Audio rendering in web
HTML Video 태그를 대신 할 비디오 플레이어를 웹 기술을 통해 만든다고 상상해보세요. 영상을 재생하기 위해서는 두 가지가 필요하죠. 비디오 렌더링과 오디오 렌더링입니다.
비디오 렌더링을 위해서는 HTML Canvas API를 사용하면 될 것 같고, 오디오 렌더링을 위해서는 Web Audio API를 사용하면 될 것 같습니다. (영상 디코딩은 이미 끝났다고 가정하죠. 편의상 이미 디코딩된 영상 데이터를 서버로부터 스트리밍 받고 있다고 생각합시다. 현재의 네트워크 기술로는 허무맹랑한 이야기지만요.)
이전 포스트에서 Offscreen Canvas라는 API를 언급한 적이 있습니다. 웹 상에서 무거운 그래픽 렌더링 작업을 하기 위해 별도의 쓰레드에서 기존 HTML Canvas를 사용할 수 있도록 해주는 기술이죠. Offscreen Canvas를 사용하면 렌더링이 별도의 쓰레드에서 실행되므로 메인 쓰레드, 즉 UI 쓰레드에 의해 렌더링이 지연되거나, 렌더링에 의해 UI 쓰레드가 지연되는 상황을 없앨 수 있습니다. 싱글 쓰레드를 사용하던 웹의 고전적인 한계를 타파할 수 있게 된 것이죠. 비디오 렌더링을 위해서 이 API를 사용하면 될 것 같습니다.
비디오 렌더링 얘기는 짧게 끝내고, 오디오 렌더링으로 넘어가보죠. 이 포스트에서 이야기하고자 하는것은 오디오 렌더링이니까요. 서버로부터 스트리밍 받아 들어오는 RAW 오디오 데이터(디코딩된 오디오 데이터)를 오디오로 재생시켜야 합니다. 앞서 언급한 것 처럼 웹에서는 오디오 재생을 위한 Web Audio API 를 제공하고 있습니다. Web Audio API 아래에 존재하는 여러가지 하위 API 중 우리가 원하는 기능을 제공하는 API는 ScriptProcessorNode입니다. ScriptProcessorNode는 코드를 통해 직접 특정 버퍼에 오디오 데이터를 지속적으로 스트리밍해주면, 브라우저가 해당 데이터를 재생할 수 있도록 해주는 API입니다. 생성된 ScriptProcessorNode는 주기적으로 onaudioprocess라는 함수를 호출하고, 개발자는 해당 함수 내에서 버퍼에 데이터를 채워주면 됩니다. Mozilla에서 제공해주는 샘플 코드를 보면 다음과 같습니다.
// Give the node a function to process audio events
scriptNode.onaudioprocess = function(audioProcessingEvent) {
// The input buffer is the song we loaded earlier
var inputBuffer = audioProcessingEvent.inputBuffer;
// The output buffer contains the samples that will be modified and played
var outputBuffer = audioProcessingEvent.outputBuffer;
// Loop through the output channels (in this case there is only one)
for (var channel = 0; channel < outputBuffer.numberOfChannels; channel++) {
var inputData = inputBuffer.getChannelData(channel);
var outputData = outputBuffer.getChannelData(channel);
// Loop through the 4096 samples
for (var sample = 0; sample < inputBuffer.length; sample++) {
// make output equal to the same as the input
outputData[sample] = inputData[sample];
// add noise to each output sample
outputData[sample] += ((Math.random() * 2) - 1) * 0.2;
}
}
}
오디오 렌더링도 굉장히 쉽게 구현할 수 있을 것 같네요. 콜백 함수 내에서 스트리밍 받은 데이터를 그대로 채워주기만 하면 되니까요. 끝난건가요?
ScriptProcessorNode의 문제는 HTML Canvas처럼 메인 쓰레드에서 실행된다는 것 입니다. 이는 굉장히 큰 문제로 다가옵니다. 비디오 플레이어를 생각해보세요. 비디오 플레이어는 기본적으로 3가지 기능을 가지고 있습니다. 재생, 정지, 그리고 탐색 입니다. 여러분이 가지고 있는 아무 비디오 플레이어를 실행시켜서 영상을 재생하고, 원하는 시간으로 탐색을 해보세요. 특정 시간으로 탐색을 요청하면, 비디오 플레이어는 즉각적으로 해당 시간에 맞는 비디오와 오디오를 렌더링할 겁니다.
