코딩테스트 대비 특강
이 포스트는 3월 1일과 2일에 걸쳐 진행한 코딩테스트 특강의 내용을 기술한 포스트입니다. BFS/DFS, 백트래킹, 시뮬레이션 개념을 알고 있고 기출 문제에 손을 댈 수는 있는데 100% 푼다는 확신은 없어서 개념을 다시 정리하고 모의고사를 쳐보고 싶은 분이 이 포스트를 보신다면 많은 도움이 될 것입니다.
특강의 슬라이드는 여기에서 확인할 수 있습니다. 이 특강은 개인이 준비한 특강이고, 특히 특정 기업의 채용절차와 아무런 관련이 없습니다.




 무엇보다 먼저 기초 지식과 자주 실수하는 점을 짚고 넘어가겠습니다. 함수의 인자로 구조체/pair/tuple/vector를 넘길 때 어떤 식으로 처리가 되는지를 명확하게 알고 있어야 합니다. 이를 알지 못할 경우 시간초과가 발생하거나 의도하지 않은 대로 동작할 수 있습니다.
무엇보다 먼저 기초 지식과 자주 실수하는 점을 짚고 넘어가겠습니다. 함수의 인자로 구조체/pair/tuple/vector를 넘길 때 어떤 식으로 처리가 되는지를 명확하게 알고 있어야 합니다. 이를 알지 못할 경우 시간초과가 발생하거나 의도하지 않은 대로 동작할 수 있습니다.
Q1부터 Q8까지 8가지의 질문이 있는데 한 번 결과를 고민해보세요. 답은 문제가 다 나온 후에 적혀있습니다.
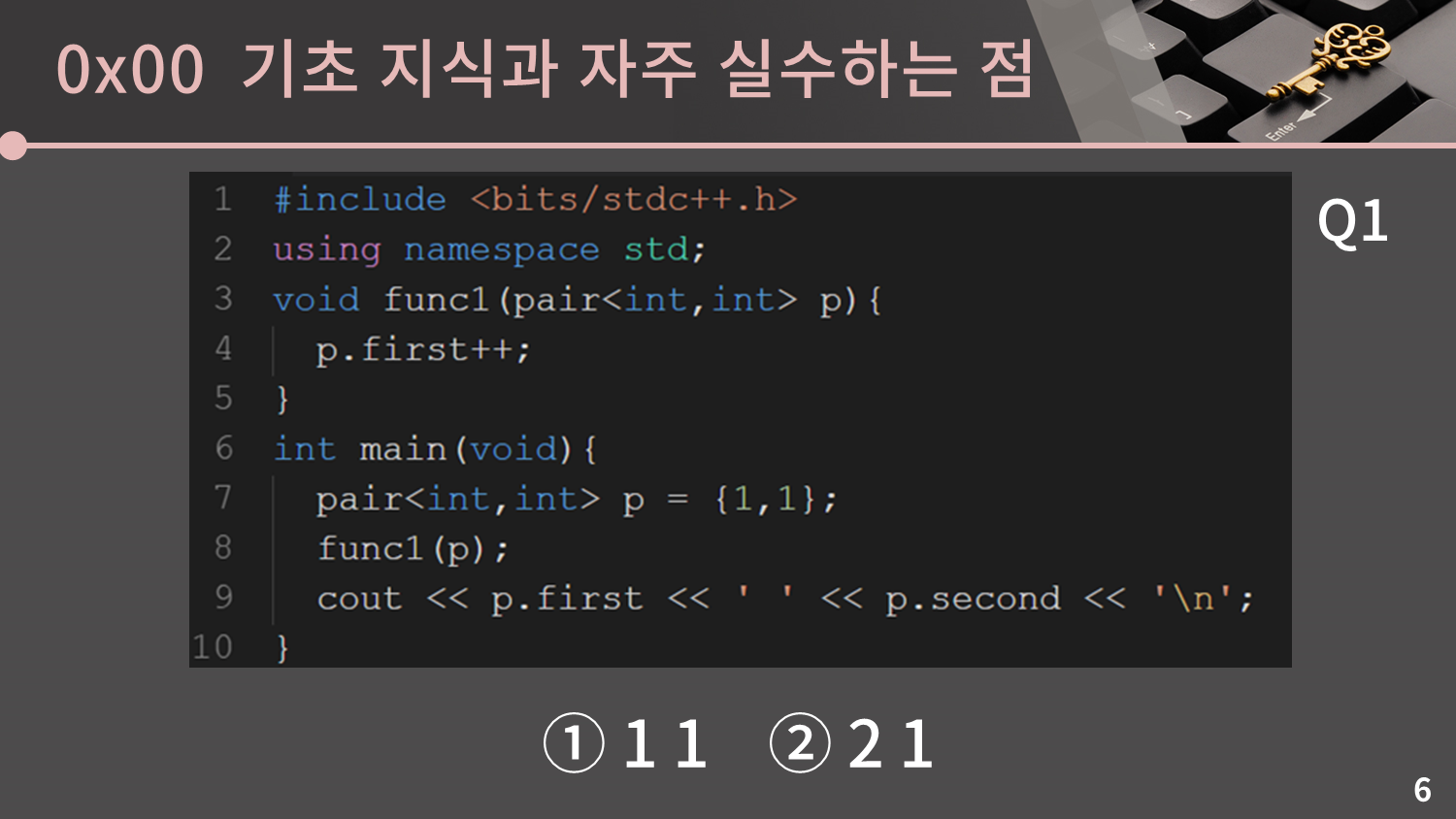 첫 번째 질문은 pair를 함수의 인자로 보낼 때 어떤 일이 발생할까에 관한 질문입니다.
첫 번째 질문은 pair를 함수의 인자로 보낼 때 어떤 일이 발생할까에 관한 질문입니다.
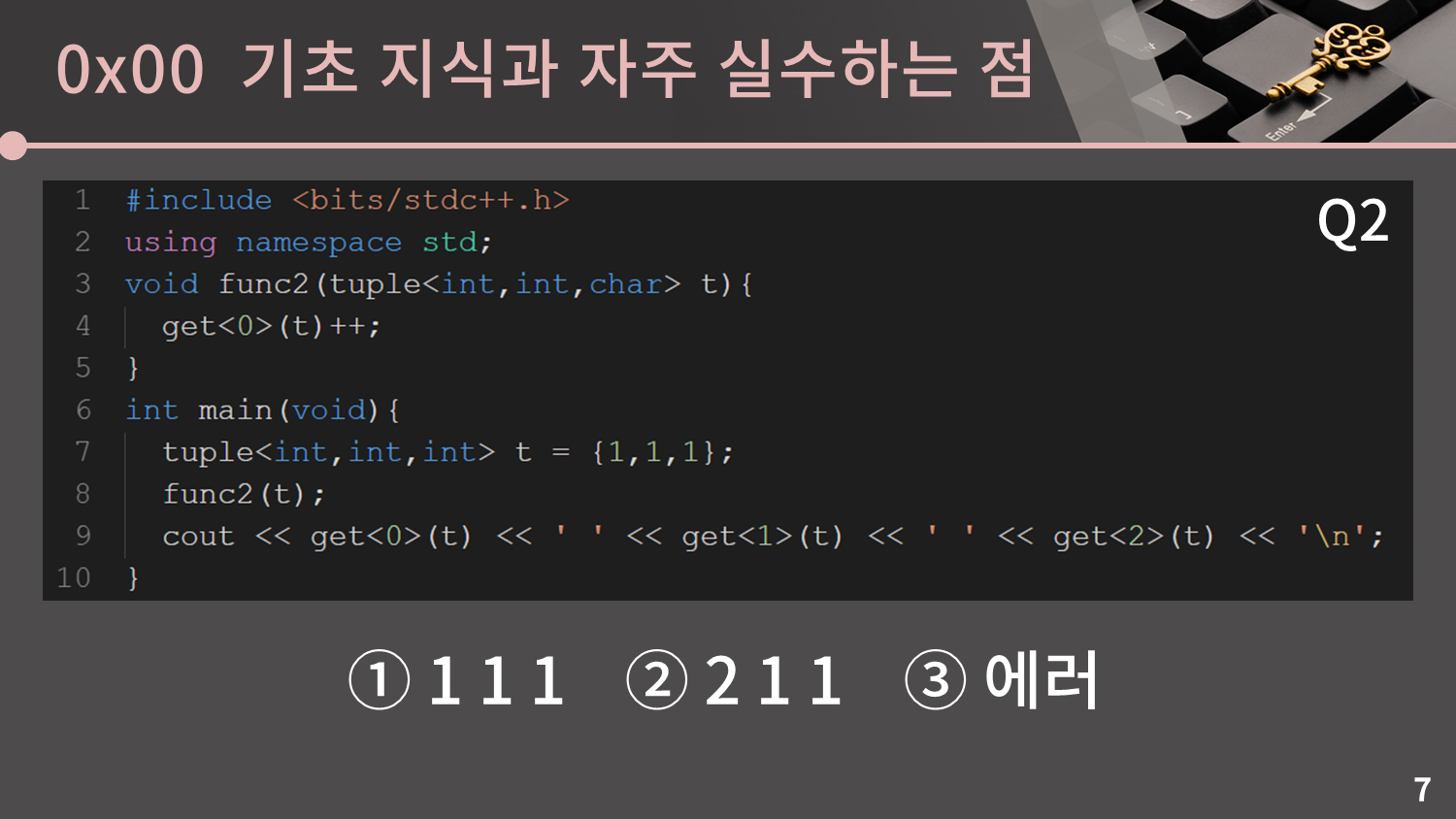 그 다음은 pair대신 tuple입니다.
그 다음은 pair대신 tuple입니다.
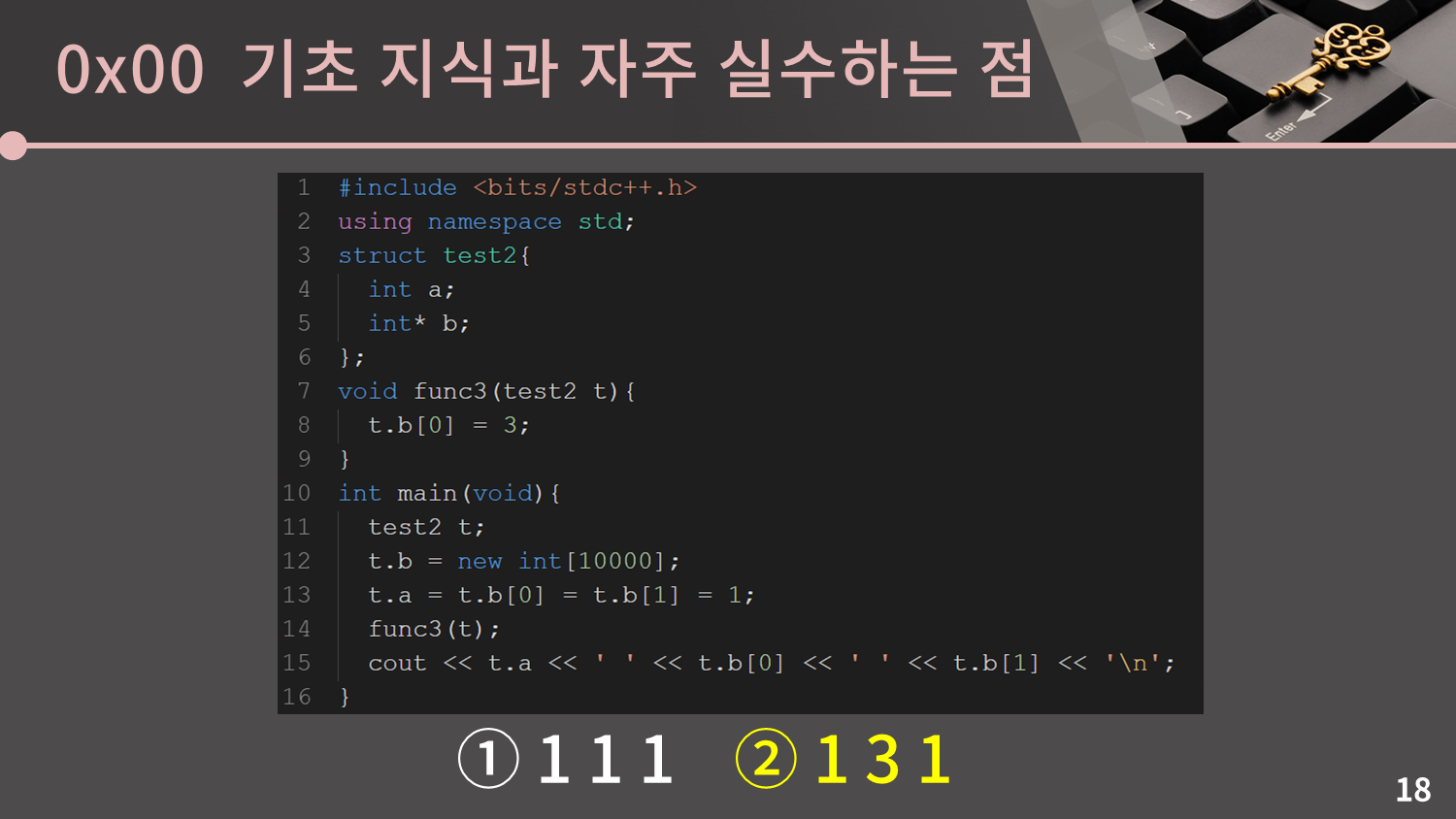
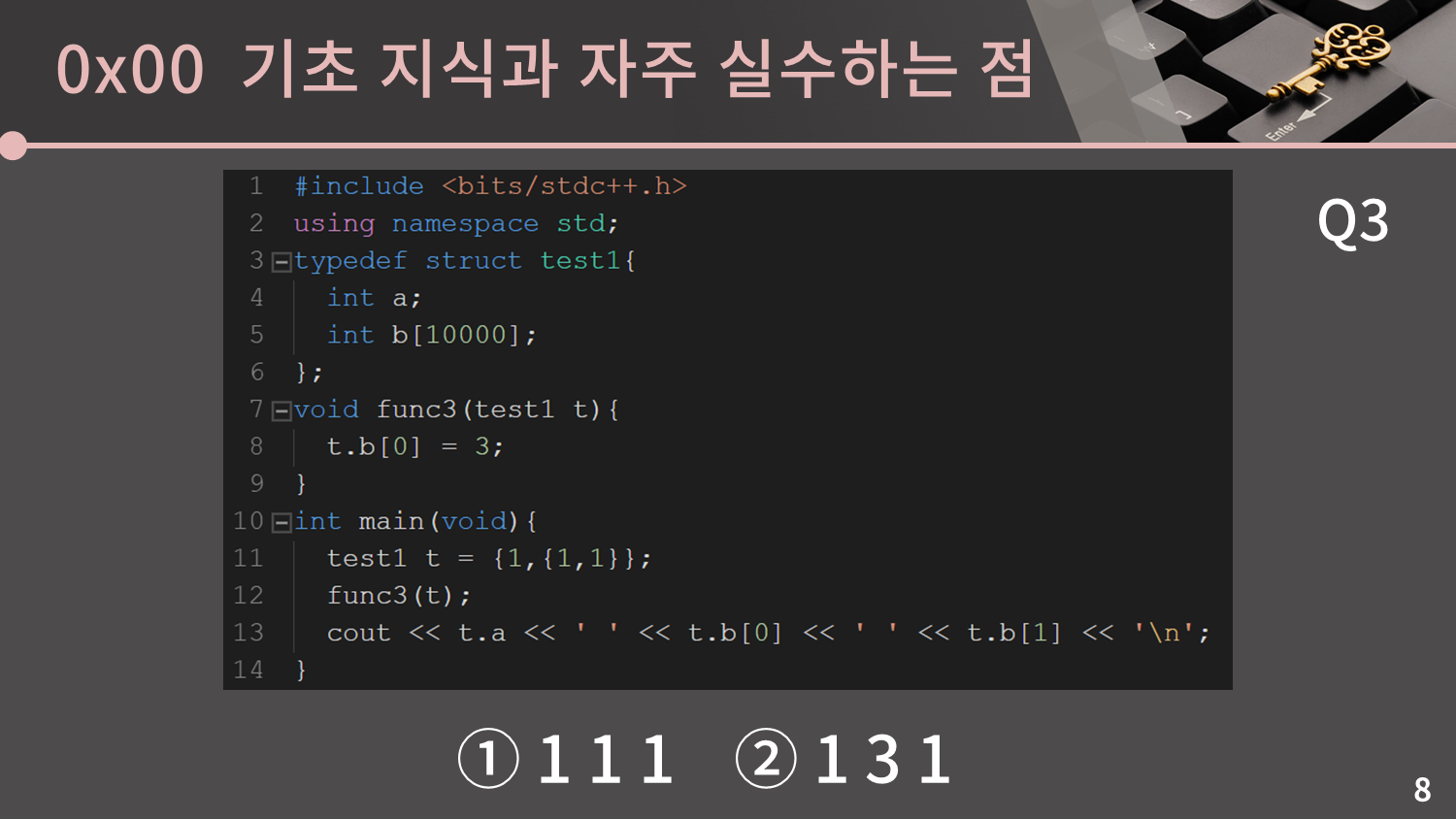 그 다음은 구조체입니다. 나머지 문제들도 특강에 참여한 사람들의 정답률이 60% 아래였지만 특히 이 문제의 경우 정답률이 30%가 채 되지 않았습니다. 정답을 맞춰보세요.
그 다음은 구조체입니다. 나머지 문제들도 특강에 참여한 사람들의 정답률이 60% 아래였지만 특히 이 문제의 경우 정답률이 30%가 채 되지 않았습니다. 정답을 맞춰보세요.
