Register는 한 cuda core에서만 참조할 수 있는 memory이다. CPU의 메모리 구조와 비슷하게, Local memory, Shared memory, register 순으로 메모리 참조 속도가 빨라진다.
프로그래밍 관점은 CPU에서의 multi thread programming과 유사한 점이 많다. 프로그램은 block 단위로 실행되며, block 내부에 있는 cuda core의 수만큼 thread를 동시에 실행한다. 또한 Block 내부의 thread들은 shared memory를 공유하여 사용할 수 있으며, shared memory를 읽고 쓸 때 racing condition이 생길 수 있다. 차이점으로는 GPU는 모든 thread가 동시에 동일한 연산을 한다는 것이 있다.
추가 내용으로, GPU에서 if-else 조건문을 추가할 수 있으며, 이 경우 특이한 방식으로 실행된다. GPU의 thread들 중 if문을 만족하는 thread와 만족하지 않는 thread가 모두 존재하는 경우 두 조건문을 둘 다 실행한다. if문을 실행할 때는 조건을 만족하지 않는 thread는 stall시키고, else문을 실행할 때는 조건을 만족하는 thread를 stall시키는 것으로 코드를 실행할 수 있다. 하지만, if문을 만족하는 thread만 있다면 if문만 실행시키며, 그 반대도 마찬가지이다. 때문에 thread의 실행 경로가 달라지면 비효율적인 코드가 될 수 있다.
Kudeki Chain 문제 설명
Git에는 각 commit을 구분하기 위한 hash값이 있다. 이 hash값은 commit message에 영향을 받기 때문에 message를 수정하여 hash값을 수정할 수 있다. Kudeki Chain에서는 message를 수정하여 hash값의 앞 n자리가 0이 되게 만들어야 한다. 참고로, 이 내용은 block chain에서 사용되는 hash puzzle과 내용이 비슷하다.
이 문제는 Data Parallelism으로 쉽게 해결이 가능하다. 먼저 서로 다른 message를 서로 다른 cuda core에 저장한 뒤, 각 cuda core에서 저장된 message의 hash값을 계산하여 앞 n자리가 0이 되는지 확인하면 된다.
CUDA 프로그래밍 방법
GPU에 올라갈 코드는 기본적으로 C 문법과 동일하며, 함수의 제일 앞에 __global__을 추가하여 GPU에 사용되는 코드라는 것을 알려줄 수 있다. 현재 thread의 block ID는 blockIdx에 저장되어 있고, block 내에서 thread 번호는 threadIdx에 저장되어 있다. 구현의 편리함을 위해 block과 thread 번호를 다차원으로 지정할 수 있다.
코드를 GPU에서 실행시키기 위해 먼저 block 개수와 thread 개수를 정의해야 한다. CUDA에는 dim3이라는 자료형이 있으며, block 개수와 thread 개수를 이 자료형으로 선언하면 된다. 여기서는 4096 x 4096개의 block과, 각 블록 당 256개의 thread를 만들 것이고, 이를 위해 다음과 같이 선언하였다.
dim3 threadsPerBlock(256, 1);
dim3 numBlocks(4096, 4096);
GPU에서 local memory를 사용하기 위해서는 메모리 할당을 먼저 하여야 한다. 이를 위해 cudaMalloc이라는 함수를 이용하여 메모리를 할당하였다. Unsigned long long 크기의 메모리를 GPU에 할당하는 코드는 아래와 같다.
ull* res
cudaMalloc(&res, sizeof(ull));
sha1_kernel 함수를 실행하는 방식은 다음과 같다. 여기서는 위에서 설명한 것과 같은 block과thread 개수를 사용하여 함수를 호출한다. 인자는 C언어와 같은 방식으로 넣어주면 된다.
sha1_kernel<<<numBlocks, threadsPerBlock>>> \
(res, i, hash.h0, hash.h1, hash.h2, hash.h3, hash.h4, hash.nbits);
GPU에서 값을 가져오는 것 또한 함수를 사용하여야 한다. sha1_kernel 함수는 값을 찾은 경우 res 위치에 메시지를 저장하는데, 이 위치는 GPU에 저장되어 있기 때문에 CPU로 값을 복사할 필요가 있다. 이를 위해 다음과 같은 코드를 추가하였다.
cudaMemcpy(&res_copy, res, sizeof(ull), cudaMemcpyDeviceToHost);
나머지 부분은 sha1의 해쉬값을 구하는 부분이며, 이는 C언어와 완벽하게 일치하기 때문에 생략하였다.
# 최종 코드
코드는 아래 url에서 확인할 수 있다. https://github.com/zigui-ps/githashjoke/blob/master/sha1_cuda.cu
마무리
이 문제에서는 shared memory를 사용하지 않기 때문에 최적화를 하는 노력 없이 구현할 수 있었다. 하지만 shared memory를 사용할 경우 최적화가 간단하게 되지 않는데, 하드웨어의 제한 때문에 같은 SM에 포함된 2개의 thread가 동시에 local memory에 접근할 수 없거나, shared memory의 크기 제한 등등 많은 것들을 고려해야 한다. 때문에 행렬 곱셈과 같은 경우 최적화 여부에 따라 성능 차이가 많이 날 수 있다.
본 문제 코드는 sha1 해쉬 함수값을 구하는 부분 때문에 코드가 길어졌으며, 때문에 CUDA를 처음 접하는 사람은 다른 튜토리얼을 보며 공부하는 것을 추천한다.
참고 자료
- Basic Concepts in GPU Computing https://medium.com/@smallfishbigsea/basic-concepts-in-gpu-computing-3388710e9239
-
An Even Easier Introduction to CUDA https://devblogs.nvidia.com/even-easier-introduction-cuda/
- http://ixbtlabs.com/articles3/video/gf100-2-p2.html