우리가 브라우저에게 재생될 오디오 데이터를 제공하는 시점은 audioprocess 가 호출되는 시점입니다. audioprocess가 호출되면, 출력 버퍼에 데이터를 제공하고, 함수를 끝냅니다. 그럼 브라우저는 해당 출력 데이터를 받아서 버퍼에 담긴 데이터를 모두 오디오로 재생하고, 오디오 재생이 끝나면 다시 audioprocess가 호출됩니다. 이 과정이 계속 반복됨으로써, 오디오가 연속적으로 재생되게 됩니다.
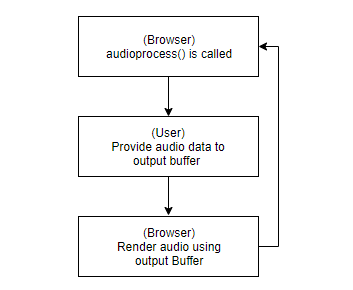
여기서 첫 번째 치명적인 문제가 발생합니다. 사용자가 오디오를 제공할 수 있는 시점은 audioprocess가 호출되는 시점이므로, 사용자의 탐색에 의해 영상이 다른 시간대로 이동했다고 하더라도 아직 이전 audioprocess 에서 제공된 데이터의 재생이 끝나지 않았다면, 탐색 전 시간대의 오디오가 계속해서 렌더링 되게 됩니다. 이전 데이터가 모두 렌더링 되고 나서야, 다시 audioprocess 함수가 호출되고, 비로소 현재 싱크에 맞는 오디오 데이터가 제공될 수 있게 됩니다.
이 문제를 해결하려면, audioprocess 내에서 처리되는 버퍼의 사이즈를 줄이면 됩니다. ScriptProcessorNode를 생성할 때 한 번 audioprocess할 떄 마다 어느 만큼의 크기의 버퍼를 처리할 지 2의 n승이 되는 256 ~ 16384 사이의 크기 중 설정할 수 있습니다. 예를 들어 버퍼의 사이즈가 4096이라면, 44.1Khz 의 주파수를 가지는 오디오 데이터 기준으로 한 번 audioprocess가 호출될 때 마다 4096 / 441000 = 0.092초 시간에 해당하는 오디오를 렌더링하게 된다는 뜻입니다.
버퍼 사이즈가 작으면 작을수록, 탐색이 요청된 시간대를 재생할 때 까지의 딜레이, 즉 latency를 줄일 수 있을 것입니다. 최소 버퍼 사이즈가 256이니, 256 / 44100 = 0.0058초까지 줄일 수 있겠군요. 이걸로 모든게 해결된 걸까요?
0.0058초마다 audioprocess가 호출된다는 것은, 다르게 이야기하면 5.8ms초마다 audioprocess가 호출되지 못하면 해당 시간대에 오디오는 렌더링되지 못한다는 뜻입니다. 0.0058초 정도 빠졌다고 해서 상관없다고 생각할 수 있겠지만, 오디오에게 있어서는 아닙니다. 오디오는 1초에 44100개의 데이터가 하나도 빠짐없이 연속적으로 렌더링되어야만 사용자가 듣기에 이질감없는 소리로 구성되어집니다. 한 순간이라도 오디오가 끊긴다면, 이는 사용자에게 부자연스러움으로 느껴지고, 이를 오디오 용어로는 glitch가 발생했다고 합니다. 여러가지 UI 작업과 다른 스크립트 코드가 계속해서 실행되는 UI 쓰레드에서 5.8ms초의 지연은 굉장히 흔하게 발생하는 일입니다. 그리고 ScriptProcessorNode는 이 UI 쓰레드에서 돌아갑니다. glitch가 빈번히 발생할 것은 이미 예견된 일이죠.
이를 해결하기 위해 Web Audio API 진영에서는 AudioWorklet이라는 새로운 API를 만들었습니다. HTML Canvas를 별도의 쓰레드에서 사용 할 수 있도록 해주는 Offscreen Canvas처럼, AudioWorklet은 ScriptProcessorNode가 하던 일들을 별도의 쓰레드에서 실행될 수 있도록 해줍니다. AudioWorklet의 기본 코드는 다음과 같습니다.
// This is "processor.js" file, evaluated in AudioWorkletGlobalScope upon
// audioWorklet.addModule() call in the main global scope.
class MyWorkletProcessor extends AudioWorkletProcessor {
constructor() {
super();
}
process(inputs, outputs, parameters) {
// audio processing code here.
}
}
registerProcessor('my-worklet-processor', MyWorkletProcessor);
ScriptProcessorNode와 유사합니다. 기존 audioprocess 함수가 process 함수로 이름이 바뀐 것 정도만 주목하시면 될 것 같네요. 그리고, 무엇보다 이 함수들이 이제 별도의 쓰레드에서 돌아간다는 것도요.