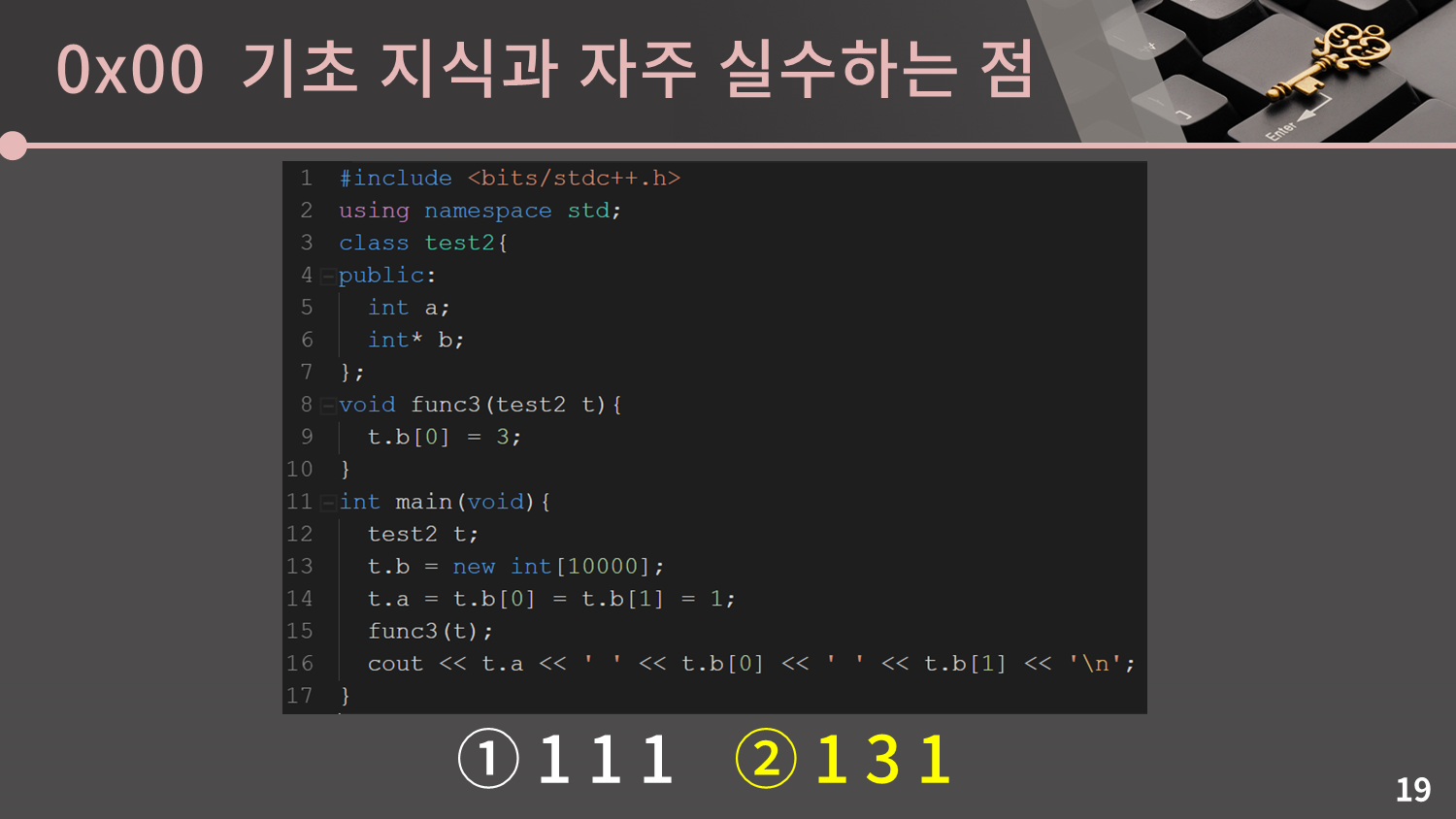
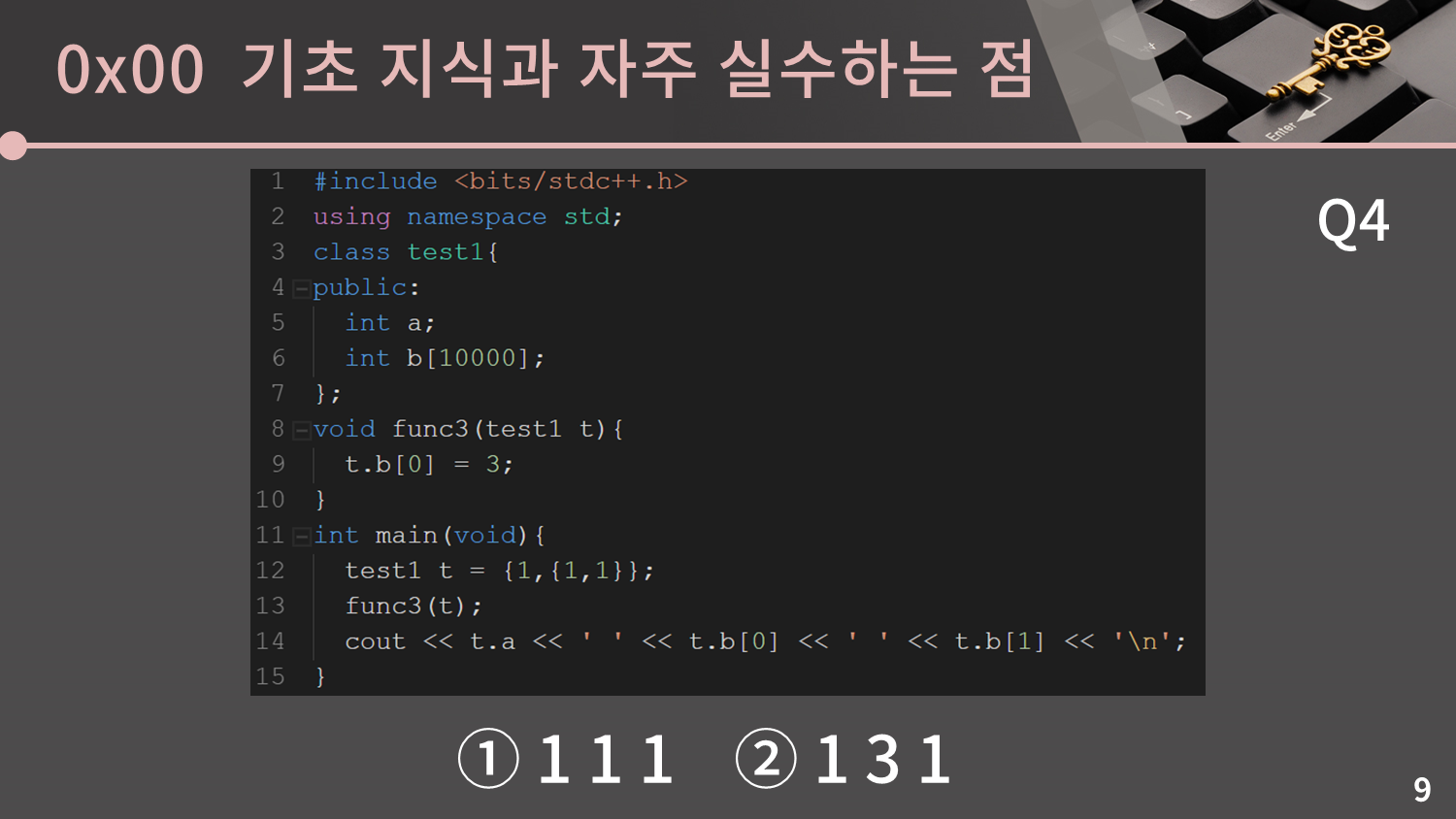 이제는 구조체가 class로 바뀌었네요.
이제는 구조체가 class로 바뀌었네요.
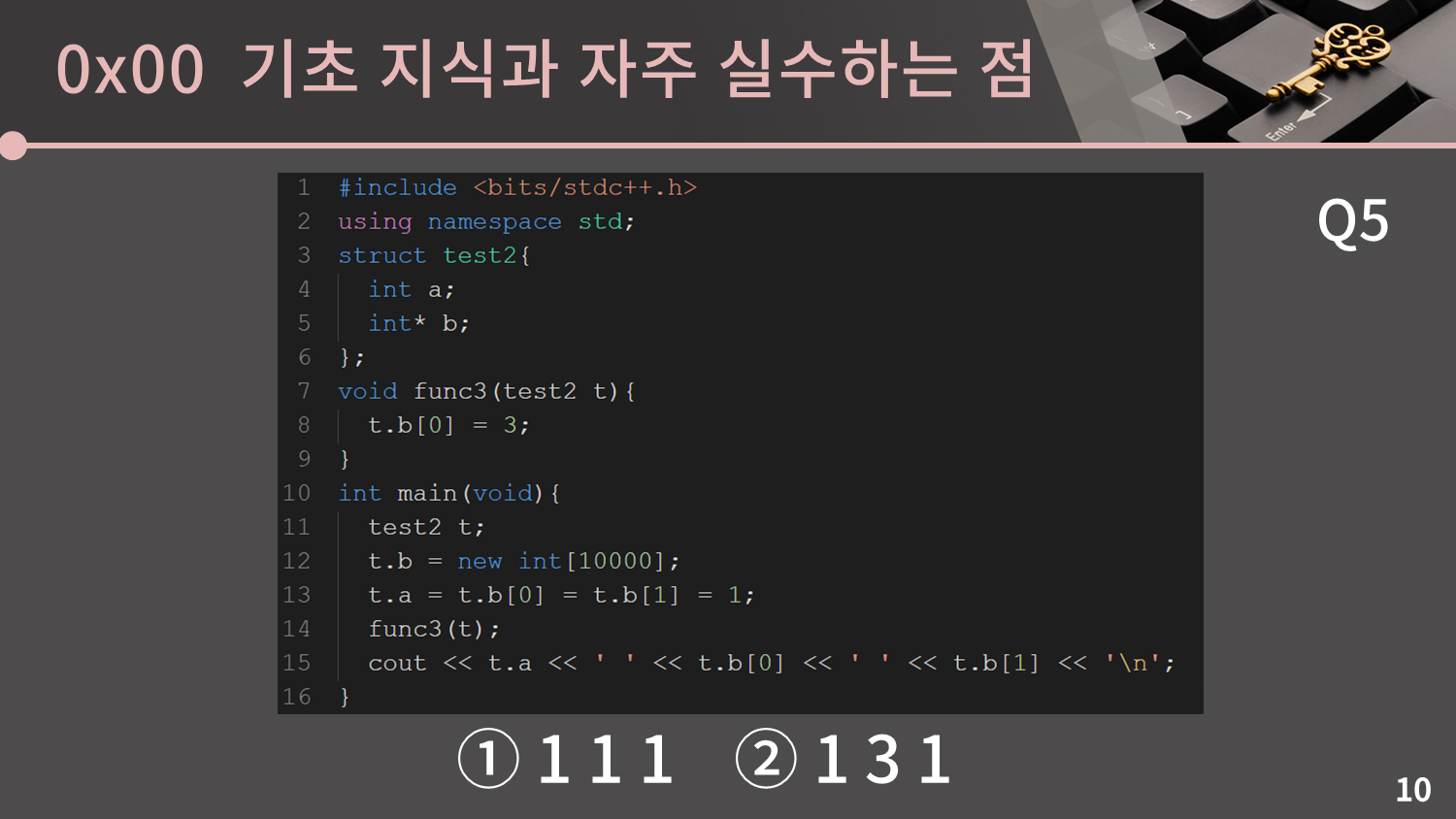 이번에는 구조체인데 배열이 아니라 포인터입니다.
이번에는 구조체인데 배열이 아니라 포인터입니다.
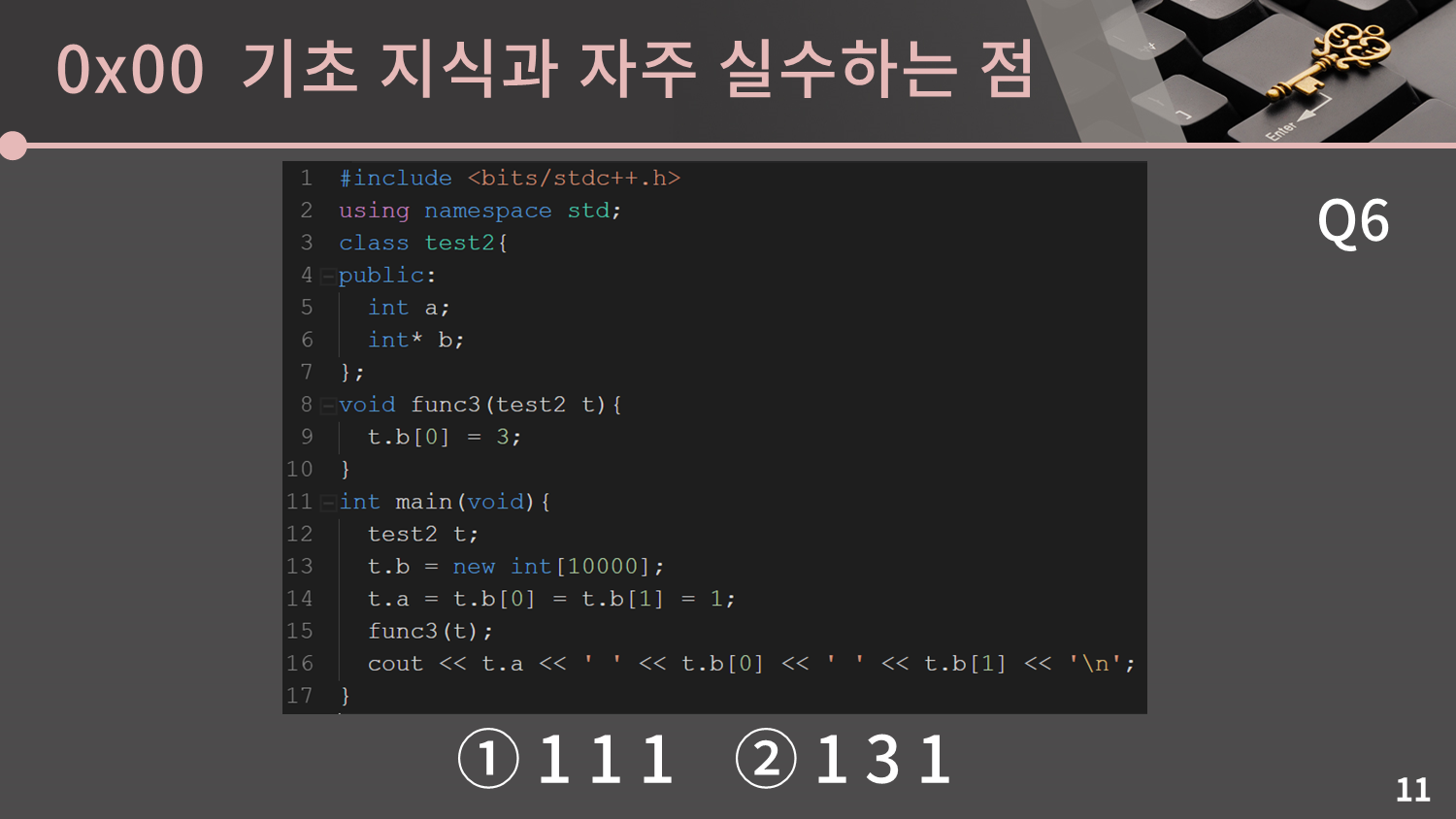 마찬가지로 구조체가 class로 바뀌었습니다.
마찬가지로 구조체가 class로 바뀌었습니다.
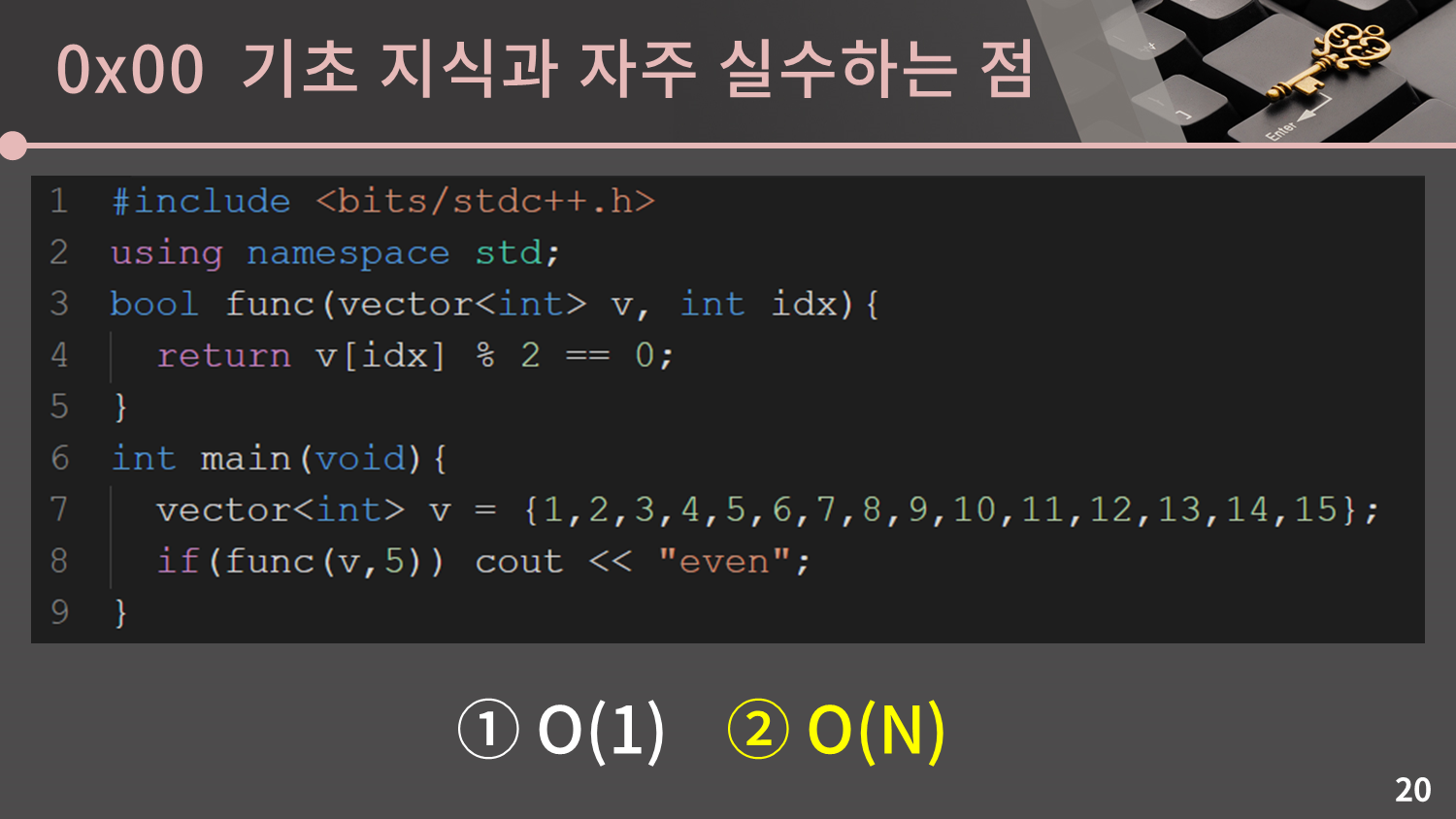
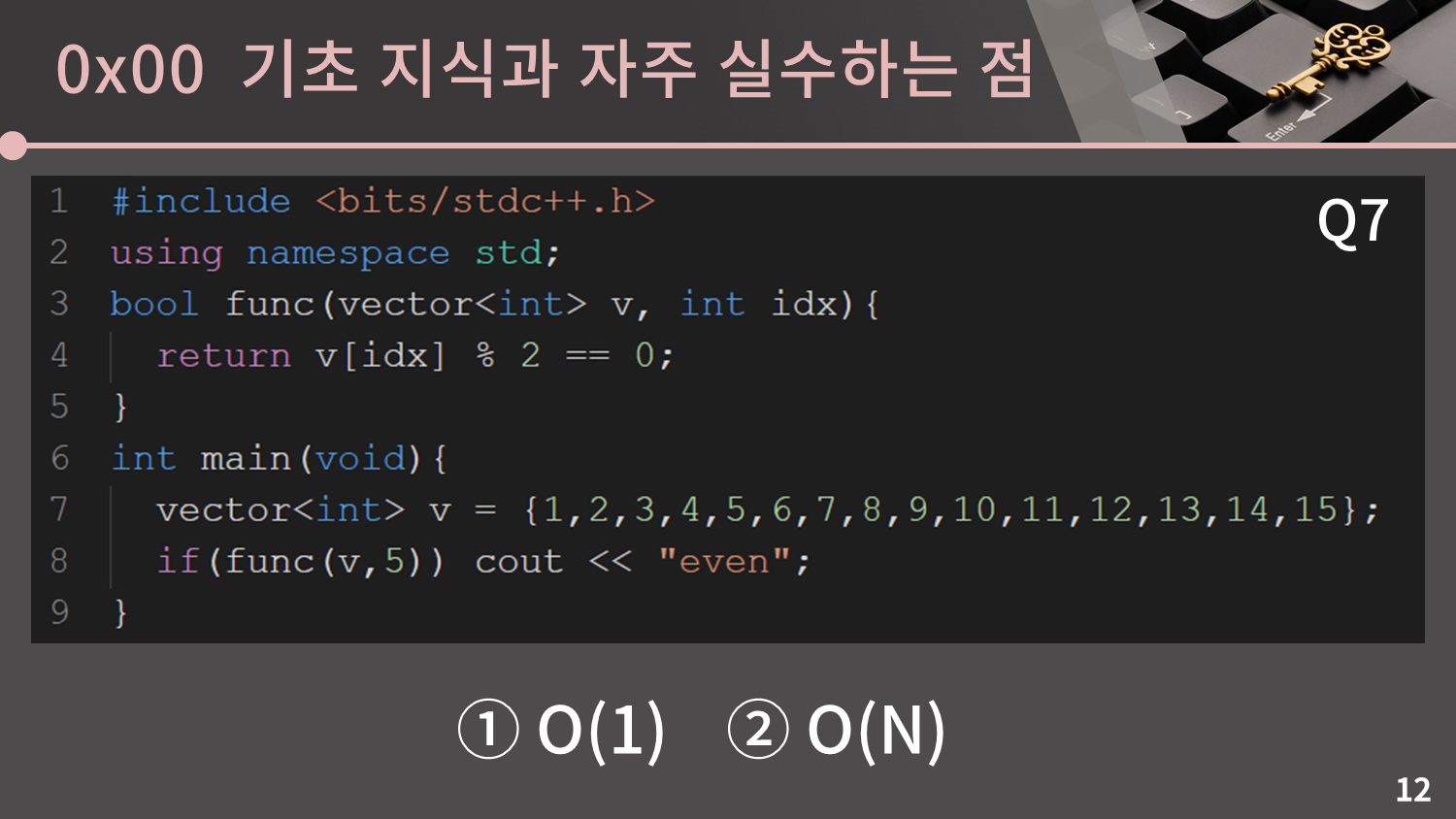 이 문제에서는 코드의 시간복잡도를 물어보고 있습니다.