ScriptProcessorNode에서는 버퍼 사이즈에 대한 선택지를 다양하게 제공한 반면, 현재 AudioWorklet은 Chrome을 기준으로 항상 버퍼 사이즈를 128로만 사용하도록 제공하고 있습니다. 44.1Khz 기준으로 3ms 정도의 시간이므로, 3ms 마다 꾸준히 데이터를 제공해줘야 합니다.
이제 이 AudioWorklet과 Web Worker를 사용하여 실제 비디오 플레이어를 흉내내보도록 하겠습니다. 우선 완성된 결과물을 여기서 확인해보세요. 페이지를 실행하기 위해서는 2019년 5월 기준으로 최신 버전의 Chrome과, Experimental Web Platform features flag를 활성화 시켜줘야 합니다.
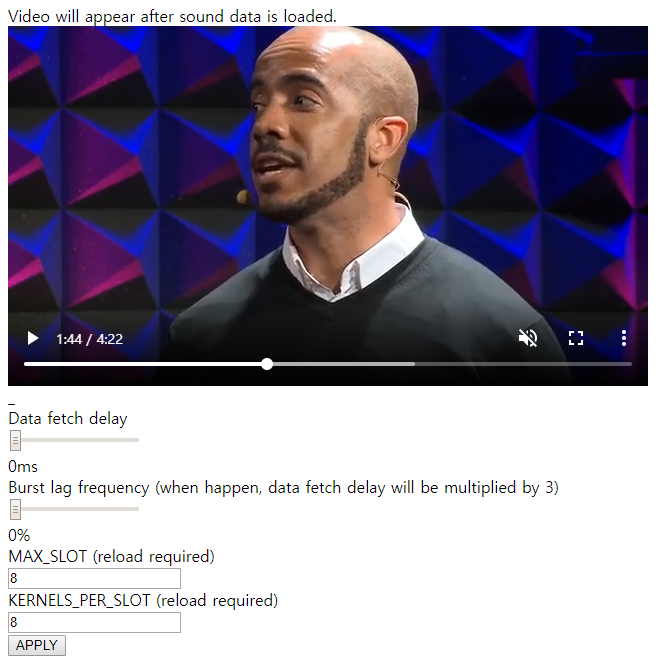
약 44MB의 오디오 데이터를 가져와야 하기 때문에 비디오가 나타나는 데에는 약간의 시간이 필요합니다. 비디오가 로드되면, 비디오를 재생해보세요. 영상과 음성이 모두 싱크에 맞게 재생되는 것을 볼 수 있을 겁니다. 자세히 살펴보면, 비디오 플레이어의 음성은 음소거 되어 있습니다. 재생되는 소리는 HTML Video가 아닌, AudioWorklet에 의해 렌더링되고 있는 것입니다.
AudioWorklet은 WebWorker의 일종이기 때문에, 두 쓰레드 간 통신을 위해서 우리는 SharedArrayBuffer와 Atomics API를 사용할 수 있습니다. SharedArrayBuffer는 웹 쓰레드간 공유가 가능한 공유 메모리(Shared memory) 버퍼입니다. Atomics는 쓰레드 간 synchronization을 위한 API로, lock을 사용하거나, lock-free 또한 구현하고 있기 때문에 lock-free로써 사용할 수도 있습니다.
기본 시나리오는 다음과 같습니다. WebWorker와 AudioWorklet은 SharedArrayBuffer를 통해 데이터를 공유하고, Atomics API를 통해 신호를 주고 받습니다. WebWorker는 오디오 데이터를 생성하는 생산자, Producer이며, AudioWorklet은 오디오 데이터를 소모하는 소비자, Consumer입니다.
두 쓰레드는 Ring buffer를 통해 오디오 데이터를 공유합니다. WebWorker는 Ring buffer에 데이터를 쓰고, AudioWorklet은 Ring buffer에 쓰여진 데이터를 읽어오게 됩니다.