이 문제에서는 코드의 시간복잡도를 물어보고 있습니다.
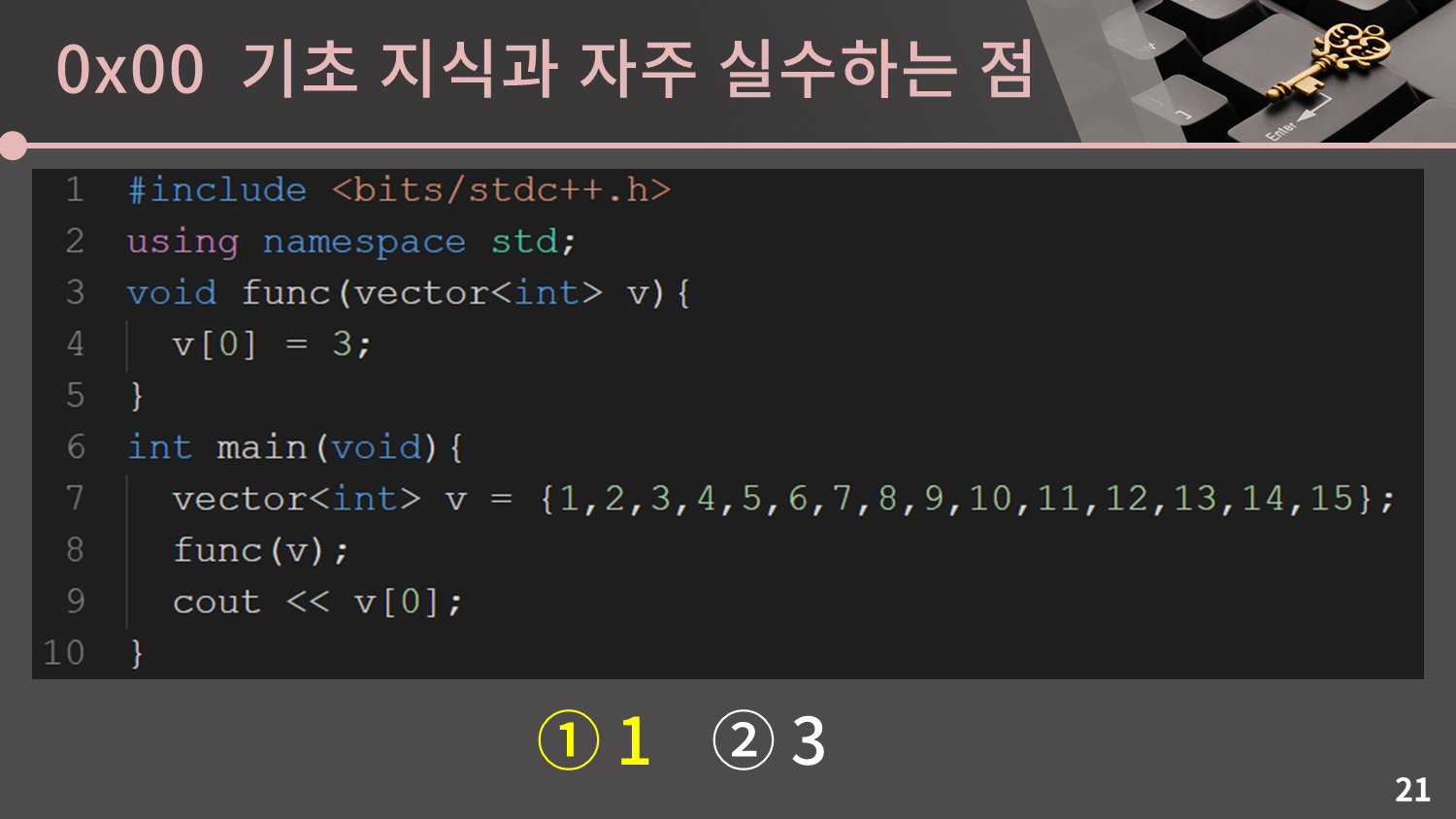
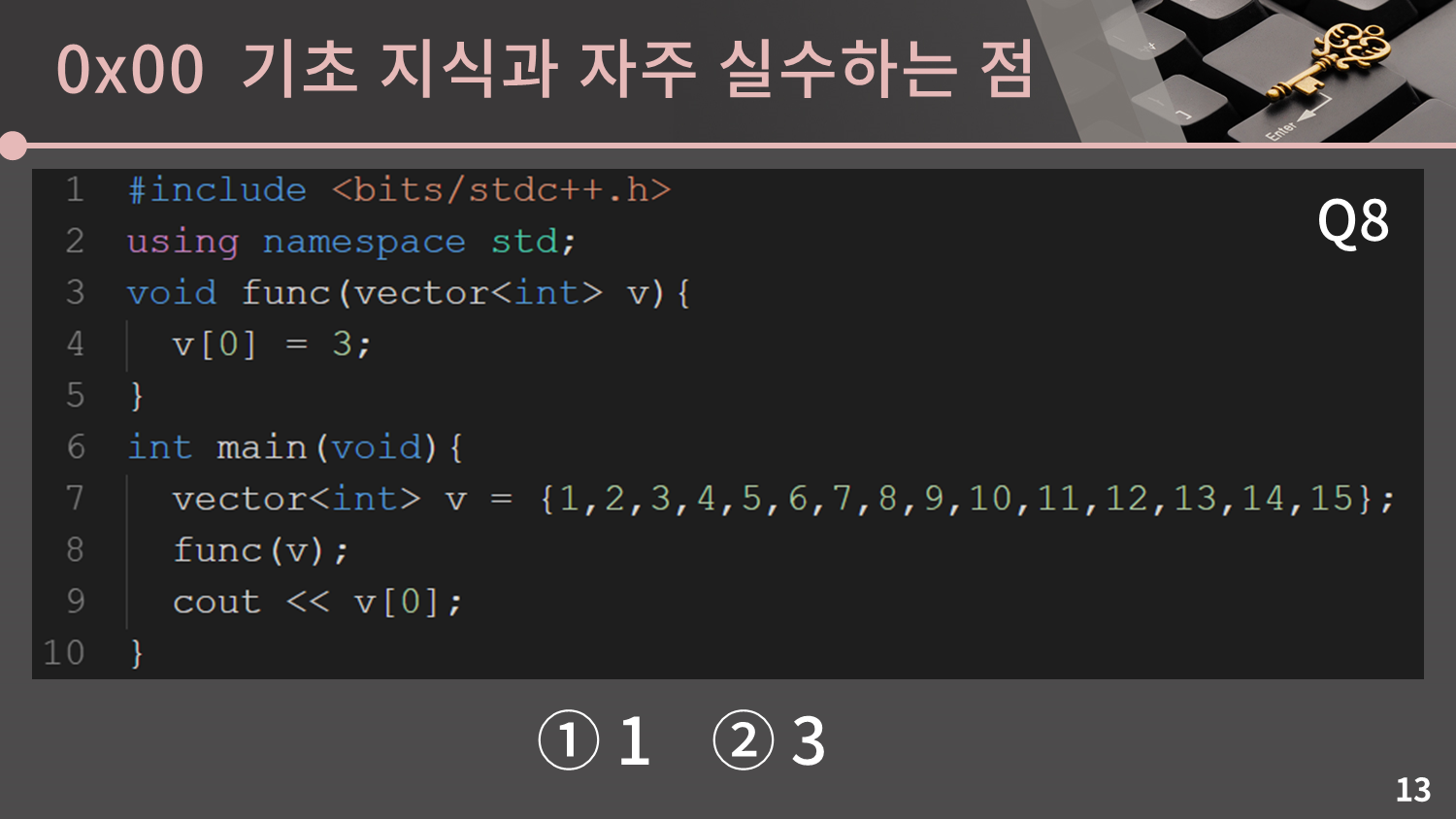 마지막은 vector를 함수의 인자로 넘길 때에 관한 질문입니다. 이제 다음 슬라이드부터는 이 8문제에 대한 답이 있으니 미리 자신이 생각한 답을 기록해두고 실제 정답과 비교해보세요.
마지막은 vector를 함수의 인자로 넘길 때에 관한 질문입니다. 이제 다음 슬라이드부터는 이 8문제에 대한 답이 있으니 미리 자신이 생각한 답을 기록해두고 실제 정답과 비교해보세요.
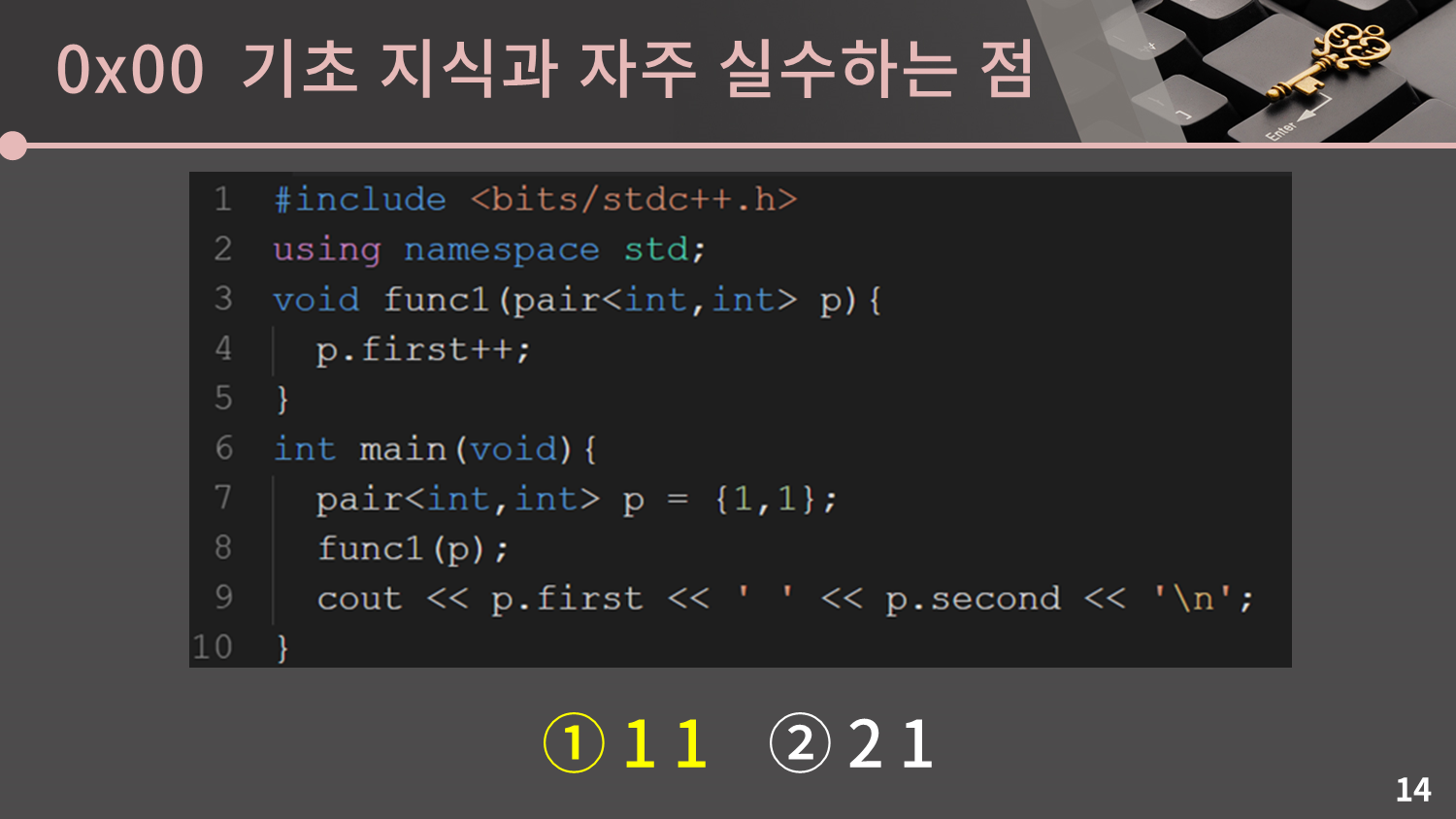
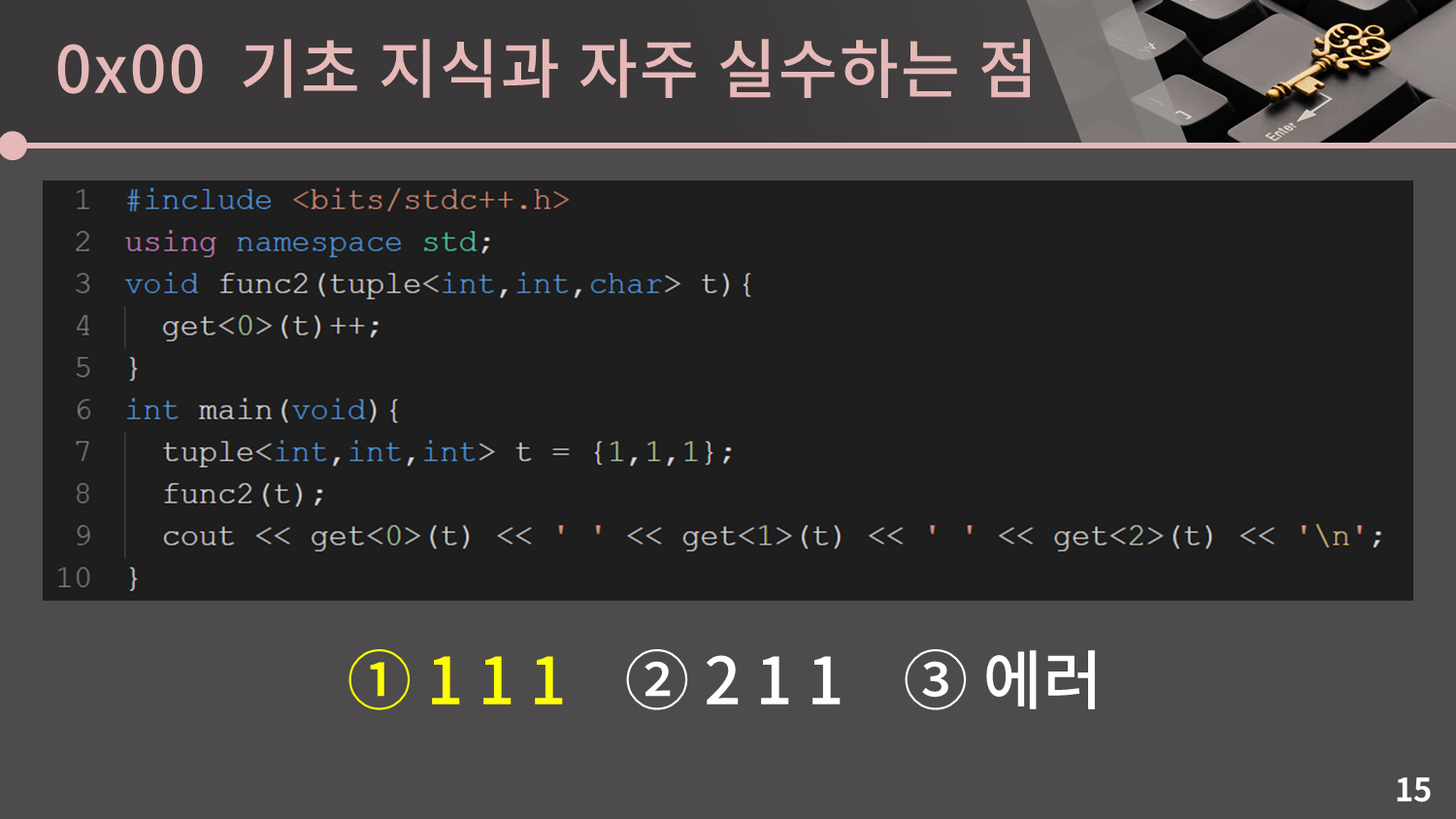
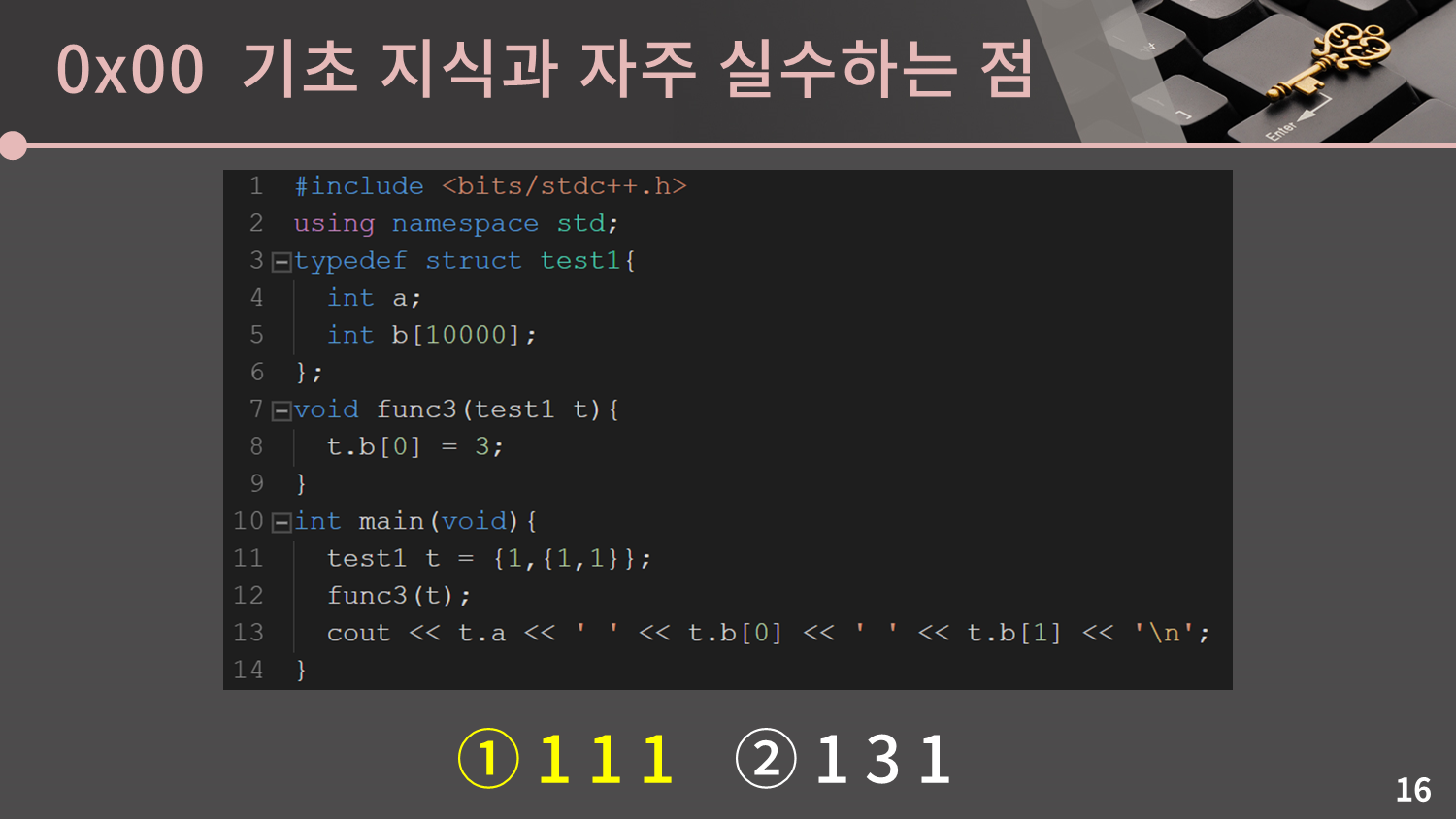
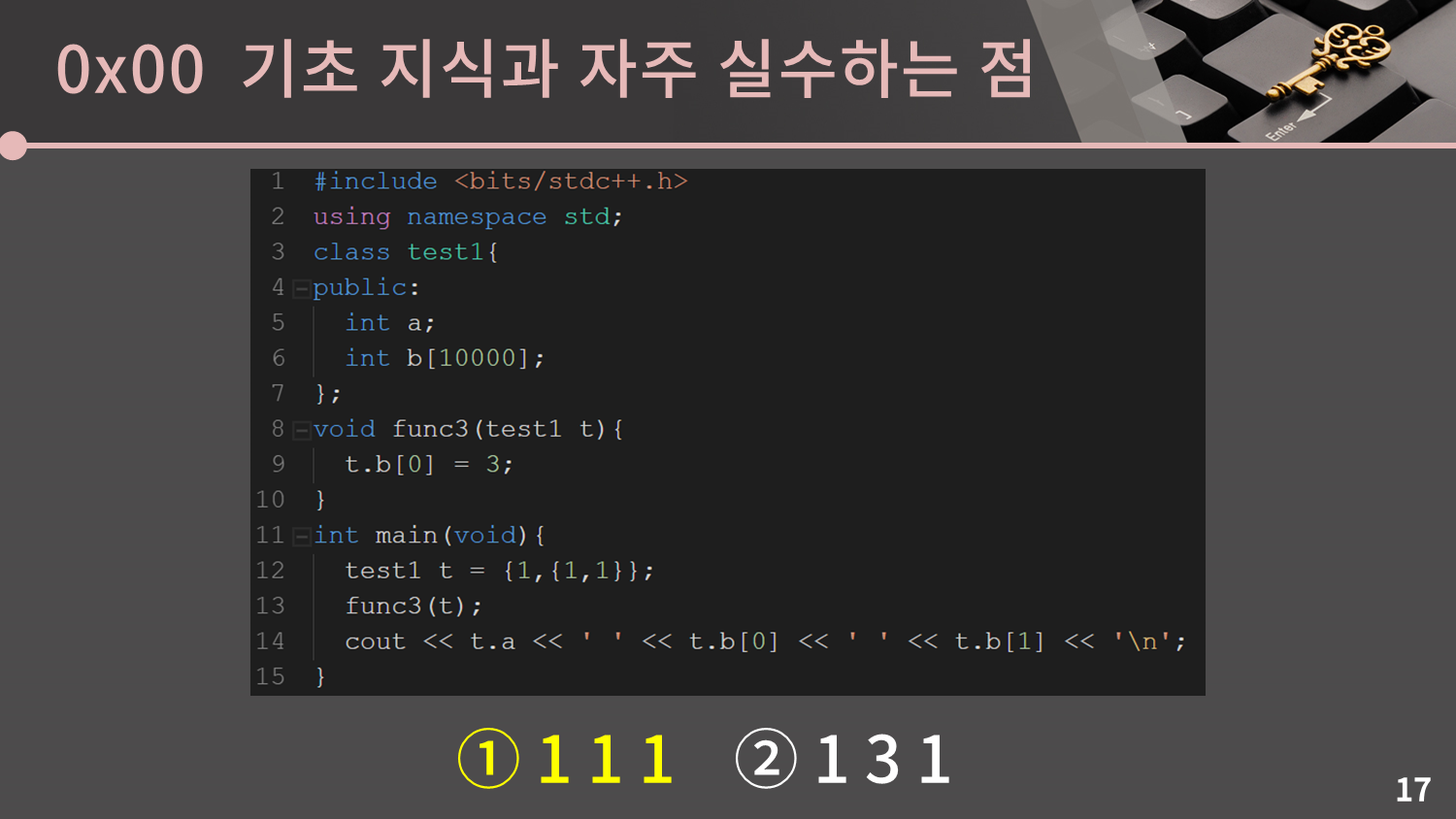
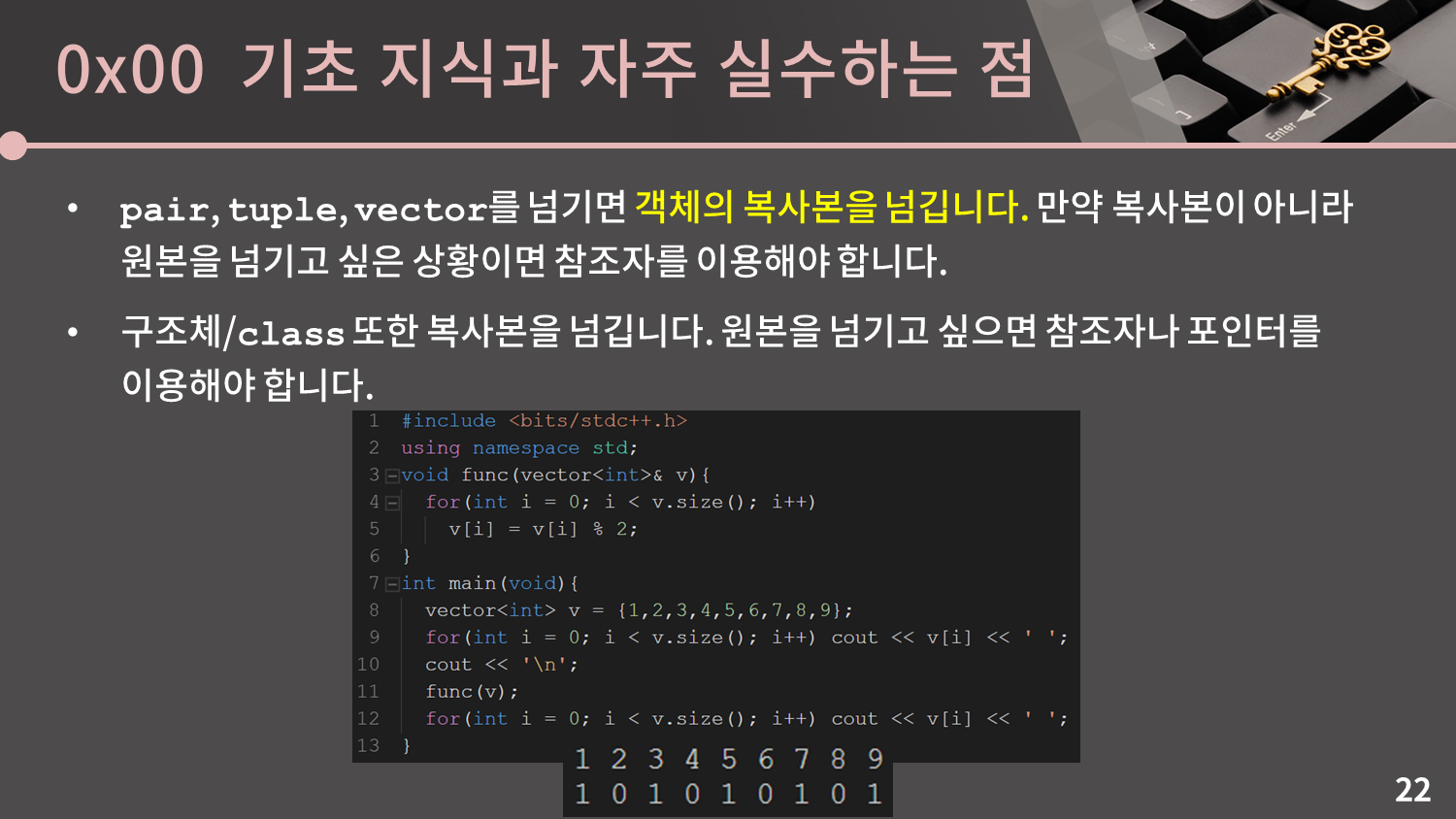 어떤가요? 풀만했나요? 다 맞춘 분이 굉장히 드물 것으로 예상됩니다. pair, tuple, vector를 넘기면 객체의 복사본을 넘긴다는 것에 주의해야 합니다. 만약 복사본이 아니라 원본을 넘기고 싶은 상황이면 참조자를 이용해야 합니다. 만약 참조자가 익숙하지 않으면 개인적으로 공부를 하시는 것을 추천드립니다.
어떤가요? 풀만했나요? 다 맞춘 분이 굉장히 드물 것으로 예상됩니다. pair, tuple, vector를 넘기면 객체의 복사본을 넘긴다는 것에 주의해야 합니다. 만약 복사본이 아니라 원본을 넘기고 싶은 상황이면 참조자를 이용해야 합니다. 만약 참조자가 익숙하지 않으면 개인적으로 공부를 하시는 것을 추천드립니다.
구조체/class 또한 복사본을 넘깁니다. 특히 3번째와 같이 구조체 내에 배열이 있을 경우 그 배열의 내용 전체를 복사해서 넘기기 때문에 함수에서 값을 수정한다고 해도 원본에 영향을 주지 않음에 조심해야 합니다.
 그 다음으로 다룰 부분은 메모리 구조입니다. 지역 변수, 전역 변수, 동적으로 할당한 변수들이 각각 어느 메모리에 올라가는지는 전공생의 경우 시스템 프로그래밍이나 운영체제와 같은 과목에서 배웠을 것입니다. 특강에서는 딱 코딩테스트를 진행할 때 필요한 만큼만 짚고 넘어갈 것이지만 추후에 기술면접을 대비하기 위해서는 이 부분을 반드시 정확하게 공부하고 가시길 바랍니다.
그 다음으로 다룰 부분은 메모리 구조입니다. 지역 변수, 전역 변수, 동적으로 할당한 변수들이 각각 어느 메모리에 올라가는지는 전공생의 경우 시스템 프로그래밍이나 운영체제와 같은 과목에서 배웠을 것입니다. 특강에서는 딱 코딩테스트를 진행할 때 필요한 만큼만 짚고 넘어갈 것이지만 추후에 기술면접을 대비하기 위해서는 이 부분을 반드시 정확하게 공부하고 가시길 바랍니다.
 프로그램이 사용하는 메모리는 크게
프로그램이 사용하는 메모리는 크게 Code, Data, BSS, Heap, Stack이라는 5개의 영역으로 나눌 수 있습니다. 이 5개의 영역 각각에 어떤 것이 저장되는지는 슬라이드에 나와있으나 코딩테스트를 위해서는 다른 것은 크게 중요하지 않으나 Stack 영역에 지역변수와 함수의 인자가 올라간다는 사실을 기억하세요.
 이 5개 영역에서 소비한 메모리의 총합이 채점 환경에서 계산하는 메모리의 양입니다. 만약 메모리를 주어진 제한보다 더 사용하게 되면 메모리 초과가 발생합니다.
이 5개 영역에서 소비한 메모리의 총합이 채점 환경에서 계산하는 메모리의 양입니다. 만약 메모리를 주어진 제한보다 더 사용하게 되면 메모리 초과가 발생합니다.
그런데 일부 채점 환경에서는 전체 메모리 제한과 별개로 스택 메모리가 1MB로 제한되기도 합니다. 그리고 Visual Studio 2017, Windows에서 MinGW를 이용한 GCC 또한 별도로 설정을 변경하지 않으면 스택 메모리가 1MB로 제한됩니다.
 스택 메모리가 1MB로 제한되면 지역 변수를 1MB 이상 잡았을 때, 혹은 재귀의 깊이가 깊어질 때 런타임 에러가 발생합니다. 1MB는 대략 int 25만개 정도이고, 재귀의 깊이가 허용되는 정도는 함수의 인자가 몇 개인지, 함수 내에서 사용한 지역 변수가 몇 개인지에 따라 다르지만 보통 1MB에서는 20000-40000번 정도의 깊이를 가진 프로그램이 정상적으로 동작하지 못하고 런타임 에러가 발생합니다. 슬라이드에 적혀있는 코드는 3,500,000번의 깊이를 가진 프로그램으로, 스택 메모리가 1MB로 제한된 곳에서 실행시켜보면 실제로 프로그램이
스택 메모리가 1MB로 제한되면 지역 변수를 1MB 이상 잡았을 때, 혹은 재귀의 깊이가 깊어질 때 런타임 에러가 발생합니다. 1MB는 대략 int 25만개 정도이고, 재귀의 깊이가 허용되는 정도는 함수의 인자가 몇 개인지, 함수 내에서 사용한 지역 변수가 몇 개인지에 따라 다르지만 보통 1MB에서는 20000-40000번 정도의 깊이를 가진 프로그램이 정상적으로 동작하지 못하고 런타임 에러가 발생합니다. 슬라이드에 적혀있는 코드는 3,500,000번의 깊이를 가진 프로그램으로, 스택 메모리가 1MB로 제한된 곳에서 실행시켜보면 실제로 프로그램이 DONE ^__^을 출력하지 못하고 비정상적으로 죽는 것을 확인할 수 있습니다.
 그렇기 때문에 채점 환경에서 메모리 제한과 별도로 스택 메모리가 1MB로 제한된다면 지역 변수를 많이 잡지 말고 재귀 또한 너무 깊어지지 않도록 해야 합니다.
그렇기 때문에 채점 환경에서 메모리 제한과 별도로 스택 메모리가 1MB로 제한된다면 지역 변수를 많이 잡지 말고 재귀 또한 너무 깊어지지 않도록 해야 합니다.
보통 Tree DP 문제를 DFS로 풀 때 재귀 깊이에 관한 문제가 많이 생기곤 하는데, 딱히 코딩테스트에 나올만한 문제는 아니어서 재귀의 깊이는 걱정하지 않으셔도 되는데, 지역 변수를 너무 많이 잡아 런타임 에러가 발생하는 것은 조심해야 합니다.
스택 메모리의 제한이 없다면 지역 변수를 주어진 메모리 제한 내에서 얼마든지 많이 잡아도 됩니다. 그렇지만 보통 알고리즘 문제를 풀 때에는 지역 변수 대신 전역 변수를 많이 활용하는 편이긴 합니다. 아마 저지 사이트에서 문제를 풀 때 다른 사람의 정답 코드를 보면 프로그램 내에서 쓰일 각종 변수들을 전역에 모조리 두는 것을 많이 봤을 것입니다.
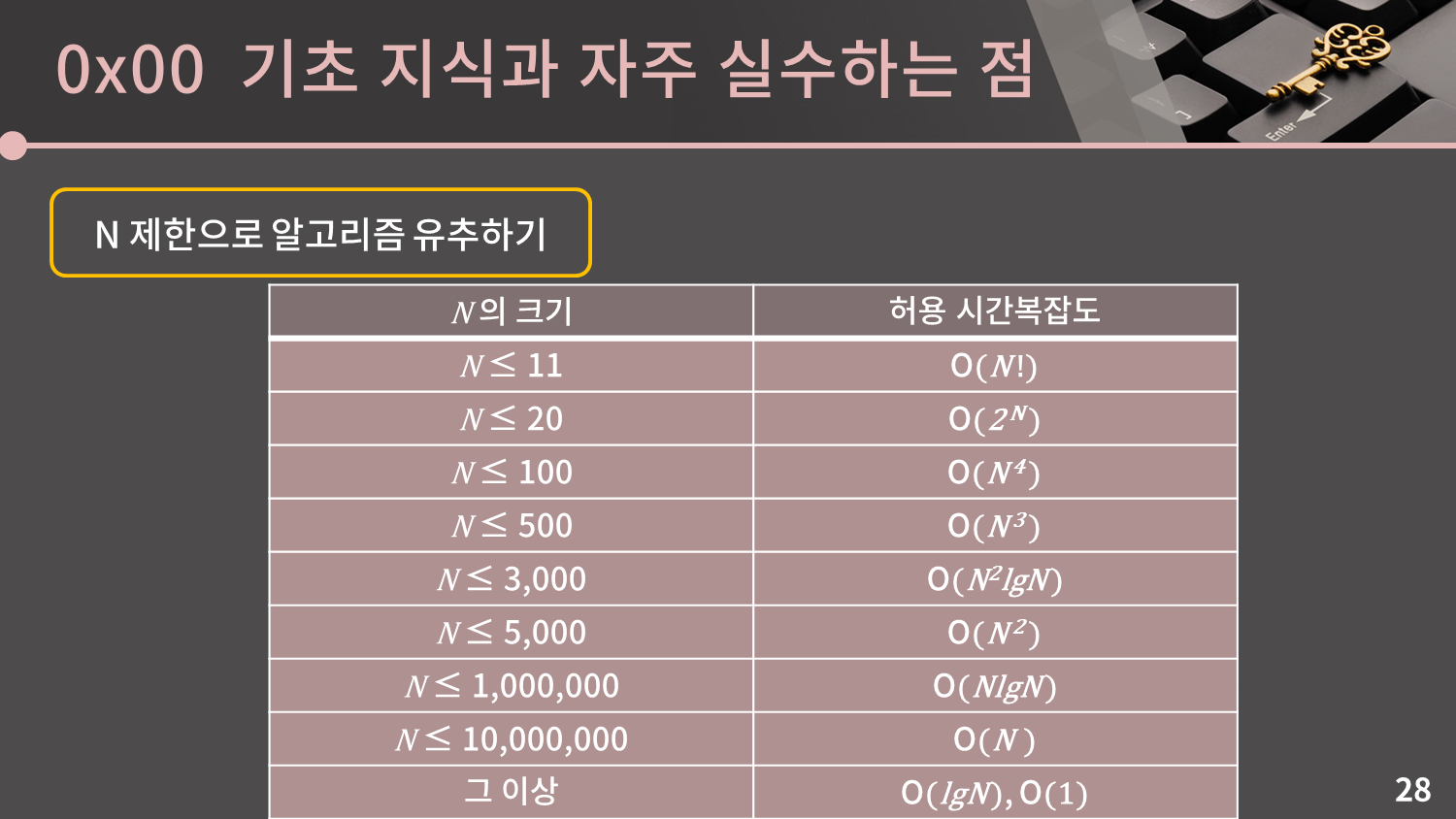 N의 제한으로 알고리즘을 유추하는 것은 굉장히 중요합니다. 엄밀히 말해서 알고리즘을 유추한다기 보다는, 내가 생각한 알고리즘이 이 문제의 N 제한에서 통과될 수 있는가를 판단하는 것입니다.