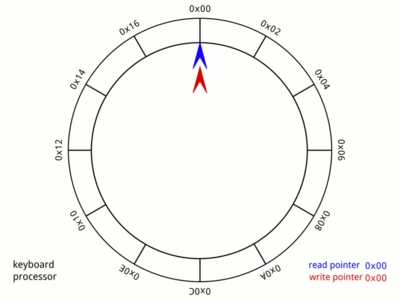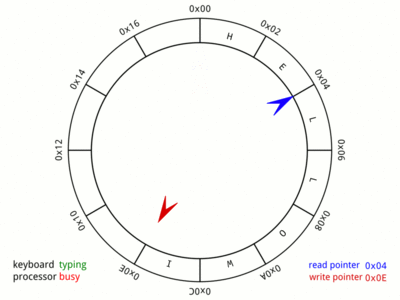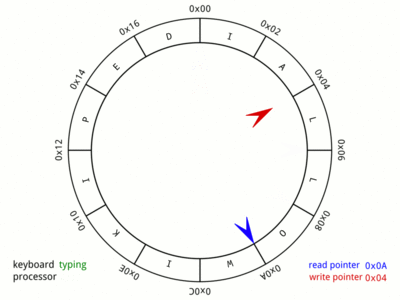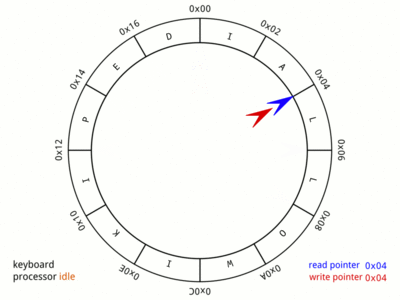
그림) Ring buffer의 기본적인 동작 구조, Wikipedia
흔히 Ring buffer를 Producer-Consumer 패턴으로 사용할 때는 위의 그림과 같이 각 Producer와 Consumer가 가르키는 슬롯의 위치를 나타내는 커서(Cursor)를 가지고 있고, Producer가 데이터를 생산할 때 마다 Producer의 커서가 증가하고, Consumer가 데이터를 소비할 때 마다 Consumer의 커서가 증가하는 식으로 반복되면서, Consumer가 더 이상 소비할 데이터가 없을 때, 즉 Producer와 Consumer의 커서 위치가 같게 될 경우는 Producer가 데이터를 생산할 때 까지 Consumer는 대기하는 구조로 사용되게 됩니다.
그러나 여기서는 조금 다르게 활용합니다. 우선 커서는 두 가지 정보를 담고 있습니다. 하나는 슬롯의 offset이고, 하나는 슬롯의 index입니다. index는 현재 커서가 총 몇 개의 슬롯을 거쳐왔는지 나타냅니다. 즉, 최초 커서의 index는 0이고, Consumer가 50개의 슬롯을 소비했다면 Consumer 커서의 index는 50입니다. offset은 현재 index가 몇 번째 슬롯을 가르키고 있는지 나타냅니다. Ring buffer가 총 8개의 슬롯으로 구성되었고, 현재 커서의 index가 50이라면, 커서의 offset은 50 % 8 = 2 가 됩니다.
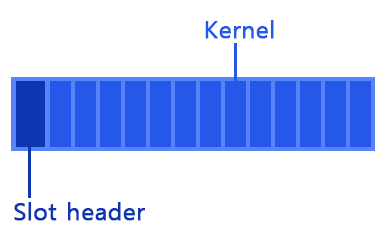
슬롯의 구조는 다음과 같습니다.
Slot header는 현재 슬롯에 기록된 데이터가 몇 번째 index인지 나타냅니다. 즉, 슬롯에 Producer가 데이터를 기록할 때 Producer 커서의 index가 됩니다.
Kernel은 AudioWorklet이 한 번에 처리하는 버퍼 사이즈와 동일한 사이즈를 가집니다. Chrome 기준으로 AudioWorklet은 128 프레임 크기의 버퍼를 가지므로, Kernel의 크기는 128 이 됩니다. 슬롯에는 이러한 Kernel이 여러개 담겨져 있습니다.
전체 Ring buffer의 구조는 다음과 같이 여러개의 슬롯으로 구성되게 됩니다.
Consumer(AudioWorklet)는 데이터가 있던 없던 끊임없이 커서를 증가시키며 데이터를 소비합니다. 읽은 슬롯의 헤더를 체크했을 때 만약 헤더에 적혀있는 index가 현재 Consumer 커서의 index와 일치한다면, 해당 데이터를 사운드로 렌더링합니다. 만약 그렇지 않다면, 사운드를 렌더링하지 않습니다.
반면 Producer의 행동은 아래와 같은 복합적인 요소에 의해 결정됩니다.