N의 제한으로 알고리즘을 유추하는 것은 굉장히 중요합니다. 엄밀히 말해서 알고리즘을 유추한다기 보다는, 내가 생각한 알고리즘이 이 문제의 N 제한에서 통과될 수 있는가를 판단하는 것입니다.
컴퓨터는 1초에 대략 1억에서 3억번 정도 연산을 할 수 있습니다. 그 연산이 간단한 비트 연산인지, 아니면 다소 높은 CPU cycle을 요구하는 나누기나 곱하기 등의 연산인지에 따라 다소 차이는 있지만 적당히 어림잡아 계산을 할 때의 이야기입니다.
슬라이드에 나와있는 이 기준이 절대적인 것은 아닙니다. 예를 들어 N이 10,000인데도 가벼운 연산만 들어있을 경우 $O(N^2)$이 통과될 수 있습니다. 반대로 N이 500,000인데도 무거운 연산이 많을 경우 $O(NlgN)$이 시간초과가 발생할 수 있습니다. 그렇기에 이 표를 맹신하지는 마시고 어느 정도의 경향을 파악하는데 사용하시면 됩니다.
 알고리즘 문제를 풀 땐 디버그 모드로 디버깅을 하지 않는 것이 좋습니다. 길어봐야 200줄 안의 짧은 프로그램이고 시간이 촉박하기에 디버그 모드에서 중단점을 정하고 한 줄 한 줄 진행하는 것은 너무 시간 낭비입니다. 디버그 모드 대신 군데군데 출력을 해서 오류를 잡도록 합시다.
알고리즘 문제를 풀 땐 디버그 모드로 디버깅을 하지 않는 것이 좋습니다. 길어봐야 200줄 안의 짧은 프로그램이고 시간이 촉박하기에 디버그 모드에서 중단점을 정하고 한 줄 한 줄 진행하는 것은 너무 시간 낭비입니다. 디버그 모드 대신 군데군데 출력을 해서 오류를 잡도록 합시다.
그러나 디버그 모드는 런타임 에러가 발생하는 입력을 알고 있을 때 굉장히 유용합니다. Visual Studio의 디버그 모드를 활용해 어느 줄에서 오류가 발생했는지 알 수 있습니다.
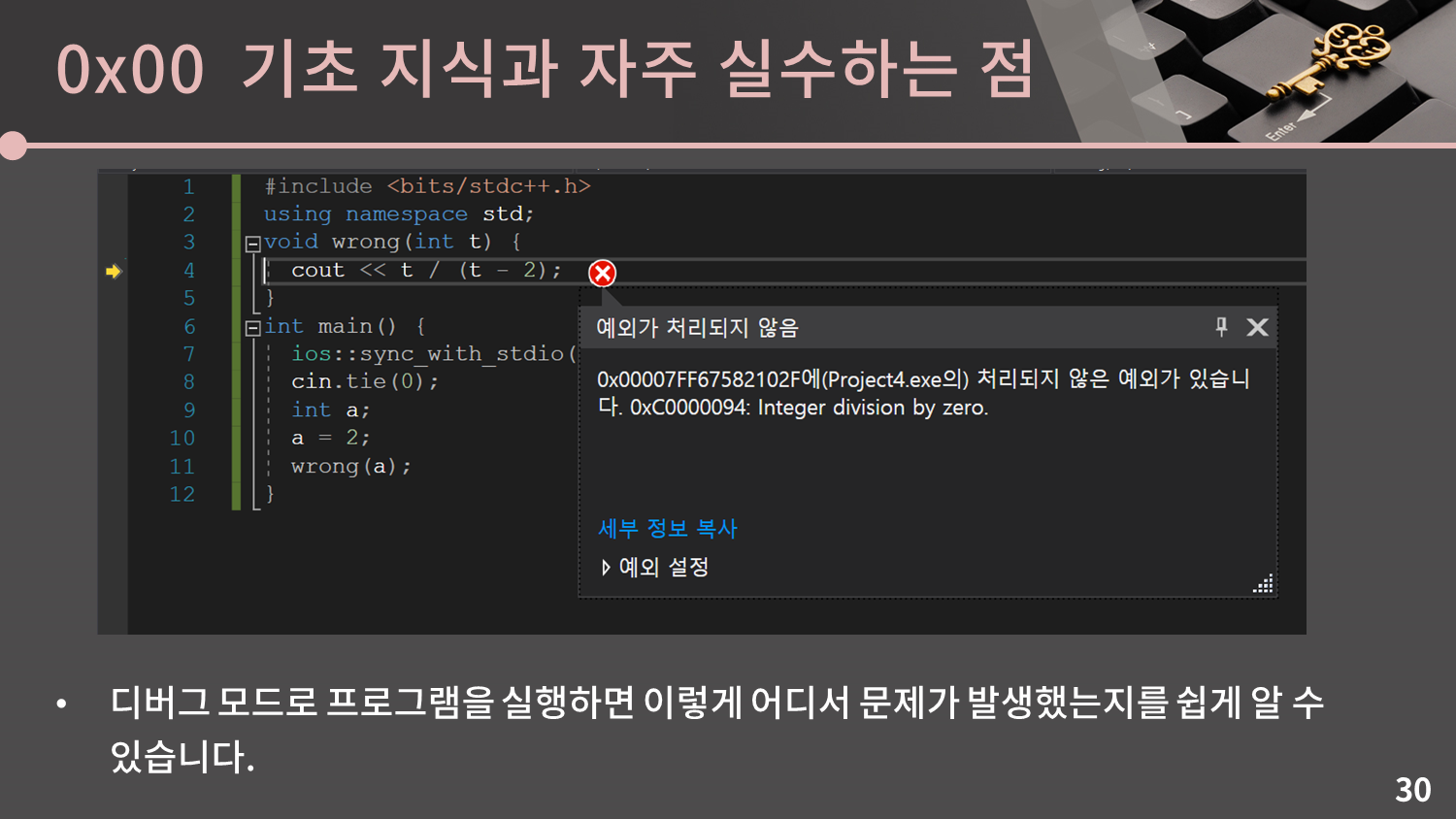 주어진 코드는 2를 0으로 나눈 연산을 수행합니다. 디버그 모드로 프로그램을 실행하면 이처럼 어디서 문제가 발생했는지를 쉽게 알 수 있습니다.
주어진 코드는 2를 0으로 나눈 연산을 수행합니다. 디버그 모드로 프로그램을 실행하면 이처럼 어디서 문제가 발생했는지를 쉽게 알 수 있습니다.
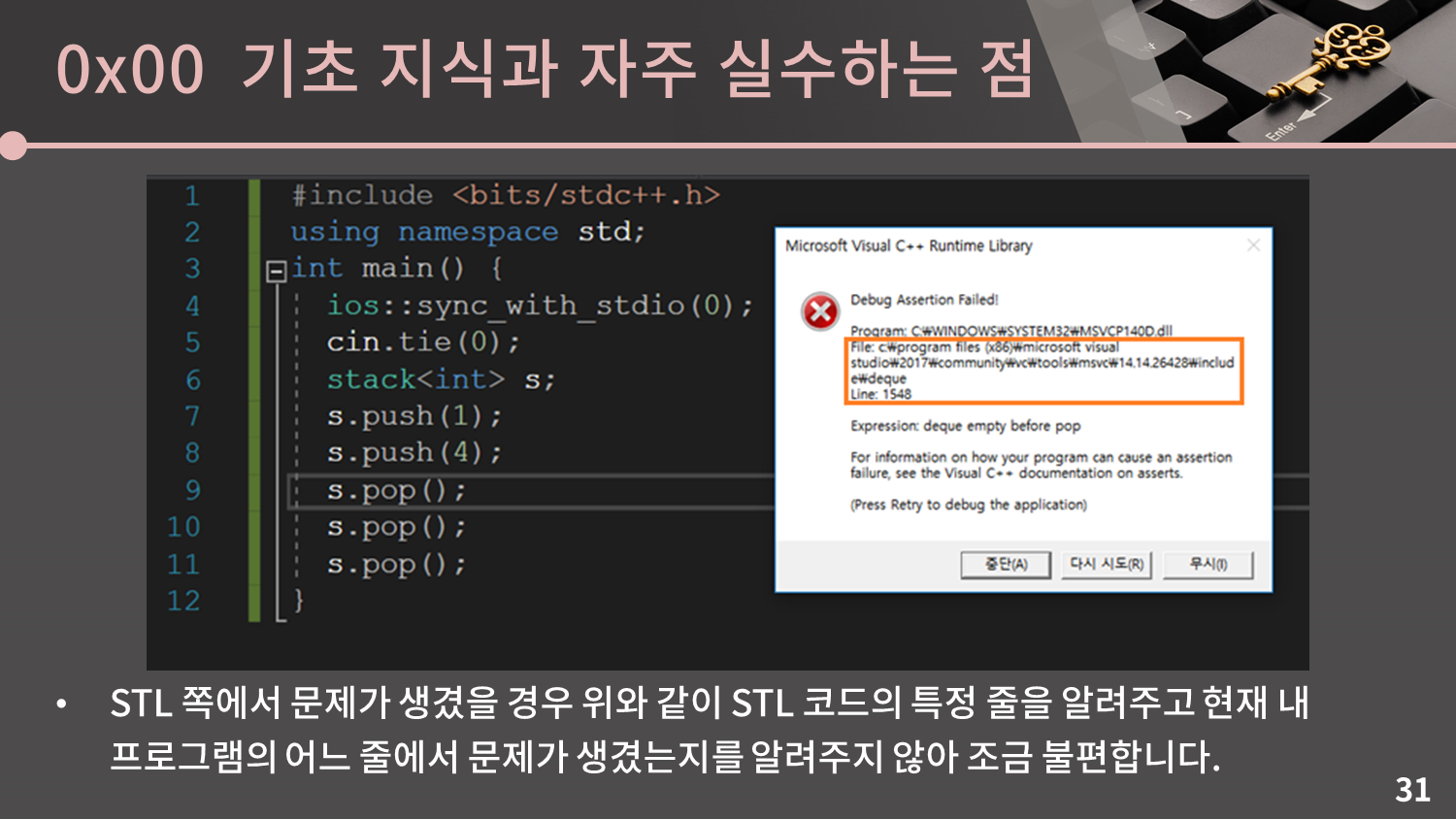 이 코드는 STL 스택에 2번 push한 후 3번 pop하기 때문에 11번 줄에서는 비어있는 스택에 pop 명령을 하게 되어 오류가 발생합니다. 이럴 때 Visual Studio는 STL 코드의 특정 줄에서 문제가 생겼음을 알려주지만 현재 내 프로그램의 어느 줄에서 문제가 생겼는지를 알려주지 않아 조금 불편합니다.
이 코드는 STL 스택에 2번 push한 후 3번 pop하기 때문에 11번 줄에서는 비어있는 스택에 pop 명령을 하게 되어 오류가 발생합니다. 이럴 때 Visual Studio는 STL 코드의 특정 줄에서 문제가 생겼음을 알려주지만 현재 내 프로그램의 어느 줄에서 문제가 생겼는지를 알려주지 않아 조금 불편합니다.
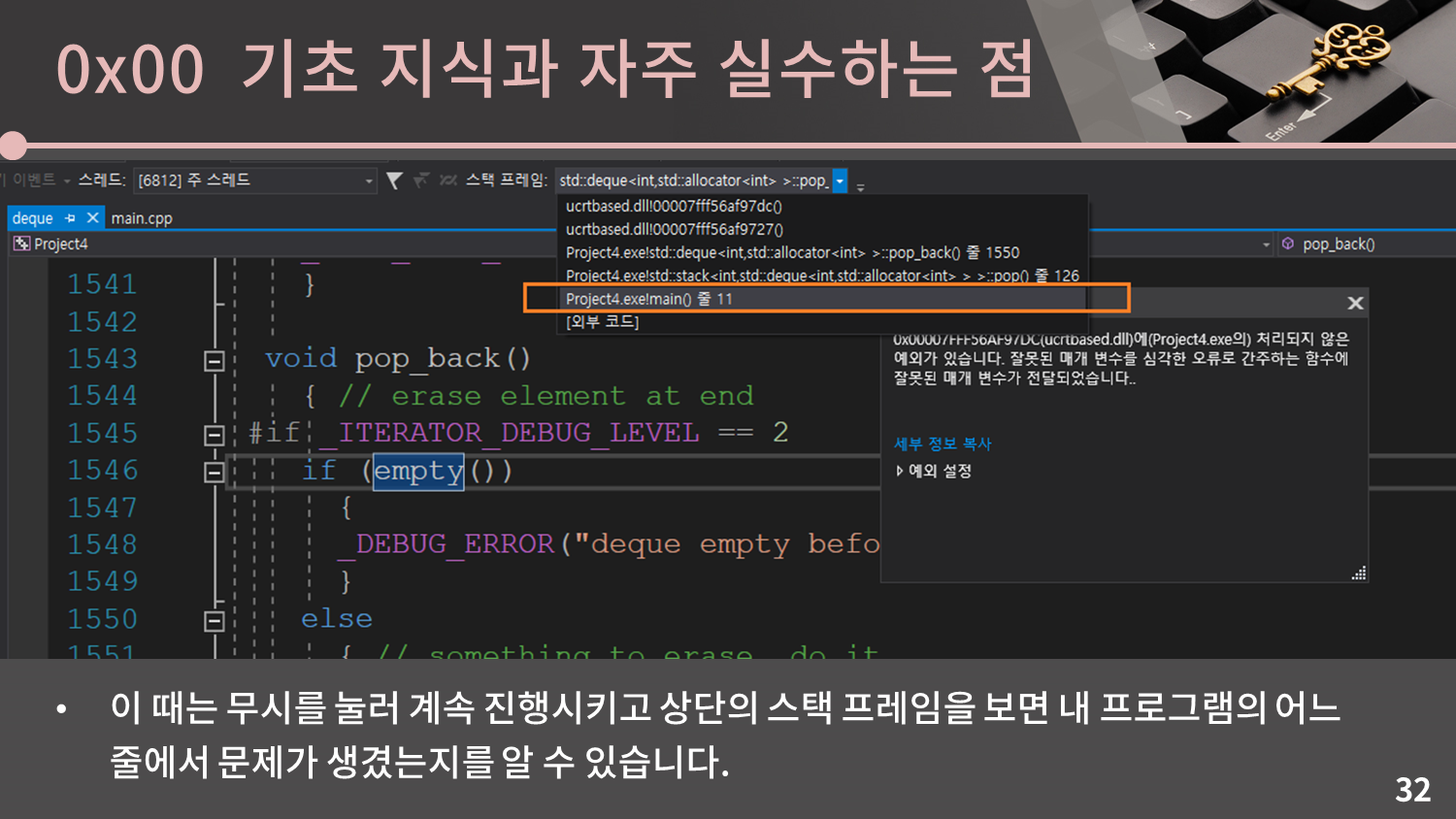 이 때는 무시를 눌러 계속 진행시키고 상단의 스택 프레임을 보면 내 프로그램의 어느 줄에서 문제가 생겼는지를 알 수 있습니다.
이 때는 무시를 눌러 계속 진행시키고 상단의 스택 프레임을 보면 내 프로그램의 어느 줄에서 문제가 생겼는지를 알 수 있습니다.
 코딩테스트에서 로컬에 Visual Studio가 설치되어있는 경우가 많습니다. Visual Studio를 자주 써보았다면 상관없지만 그렇지 않다면 에러메시지의 의미를 파악하지 못해 시간 낭비를 할 수 있습니다. 몇 가지 유명한 에러메시지를 짚고 넘어가겠습니다.
코딩테스트에서 로컬에 Visual Studio가 설치되어있는 경우가 많습니다. Visual Studio를 자주 써보았다면 상관없지만 그렇지 않다면 에러메시지의 의미를 파악하지 못해 시간 낭비를 할 수 있습니다. 몇 가지 유명한 에러메시지를 짚고 넘어가겠습니다.

Error C2872 : ambigiuous symbol(모호한 기호입니다), Error C2365 : redefinition; previous definition was 'function'(재정의: 이전 정의는 '함수'입니다.)
이 두 에러는 std namespace 내에 이미 정의되어 있는 변수/함수/클래스의 이름과 동일한 변수를 선언했을 때 발생할 수 있는 에러입니다. 예를 들어 내가 rank라는 변수를 선언했을 때, std namespace 안에 rank라는 이름의 클래스가 존재하기 때문에 코드 내의 rank가 내가 선언한 변수인지, rank 클래스를 의미하는지 모호해져 발생하는 오류입니다.
이런 에러를 발생시키지 않기 위해 std namespace 안에 어떤 클래스, 함수가 있는지 다 외울 필요는 없고, 그냥 오류가 발생할 경우 변수명을 수정하면 쉽게 해결할 수 있습니다. 예를 들어 앞 글자를 대문자로 만든다거나, 뒤에 언더바를 붙인다거나 하는 방법이 있겠습니다. max, end, hash, map, set, y0, y1, max_element 등의 변수명에서도 마찬가지 오류가 발생합니다.

Error C2065 : undeclared identifier (선언되지 않은 식별자입니다.) 에러는 해당 변수가 선언 전에 사용되었다는 의미입니다. 당황하지 말고 그 변수를 먼저 선언해주시면 됩니다.

Error C4996 : This function or variable may be unsafe(선언되지 않은 식별자입니다.) 에러는 다른 컴파일러에서는 찾아볼 수 없는 에러인데, scanf 함수가 보안 상 취약한 부분이 있기 때문에 이 함수를 사용하지 말라고 하는 에러메시지입니다. #define _CRT_SECURE_NO_WARNINGS 혹은 #pragma warning(disable : 4996) 를 코드 상단에 삽입함으로서 해결할 수 있습니다.
 그 외 자주 실수하는 점들은 슬라이드를 참고하세요. 꼭 이 항목들이 아니더라도 맞왜틀을 해본 본인의 경험을 되새겨봅시다.
그 외 자주 실수하는 점들은 슬라이드를 참고하세요. 꼭 이 항목들이 아니더라도 맞왜틀을 해본 본인의 경험을 되새겨봅시다.
 그 다음으로 다룰 부분은 C++98과 C++11의 차이입니다. 이런 사소한걸 대체 왜 알아야하나 싶을 수도 있는데, 이런 것 때문에 괜히 시간낭비를 할 수도 있습니다. 같은 C++에도 다양한 컴파일러가 존재하고 컴파일러마다 제공하는 함수가 조금씩 다른 경우도 있습니다. 그리고 동일한 컴파일러임에도 불구하고 버전이 올라감에 따라 이전에는 지원되지 않던 기능이 추가로 지원되기도 합니다. 반대로 말하면, 높은 버전에서만 사용할 수 있는 기능을 가지고 코딩을 다 했는데 채점 환경의 버전이 더 낮으면 서버에서 컴파일 에러가 발생해 코드를 갈아엎어야 할 수도 있습니다. 그렇기에 높은 버전에서만 사용할 수 있는 기능들이 무엇인지를 알고 있는 것이 좋습니다.
그 다음으로 다룰 부분은 C++98과 C++11의 차이입니다. 이런 사소한걸 대체 왜 알아야하나 싶을 수도 있는데, 이런 것 때문에 괜히 시간낭비를 할 수도 있습니다. 같은 C++에도 다양한 컴파일러가 존재하고 컴파일러마다 제공하는 함수가 조금씩 다른 경우도 있습니다. 그리고 동일한 컴파일러임에도 불구하고 버전이 올라감에 따라 이전에는 지원되지 않던 기능이 추가로 지원되기도 합니다. 반대로 말하면, 높은 버전에서만 사용할 수 있는 기능을 가지고 코딩을 다 했는데 채점 환경의 버전이 더 낮으면 서버에서 컴파일 에러가 발생해 코드를 갈아엎어야 할 수도 있습니다. 그렇기에 높은 버전에서만 사용할 수 있는 기능들이 무엇인지를 알고 있는 것이 좋습니다.
 C++98, C++03, C++07, C++11, C++14, C++17과 같은 C++ 표준은 ISO에서 주기적으로 정합니다. 그리고 GCC/Clang/MSVC 등의 C++ 컴파일러들은 이 표준을 참고해 버전을 업데이트하면서 기능을 추가합니다. 예를 들어 GCC의 경우 6.x버전 이전에는 기본 컴파일 옵션이 C++98이었고 이후 C++14로 변경되었습니다. 단 C++11, C++14의 기능 자체는 5.x 버전에 다 추가가 되었습니다. 보통 채점 서버는 GCC 컴파일러이고 C++11에서 새로 추가된 기능이 많기 때문에 C++11 이상에서 컴파일을 해주지만 시험 환경에 따라 그렇지 않은 경우도 있습니다. 그리고 로컬에 Visual Studio 2017만 설치되어 있다던가 하는 이유로 애초에 로컬에서 GCC 컴파일러 대신 MSVC로 컴파일을 해야 하는 경우도 있습니다.
C++98, C++03, C++07, C++11, C++14, C++17과 같은 C++ 표준은 ISO에서 주기적으로 정합니다. 그리고 GCC/Clang/MSVC 등의 C++ 컴파일러들은 이 표준을 참고해 버전을 업데이트하면서 기능을 추가합니다. 예를 들어 GCC의 경우 6.x버전 이전에는 기본 컴파일 옵션이 C++98이었고 이후 C++14로 변경되었습니다. 단 C++11, C++14의 기능 자체는 5.x 버전에 다 추가가 되었습니다. 보통 채점 서버는 GCC 컴파일러이고 C++11에서 새로 추가된 기능이 많기 때문에 C++11 이상에서 컴파일을 해주지만 시험 환경에 따라 그렇지 않은 경우도 있습니다. 그리고 로컬에 Visual Studio 2017만 설치되어 있다던가 하는 이유로 애초에 로컬에서 GCC 컴파일러 대신 MSVC로 컴파일을 해야 하는 경우도 있습니다.
 코딩테스트를 칠 때 MSVC와 GCC 사이에서 동작이 다른 부분은 거의 없습니다. 다만 알고리즘 문제를 풀 때 확실히 차이가 느껴질 수 있는 기능은
코딩테스트를 칠 때 MSVC와 GCC 사이에서 동작이 다른 부분은 거의 없습니다. 다만 알고리즘 문제를 풀 때 확실히 차이가 느껴질 수 있는 기능은 VLA(Variable Length Array)입니다. MSVC는 VLA를 지원하지 않는 반면 GCC는 VLA를 지원합니다.
예를 들어 채점 서버는 GCC이고 C++11 이상을 지원하는 버전인데 개발 환경은 MSVC라고 합시다. 이 경우 로컬에서는 VLA를 사용한 코드에서 컴파일 에러가 발생하나 채점 서버에서는 잘 동작합니다.
 사실 앞의 예시와 같이 로컬에서는 안되는데 채점 서버에서 되는 경우도 바람직하지 않지만 적어도 로컬에서 짠 코드가 채점 서버에서는 잘 돌아가니 그나마 괜찮습니다. 더 심각한 것은 로컬에서는 되는데 채점 서버에서 안되는 경우입니다. 예를 들어 로컬의 환경은 MSVC이고 채점 서버는 GCC, C++98인 상황을 생각해봅시다. C++11에서 추가된 기능을 로컬에서는 사용할 수 있는데 채점 서버에서는 사용할 수 없어 제출시 컴파일 에러가 발생합니다. 이 말은 코드를 다 완성해놓고 다시 다 갈아엎어야 한다는 이야기이죠. 그러므로 C++11에서 추가된 기능을 잘 파악하고 있다가 코딩테스트를 치러 갔을 때 채점 환경을 꼭 물어보고, C++11이 지원되지 않는다고 하면 해당 기능들을 사용하지 않고 코드를 작성해야 합니다. 이제 C++11에서 추가된 기능을 알아봅시다.
사실 앞의 예시와 같이 로컬에서는 안되는데 채점 서버에서 되는 경우도 바람직하지 않지만 적어도 로컬에서 짠 코드가 채점 서버에서는 잘 돌아가니 그나마 괜찮습니다. 더 심각한 것은 로컬에서는 되는데 채점 서버에서 안되는 경우입니다. 예를 들어 로컬의 환경은 MSVC이고 채점 서버는 GCC, C++98인 상황을 생각해봅시다. C++11에서 추가된 기능을 로컬에서는 사용할 수 있는데 채점 서버에서는 사용할 수 없어 제출시 컴파일 에러가 발생합니다. 이 말은 코드를 다 완성해놓고 다시 다 갈아엎어야 한다는 이야기이죠. 그러므로 C++11에서 추가된 기능을 잘 파악하고 있다가 코딩테스트를 치러 갔을 때 채점 환경을 꼭 물어보고, C++11이 지원되지 않는다고 하면 해당 기능들을 사용하지 않고 코드를 작성해야 합니다. 이제 C++11에서 추가된 기능을 알아봅시다.
 첫 번째로는 STL의 선언 과정에서
첫 번째로는 STL의 선언 과정에서 > 2개가 붙어있어도 된다는 점입니다. C++98에서는 > 2개가 붙어있을 때 오류가 발생했지만 C++11에서는 신경쓰지 않아도 됩니다. 그러나 반대로 말하면 C++11이 지원되지 않을 경우 이 부분에 주의를 해야한다는 의미입니다.
 Tuple은 C++11에 추가된 STL입니다. C++98에 2개의 요소를 묶을 수 있는 STL pair가 있었지만 3개 이상의 요소를 묶을 수 있는 Tuple은 없습니다. Tuple을 이용하면 구조체를 작성하지 않고 편하게 여러 요소를 묶어 관리할 수 있고 Tuple 끼리의 크기 비교 또한 사전 순으로 미리 정해져 있기 때문에 정렬이 필요할 때 편하게 사용할 수 있습니다.
Tuple은 C++11에 추가된 STL입니다. C++98에 2개의 요소를 묶을 수 있는 STL pair가 있었지만 3개 이상의 요소를 묶을 수 있는 Tuple은 없습니다. Tuple을 이용하면 구조체를 작성하지 않고 편하게 여러 요소를 묶어 관리할 수 있고 Tuple 끼리의 크기 비교 또한 사전 순으로 미리 정해져 있기 때문에 정렬이 필요할 때 편하게 사용할 수 있습니다.
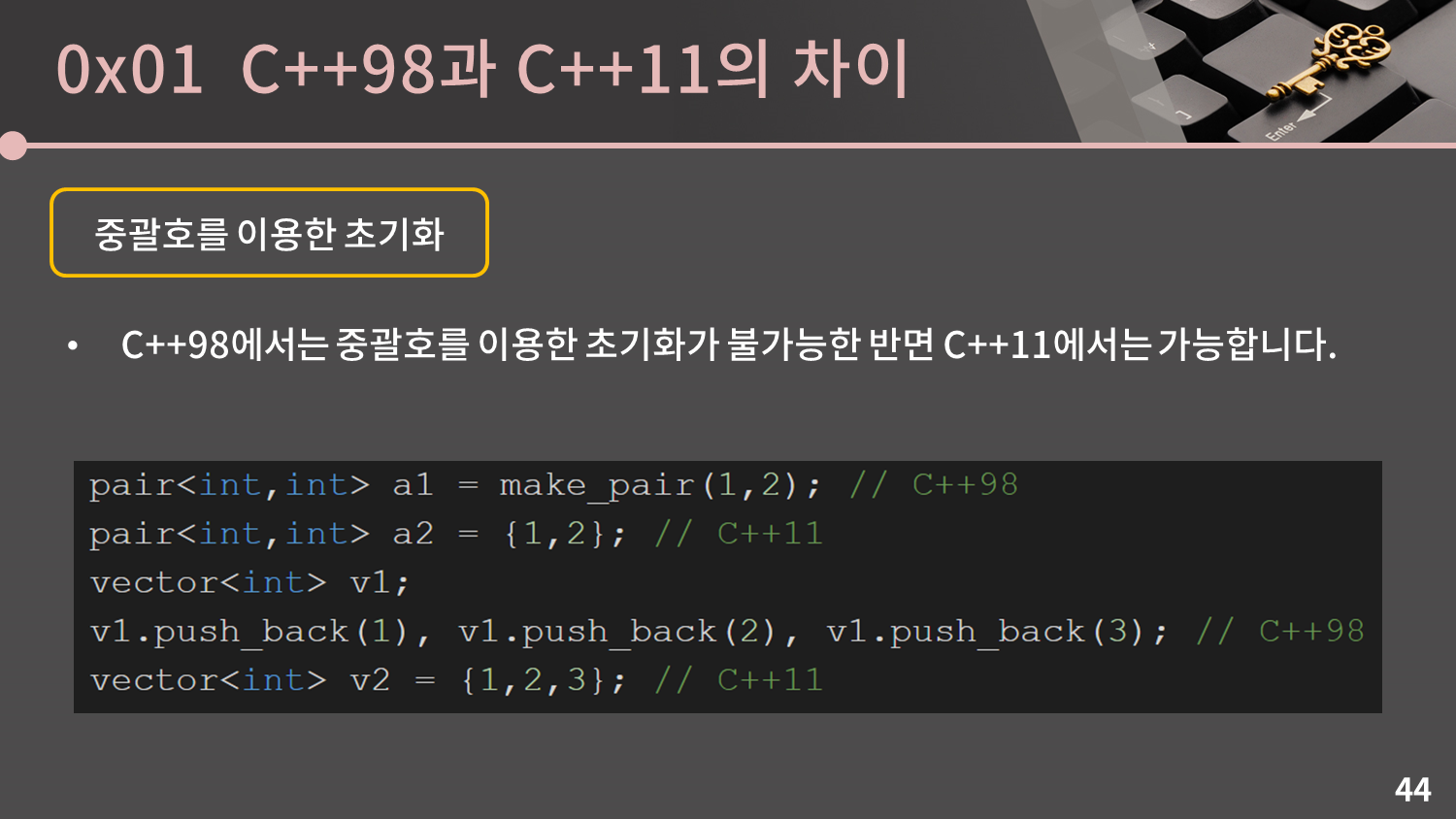 C++98에서는 중괄호를 이용한 초기화가 불가능한 반면 C++11에서는 가능합니다.
C++98에서는 중괄호를 이용한 초기화가 불가능한 반면 C++11에서는 가능합니다.
 C++11에 새로 추가된 tie 함수를 통해 pair, tuple에서 값을 쉽게 뽑아낼 수 있습니다. tuple은 어차피 C++98에 없고, pair는
C++11에 새로 추가된 tie 함수를 통해 pair, tuple에서 값을 쉽게 뽑아낼 수 있습니다. tuple은 어차피 C++98에 없고, pair는 .first 혹은 .second로 간편하게 값을 뽑을 수 있기 때문에 큰 영향이 없긴 합니다.
 C++11에서는 변수의 type을 auto로 지정할 수 있습니다. 그러나 파이썬처럼 변수의 type을 마음대로 바꿀 수 있는 것은 아니고 컴파일을 할 때 auto로 둔 변수의 type이 결정될 수 있어야 하므로 반드시 Initializer가 필요합니다.
C++11에서는 변수의 type을 auto로 지정할 수 있습니다. 그러나 파이썬처럼 변수의 type을 마음대로 바꿀 수 있는 것은 아니고 컴파일을 할 때 auto로 둔 변수의 type이 결정될 수 있어야 하므로 반드시 Initializer가 필요합니다.
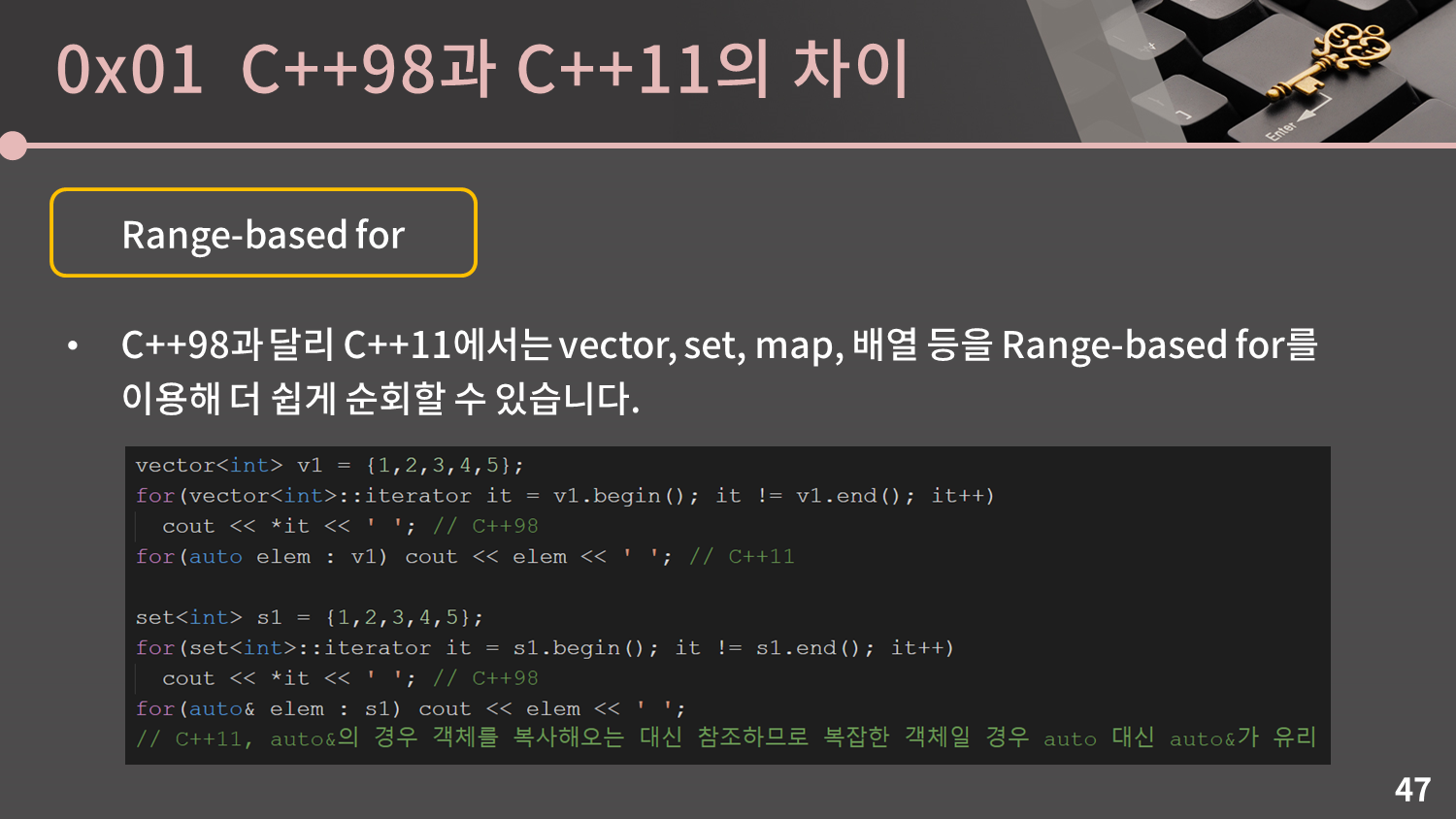 C++98과 달리 C++11에서는 vector, set, map, 배열 등을 Range-based for를 이용해 더 쉽게 순회할 수 있습니다. 앞에서 소개한 auto의 진가가 여기서 드러나게 되는데, 예를 들어 vector를 순회할 때
C++98과 달리 C++11에서는 vector, set, map, 배열 등을 Range-based for를 이용해 더 쉽게 순회할 수 있습니다. 앞에서 소개한 auto의 진가가 여기서 드러나게 되는데, 예를 들어 vector를 순회할 때 V.begin()과 V.end()를 이용해 iterator로 순회를 하고싶다고 하면 C++98에서는 직접 vector<int>::iterator라는 다소 낯선 type을 직접 적어줘야 합니다. 그러나 C++11에서는 슬라이드의 4번째 줄과 같이 auto로 깔끔하게 처리가 가능합니다. 여기서도 참조자를 이용하면 객체를 복사하는 대신 참조할 수 있게 되는데 이 부분을 따로 공부하시는걸 추천드립니다.
 이전까지의 내용은 C/C++ 사용자를 위한 기초 지식들이었습니다. 이제부터는 진짜 알고리즘을 다뤄보도록 하겠습니다. BFS/DFS를 하는 방법 자체는 이미 알고 계신다고 생각하고 여기서 설명하고 가지 않겠습니다. 다차원 배열에서는 BFS 대신 DFS를 사용해야 하는 상황이 존재하지 않습니다.(단, 백트래킹을 해야하는 경우는 예외입니다.) BFS는 Flood Fill과 시작점으로부터의 거리 측정 2가지를 모두 할 수 있지만 DFS는 Flood Fill만 할 수 있기 때문입니다. BFS의 시간복잡도를 잘 모르겠다는 질문을 적어주신 분이 있는데, BFS에서 시간복잡도를 어떻게 계산하면 되는지 알아보겠습니다.
이전까지의 내용은 C/C++ 사용자를 위한 기초 지식들이었습니다. 이제부터는 진짜 알고리즘을 다뤄보도록 하겠습니다. BFS/DFS를 하는 방법 자체는 이미 알고 계신다고 생각하고 여기서 설명하고 가지 않겠습니다. 다차원 배열에서는 BFS 대신 DFS를 사용해야 하는 상황이 존재하지 않습니다.(단, 백트래킹을 해야하는 경우는 예외입니다.) BFS는 Flood Fill과 시작점으로부터의 거리 측정 2가지를 모두 할 수 있지만 DFS는 Flood Fill만 할 수 있기 때문입니다. BFS의 시간복잡도를 잘 모르겠다는 질문을 적어주신 분이 있는데, BFS에서 시간복잡도를 어떻게 계산하면 되는지 알아보겠습니다.
 BFS 코드를 확인하세요. 이 코드는 제 실전 알고리즘 강의에서도 확인할 수 있습니다. 이 코드는 (0, 0)에서 시작해 상하좌우로 인접한 모든 빨간 칸을 방문하는 코드입니다. 빨간 칸은 1에 대응되고 (0, 0)이 빨간 칸임은 보장됩니다. 코드에서 시간복잡도를 파악하기 위해서는 큐에서 원소를 한 번 꺼낼 때 마다 몇 번의 연산을 하는지, 그리고 큐에 원소는 최대 몇 번 들어가게 되는지를 알아야 합니다.