유저가 비디오 플레이어를 통해 탐색을 요청하면, UI 쓰레드는 Producer로 해당 시간을 렌더링 해 달라고 메세지를 보냅니다. 메세지를 받은 Producer는, Consumer가 새로운 슬롯을 읽을 때 까지 대기합니다. Consumer가 새로운 슬롯을 읽는 순간, Producer는 해당 슬롯의 index를 가져옵니다. 이 새로운 슬롯을 읽을 때 까지 대기하는 시간은 UI 쓰레드에서 요청한 시간에 추가되게 됩니다. 예를 들어 UI 쓰레드에서의 비디오의 36.353초부터 렌더링해달라고 요청했고, Producer가 Consumer로 부터 신호를 받는데 까지 걸리는 시간이 0.008초가 걸렸다면, 실제 Producer가 렌더링을 시작해야하는 시간은 36.361초가 됩니다.
시작 슬롯의 시간이 결정됐다면 나머지 모든 슬롯들에 대한 시간도 자동적으로 결정되게 됩니다. 예를 들어 슬롯이 8개의 Kernel로 구성되어 있고, Kernel의 크기가 128이라면, 각 슬롯은 128 * 8 = 1024개의 프레임을 렌더링하게 되므로, 각 슬롯은 (이전 슬롯의 마지막 프레임) ~ (이전 슬롯의 마지막 프레임 + 1024 프레임) 범위의 프레임에 대한 데이터를 담게 됩니다.
이상적인 시나리오라면 Producer가 항상 Consumer보다 빠르게 데이터를 생산하여 Producer의 커서가 항상 Consumer의 커서보다 앞서 있을 수 있습니다. 하지만 꼭 그렇지만은 못하죠. Producer가 데이터를 생산하는 과정에서, 예를 들면 네트워크 지연이 발생하거나 디코딩에 필요한 CPU 자원이 부족하여 디코딩을 제 시간 내에 이뤄내지 못했다면 Consumer의 커서가 Producer의 커서보다 앞서는 상황이 발생할 수 있습니다. 이럴 경우 Producer는 지연이 발생한 슬롯을 모두 건너뛰고, 커서의 위치를 즉시 Consumer의 커서의 위치로 즉시 이동시켜 해당 슬롯에 해당하는 데이터부터 생산할 수 있도록 재설정 해줍니다.
Consumer인 AudioWorklet은 Atomics API를 사용할 수는 있지만, 한 가지 제약점이 있습니다. lock, 즉 Atomics API 중에서는 Atomics.wait 을 사용할 수 없다는 것입니다. 리얼 타임 오디오 프로세싱 세계에서 blocking이라는 것은 발생해서는 안되는 것으로 취급되기 때문입니다. 한 순간의 blocking이 glitch를 발생시킬 수 있기 때문이죠. 그래서 WebWorker와 AudioWorklet 코드의 동기화는 Atomics API 중 lock-free API를 중심으로 이루어지고 있습니다. Atomics.wait가 사용되는 상호항은 Producer의 슬롯이 가득 차 Consumer의 소비를 기다려야 하는 상황과, 최초 렌더링 시작 시 Producer가 Consumer의 신호를 기다리는 상황 뿐입니다. 동시간대에 같은 슬롯을 접근하는 상황에서도 만약 슬롯의 소유권이 다른 쓰레드에 넘어가 있는 상황이라면 해당 슬롯을 쿨하게 버리고 다음 슬롯으로 넘어가게 될 뿐입니다.
마지막으로 앞서 ScriptProcessorNode에서 버퍼의 크기가 커지면 커질수록 탐색시의 새로운 데이터에 대한 렌더링 latency가 커지는 문제를 언급한적이 있죠. 그 문제는 이 디자인에서도 동일하게 적용됩니다. 비록 AudioWorklet의 기본 처리 단위는 128 프레임이지만, 해당 디자인에서는 기본 처리 단위를 슬롯으로 두고 있기 때문에, 한 슬롯이 가지고 있는 Kernel의 크기, 즉 버퍼의 크기가 커지면 커질수록 탐색시의 렌더링 latency가 커지게 됩니다. 이는 위 예제 페이지에서 KERNELS_PER_SLOT 의 크기를 설정해보면 직접 확인하실 수 있습니다. 해당 값을 1024 정도로 크게 두고, APPLY 버튼을 눌러 설정을 적용시킨 후, 비디오 플레이어에서 탐색을 수행해보세요. 비디오는 시간에 맞게 렌더링되지만 오디오의 경우 꽤 오랜 시간동안 이전 시간에 대한 오디오를 렌더링하다 그제서야 싱크에 맞는 오디오를 렌더링하는 모습을 보실 수 있을 것 입니다.
코드에 대한 좀 더 자세한 설명이 궁금하다면 여기를 (해당 포스트 이전에 작성한 문서라 오히려 해당 포스트가 좀 더 정제된 느낌이 있네요.), 소스 코드가 궁금하다면 여기를 참고해주시면 됩니다.