BFS 코드를 확인하세요. 이 코드는 제 실전 알고리즘 강의에서도 확인할 수 있습니다. 이 코드는 (0, 0)에서 시작해 상하좌우로 인접한 모든 빨간 칸을 방문하는 코드입니다. 빨간 칸은 1에 대응되고 (0, 0)이 빨간 칸임은 보장됩니다. 코드에서 시간복잡도를 파악하기 위해서는 큐에서 원소를 한 번 꺼낼 때 마다 몇 번의 연산을 하는지, 그리고 큐에 원소는 최대 몇 번 들어가게 되는지를 알아야 합니다.
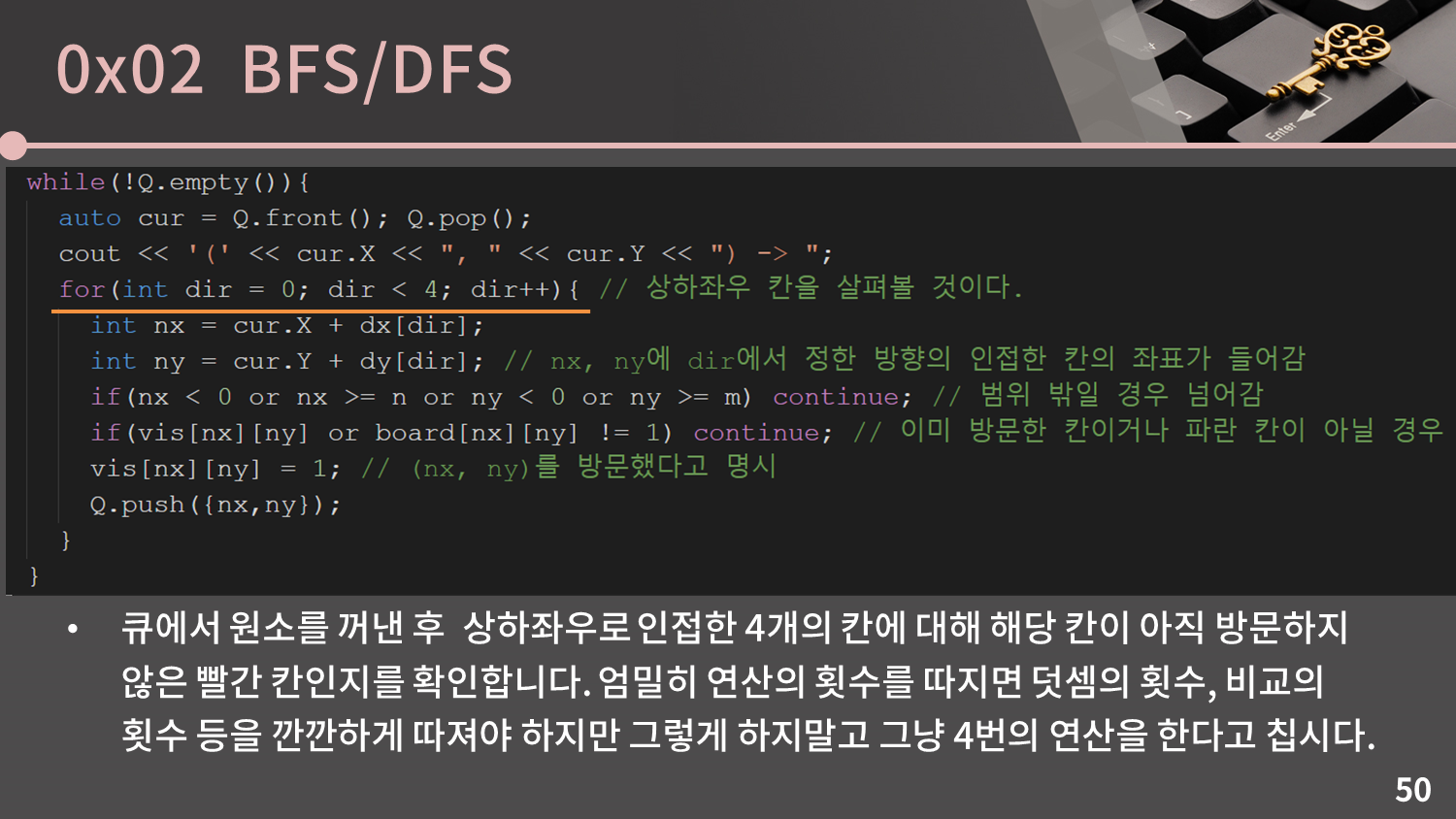 큐에서 원소를 꺼낸 후에는 상하좌우로 인접한 4개의 칸에 대해 해당 칸이 아직 방문하지 않은 빨간 칸인지를 확인합니다. 엄밀히 연산의 횟수를 따지면 덧셈의 횟수, 비교의 횟수 등을 깐깐하게 따져야 하지만 그렇게 하지말고 그냥 4번의 연산을 한다고 칩시다. 즉 큐에서 원소를 한 번 꺼낼 때 마다 4번의 연산을 하는 것입니다.
큐에서 원소를 꺼낸 후에는 상하좌우로 인접한 4개의 칸에 대해 해당 칸이 아직 방문하지 않은 빨간 칸인지를 확인합니다. 엄밀히 연산의 횟수를 따지면 덧셈의 횟수, 비교의 횟수 등을 깐깐하게 따져야 하지만 그렇게 하지말고 그냥 4번의 연산을 한다고 칩시다. 즉 큐에서 원소를 한 번 꺼낼 때 마다 4번의 연산을 하는 것입니다.
 그 다음으로는 전체 while문이 몇 번 돌지 생각해봅시다. 이 말은 곧 큐에서 원소가 몇 번 들어가게 되는지를 의미합니다. (0, 0)과 인접한 모든 빨간 칸은 큐에 들어가고
그 다음으로는 전체 while문이 몇 번 돌지 생각해봅시다. 이 말은 곧 큐에서 원소가 몇 번 들어가게 되는지를 의미합니다. (0, 0)과 인접한 모든 빨간 칸은 큐에 들어가고 vis를 이용해 동일한 칸은 많아야 한 번만 큐에 들어가므로 최대 지도의 크기만큼 큐에 들어가게 됩니다.
 그러므로 세로 $N$, 가로 $M$인 이차원 배열에서의 BFS인 경우 시간복잡도는 $O(NM)$입니다. 각 원소에서 상하좌우 4칸을 확인하는 과정이 있으므로 $O(4NM)$로 적어도 무방합니다.
그러므로 세로 $N$, 가로 $M$인 이차원 배열에서의 BFS인 경우 시간복잡도는 $O(NM)$입니다. 각 원소에서 상하좌우 4칸을 확인하는 과정이 있으므로 $O(4NM)$로 적어도 무방합니다.
사실 정확한 원리를 모르더라도 BFS의 시간복잡도는 워낙 다양한 곳에서 언급되어서 알고 계셨을텐데, 단순 BFS가 아니라 몇 가지 다른 과정들이 추가되면 상당히 헷갈려 하시는 것 같아 BOJ 2146번 : 다리 만들기라는 BFS를 이용한 문제에서 시간복잡도를 같이 계산해보겠습니다. 같이 풀이를 하기 전에 먼저 문제를 풀어보세요.
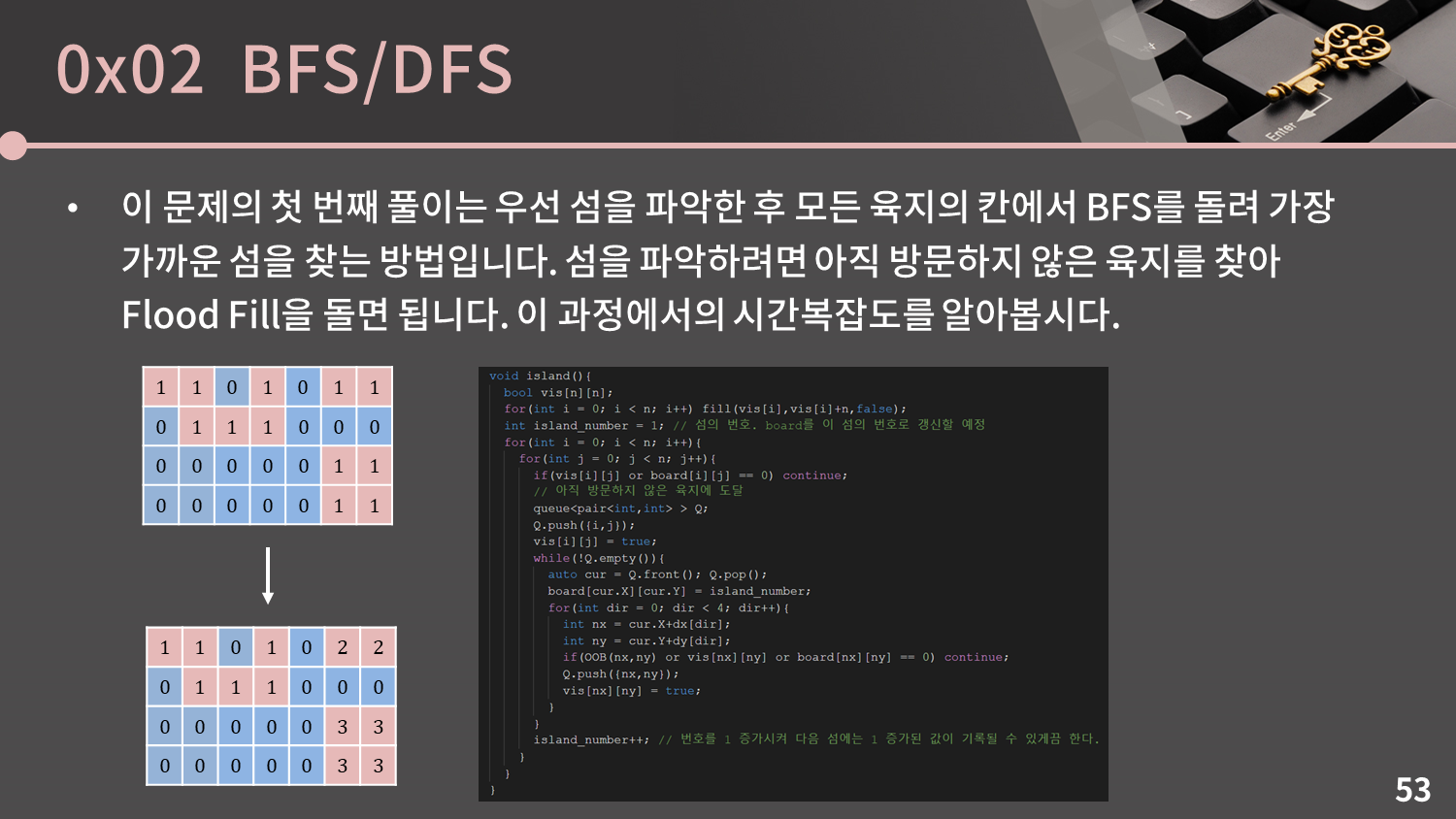 이 문제의 첫 번째 풀이는 우선 섬을 파악한 후 모든 육지의 칸에서 BFS를 돌려 가장 가까운 섬을 찾는 방법입니다. 섬을 파악하려면 아직 방문하지 않은 육지를 찾아 Flood Fill을 돌면 됩니다. 이 과정에서의 시간복잡도를 알아봅시다.
이 문제의 첫 번째 풀이는 우선 섬을 파악한 후 모든 육지의 칸에서 BFS를 돌려 가장 가까운 섬을 찾는 방법입니다. 섬을 파악하려면 아직 방문하지 않은 육지를 찾아 Flood Fill을 돌면 됩니다. 이 과정에서의 시간복잡도를 알아봅시다.
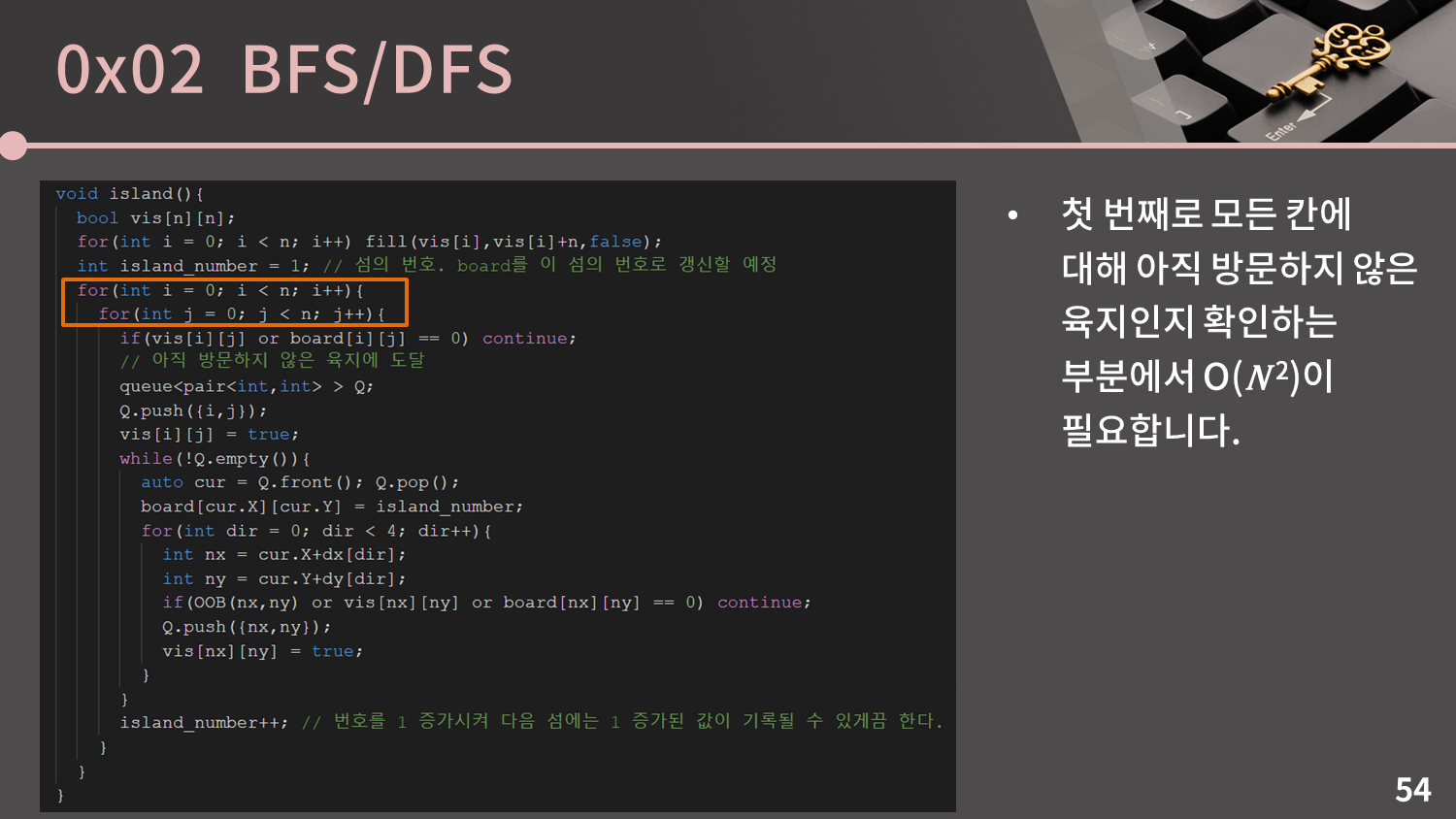 첫 번째로 모든 칸에 대해 아직 방문하지 않은 육지인지 확인하는 부분에서 $O(N^2)$이 필요합니다.
첫 번째로 모든 칸에 대해 아직 방문하지 않은 육지인지 확인하는 부분에서 $O(N^2)$이 필요합니다.
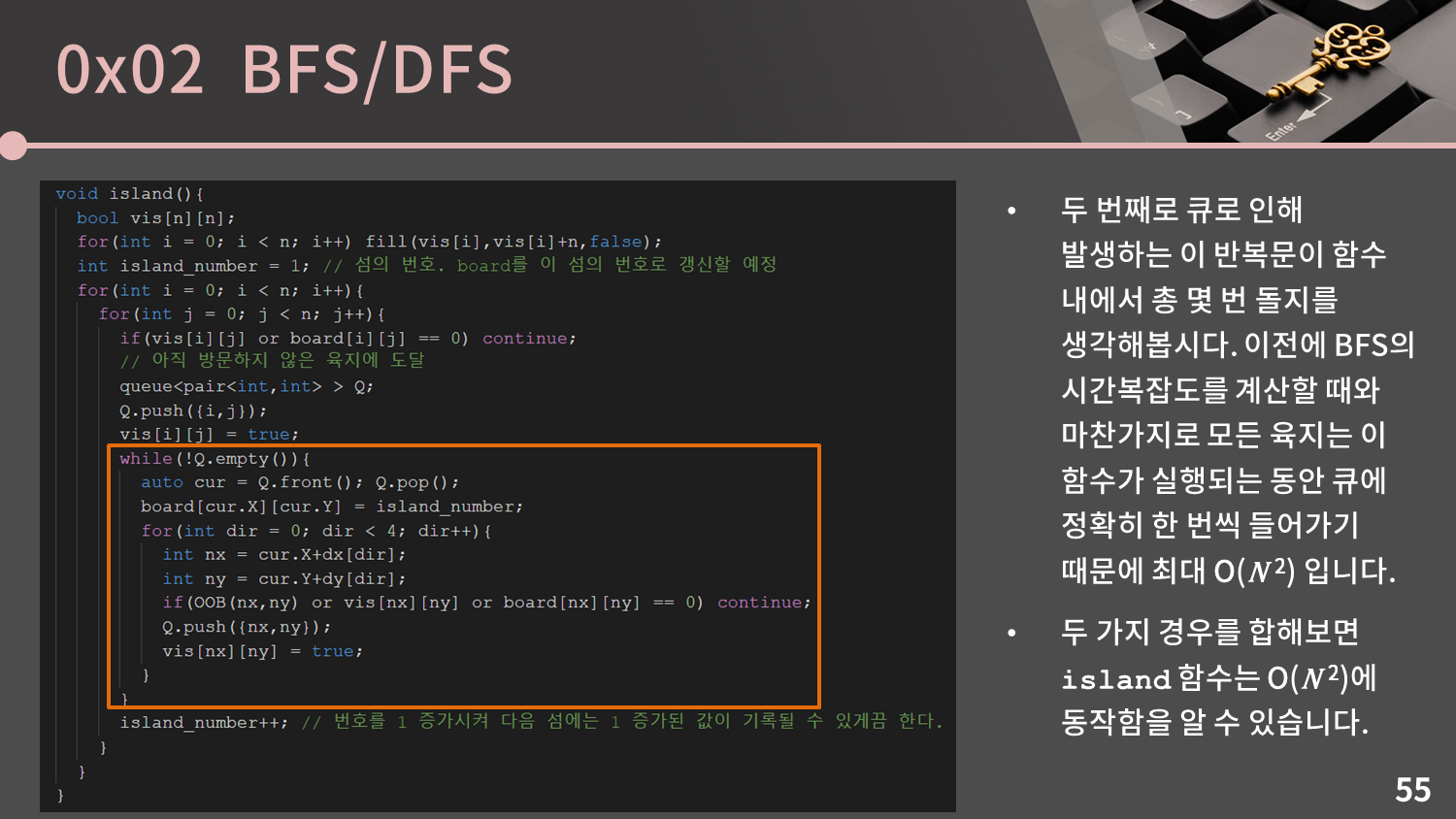 두 번째로 큐로 인해 발생하는 이 반복문이 함수 내에서 총 몇 번 돌지를 생각해봅시다. 이전에 BFS의 시간복잡도를 계산할 때와 마찬가지로 모든 육지는 이 함수가 실행되는 동안 큐에 정확히 한 번씩 들어가기 때문에 최대 $O(N^2)$ 입니다. 이 과정에서 Amortized라는 개념을 잘 알아야하는데, 각 $i, j$에 대해 $O(N^2)$이라는 얘기가 아닙니다. 그렇게 되면 $O(N^4)$가 되겠죠. 각 육지는 단 하나의 $i, j$에서 등장하기 때문에 이 함수가 실행되는 동안 큐에 정확히 한 번씩 들어간다는 의미입니다. 이 두 가지 경우를 합해보면 코드의
두 번째로 큐로 인해 발생하는 이 반복문이 함수 내에서 총 몇 번 돌지를 생각해봅시다. 이전에 BFS의 시간복잡도를 계산할 때와 마찬가지로 모든 육지는 이 함수가 실행되는 동안 큐에 정확히 한 번씩 들어가기 때문에 최대 $O(N^2)$ 입니다. 이 과정에서 Amortized라는 개념을 잘 알아야하는데, 각 $i, j$에 대해 $O(N^2)$이라는 얘기가 아닙니다. 그렇게 되면 $O(N^4)$가 되겠죠. 각 육지는 단 하나의 $i, j$에서 등장하기 때문에 이 함수가 실행되는 동안 큐에 정확히 한 번씩 들어간다는 의미입니다. 이 두 가지 경우를 합해보면 코드의 island 함수는 $O(N^2)$에 동작함을 알 수 있습니다.
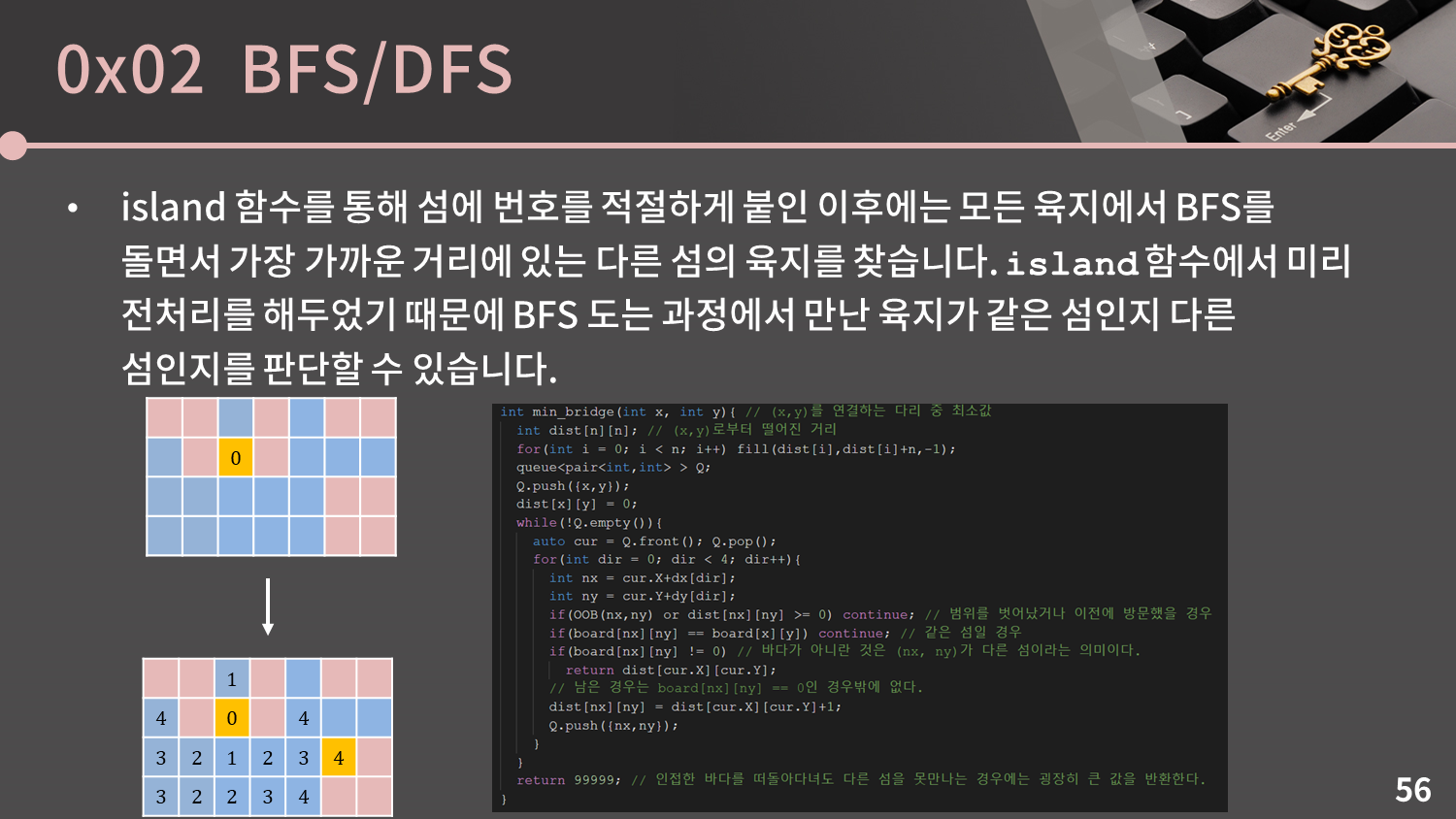
island 함수를 통해 섬에 번호를 적절하게 붙인 이후에는 모든 육지에서 BFS를 돌면서 가장 가까운 거리에 있는 다른 섬의 육지를 찾습니다. island 함수에서 미리 전처리를 해서 각 칸에 해당 육지가 몇 번 섬인지를 기록해두었기 때문에 BFS 도는 과정에서 만난 육지가 같은 섬인지 다른 섬인지를 판단할 수 있습니다.
 정답 코드를 확인해보세요.
정답 코드를 확인해보세요. min_bridge 함수가 $O(N^2)$에 실행됨은 자명합니다. 각 바다가 최대 1번 큐에 들어가기 때문입니다. 그리고 min_bridge 함수는 모든 육지에 대해 실행되고 육지는 최대 $N^2$개이므로 전체 시간복잡도는 $O(N^4)$로 계산할 수 있습니다.
$N = 100$이라 $O(N^4)$이면 살짝 애매하지 않을까 싶은데 실제로 구현을 해보면 결론적으로 잘 통과됩니다. 요새 컴퓨터의 성능이 많이 발전했네요. 여기서 만족하고 넘어가도 되지만 사실 이 문제에서 배울 수 있는 점이 굉장히 많습니다. 이 풀이를 한번 개선해봅시다.
 첫 번째 개선 사항은 바로 같은 섬에 속한 육지에 대해 BFS를 동시에 돌리는 것입니다. 우리는 여러 개의 시작점에서 BFS를 돌리고 싶을 경우 그냥 일단 큐에 전부 넣고, 이후로는 그냥 늘 하던대로 하면 된다는 것을 알고 있습니다(BOJ 5427번 : Fire, BOJ 7576번 : 토마토 참고). 이 문제에서도 마찬가지로 같은 섬에 속한 육지에 대해, 각 육지를 따로 BFS를 돌리는 것 보다는 동시에 BFS를 돌리는 것이 더 효율적입니다.
첫 번째 개선 사항은 바로 같은 섬에 속한 육지에 대해 BFS를 동시에 돌리는 것입니다. 우리는 여러 개의 시작점에서 BFS를 돌리고 싶을 경우 그냥 일단 큐에 전부 넣고, 이후로는 그냥 늘 하던대로 하면 된다는 것을 알고 있습니다(BOJ 5427번 : Fire, BOJ 7576번 : 토마토 참고). 이 문제에서도 마찬가지로 같은 섬에 속한 육지에 대해, 각 육지를 따로 BFS를 돌리는 것 보다는 동시에 BFS를 돌리는 것이 더 효율적입니다.
두 번째로, 이전에는 dist 배열을 매번 초기화해주는 과정이 필요했는데 이를 해결할 수 있는 아이디어가 있습니다. 우선 거리는 dist 배열 대신 큐에 좌표와 거리를 같이 넣는 방식으로 관리하고, 방문했는지 여부를 vis 배열로 체크합니다. 이 vis 배열에서 방문 표시는 min_bridge 함수가 호출될 때 마다 다른 값으로 하도록 하면 vis 배열을 초기화할 필요가 없어집니다.
모든 개선사항을 적용한 코드를 확인해보세요.
 두 번째 풀이는 $O(N^2)$에 깔끔하게 풀이가 가능한 풀이입니다. 이 풀이는 우선 섬을 파악한 후, 모든 섬에서 동시에 BFS를 돌려 섬의 영역을 확장하다가 껍데기끼리 겹쳐지는 순간을 찾는 방식입니다. 편의상 세 섬의 색을 달리 표현하겠습니다. 정답 코드를 확인해보세요. 여기서 주황색으로 표시된 곳이 만나는 부분들인데, 진한 주황과 옅은 주황은 전 단계의 모양을 참고해 무슨 차이가 있을지 고민해보세요.
두 번째 풀이는 $O(N^2)$에 깔끔하게 풀이가 가능한 풀이입니다. 이 풀이는 우선 섬을 파악한 후, 모든 섬에서 동시에 BFS를 돌려 섬의 영역을 확장하다가 껍데기끼리 겹쳐지는 순간을 찾는 방식입니다. 편의상 세 섬의 색을 달리 표현하겠습니다. 정답 코드를 확인해보세요. 여기서 주황색으로 표시된 곳이 만나는 부분들인데, 진한 주황과 옅은 주황은 전 단계의 모양을 참고해 무슨 차이가 있을지 고민해보세요.
 마찬가지로 큐 안에 모든 영역이 최대 1번씩 들어감을 이용해 $O(N^2)$임을 알 수 있습니다. 여러 개의 시작점에서 BFS를 돌리는 것을 이번에 처음 보셨다면 조금 헷갈릴 수 있으니 코드를 참고해 직접 코딩해보세요. 여러 개의 시작점에서 BFS를 돌리는 방식으로 구현해야 하는 문제인 BOJ 5427번 : Fire을 먼저 풀어보신다면 도움이 될 것입니다.
마찬가지로 큐 안에 모든 영역이 최대 1번씩 들어감을 이용해 $O(N^2)$임을 알 수 있습니다. 여러 개의 시작점에서 BFS를 돌리는 것을 이번에 처음 보셨다면 조금 헷갈릴 수 있으니 코드를 참고해 직접 코딩해보세요. 여러 개의 시작점에서 BFS를 돌리는 방식으로 구현해야 하는 문제인 BOJ 5427번 : Fire을 먼저 풀어보신다면 도움이 될 것입니다.
만약 인접한 곳이 다른 섬인 곳을 찾았을 때 dist[nx][ny]+dist[cur.X][cur.Y]으로 계산된 값을 바로 출력하고 종료하면 틀린 답을 출력할 수 있습니다. 어떤 경우에 이러한 일이 생길지 고민해보세요.
 백트래킹은 정말 헷갈립니다. 그리고 달리 왕도가 없습니다. 이건 어쩔 수가 없습니다. 어떤 인자를 둘 것인지, 각 함수에서는 어디까지 계산하고 다음으로 넘길지를 각 문제의 상황에 맞게 잘 설정해야 합니다. 이를 위해서는 처음에 익숙하지 않으면 다른 사람의 코드를 참고해 구조를 습득하고, 이후엔 다양한 문제를 계속 풀어보는 방법 밖에 없습니다. 그룹 내의 문제집에 있는 문제들을 정복해보세요.
백트래킹은 정말 헷갈립니다. 그리고 달리 왕도가 없습니다. 이건 어쩔 수가 없습니다. 어떤 인자를 둘 것인지, 각 함수에서는 어디까지 계산하고 다음으로 넘길지를 각 문제의 상황에 맞게 잘 설정해야 합니다. 이를 위해서는 처음에 익숙하지 않으면 다른 사람의 코드를 참고해 구조를 습득하고, 이후엔 다양한 문제를 계속 풀어보는 방법 밖에 없습니다. 그룹 내의 문제집에 있는 문제들을 정복해보세요.
이번 강의에서는 BOJ 9663번 : N-Queen 문제로 예시를 들어 백트래킹을 설명해보도록 하겠습니다.
 가로, 세로, 대각선 방향이 비어있는지를 배열로 두어 백트래킹을 하는 방법은 이미 실전 알고리즘 강의 내에서 소개를 했기 때문에 여기서 다시 언급하고 가지는 않겠습니다. 코드를 참고하세요.
가로, 세로, 대각선 방향이 비어있는지를 배열로 두어 백트래킹을 하는 방법은 이미 실전 알고리즘 강의 내에서 소개를 했기 때문에 여기서 다시 언급하고 가지는 않겠습니다. 코드를 참고하세요.
이 코드보다 속도는 느리지만 조금 더 간편하게 구현할 수 있는 방법은 각 행에서 퀸을 어느 열에 배치했는지만 가지고 가면서 새로운 퀸을 놓을 때 이전에 놓은 모든 퀸을 확인해 올바른 위치를 판단하는 방법입니다. 코드 만약 일단 퀸을 다 놓고 서로 공격 가능한 위치에 있는 퀸이 있는지를 확인한다면 $O(N^N)$이기 때문에 시간 초과가 발생합니다. 코드
 3번 방법은 $O(N^N)$이니 시간초과가 나는게 당연한데, 1번과 2번 방법의 경우 시간복잡도가 잘 가늠이 안갑니다. 대충 생각했을 때 0행에는 $N$군데에 놓을 수 있고 1행에는 $N-1$ 혹은 $N-2$군데에 놓을 수 있을텐데, 가지치기가 계속 일어나기 때문에 헷갈립니다.
3번 방법은 $O(N^N)$이니 시간초과가 나는게 당연한데, 1번과 2번 방법의 경우 시간복잡도가 잘 가늠이 안갑니다. 대충 생각했을 때 0행에는 $N$군데에 놓을 수 있고 1행에는 $N-1$ 혹은 $N-2$군데에 놓을 수 있을텐데, 가지치기가 계속 일어나기 때문에 헷갈립니다.
이런 문제는 일단 $N$ 제한이 14 이하이니 백트래킹 문제일 것이라는 확신을 가지고 일단 구현을 한 후, 로컬에서 오래 걸릴 것 같은 예제를 넣을 때 걸리는 시간을 확인해 시간 제한에 걸릴 것 같으면 최적화를 할 수 있는 방법을 계속 고민하면 됩니다. 예를 들어 지금 다루는 N-Queen 문제에서는 $N=14$를 넣어보면 될 것입니다.
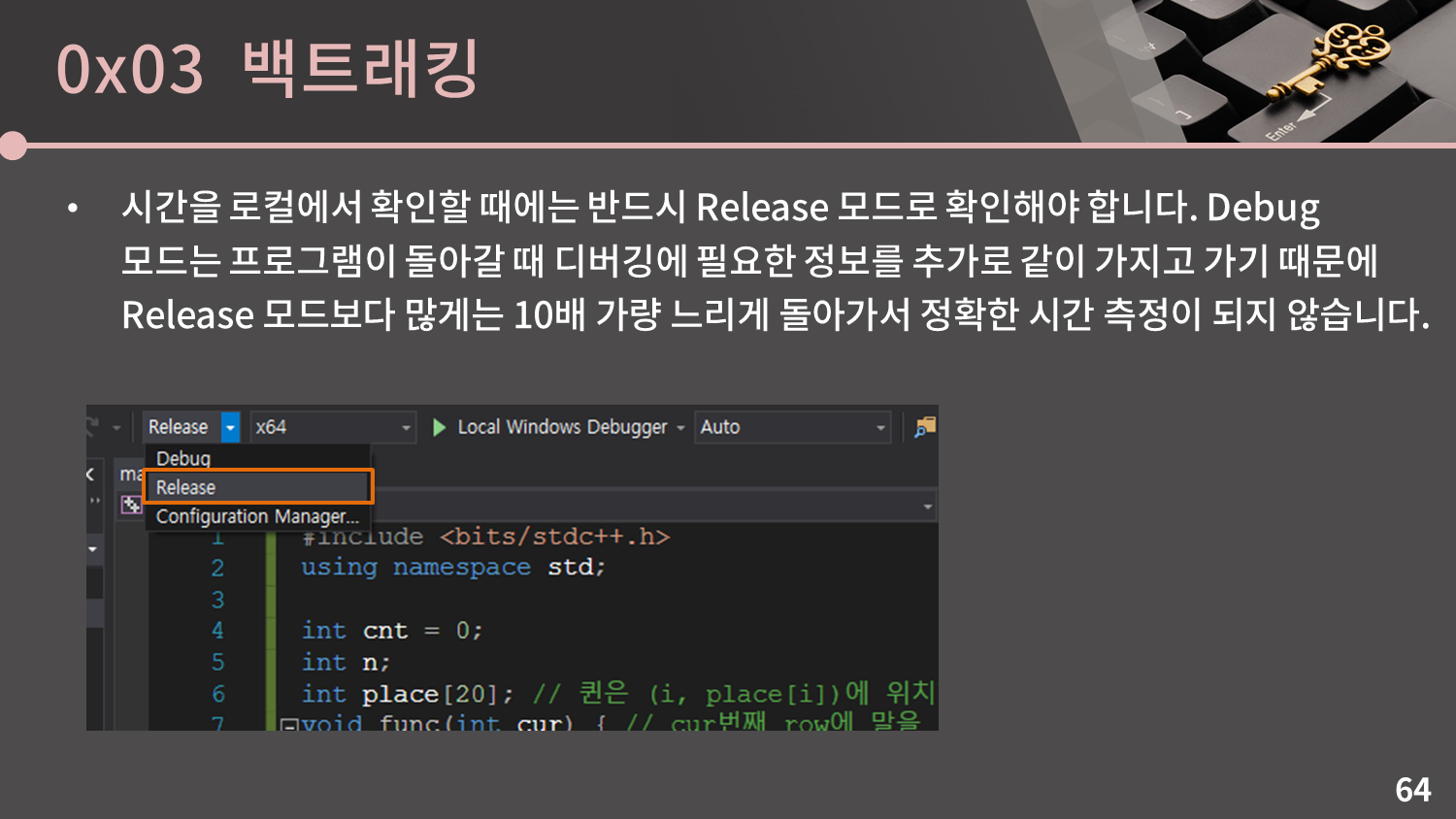 시간을 로컬에서 확인할 때에는 반드시 Release 모드로 확인해야 합니다. Debug 모드는 프로그램이 돌아갈 때 디버깅에 필요한 정보를 추가로 같이 가지고 가기 때문에 Release 모드보다 많게는 10배 가량 느리게 돌아가서 정확한 시간 측정이 되지 않습니다.
시간을 로컬에서 확인할 때에는 반드시 Release 모드로 확인해야 합니다. Debug 모드는 프로그램이 돌아갈 때 디버깅에 필요한 정보를 추가로 같이 가지고 가기 때문에 Release 모드보다 많게는 10배 가량 느리게 돌아가서 정확한 시간 측정이 되지 않습니다.
 시뮬레이션 문제는 특정 기능을 구현하거나 전수조사를 하는 등의 다양한 유형이 있고, 종류가 워낙 다양하기 때문에 마땅히 대비를 할 수 있는 방법이 없습니다. 그냥 코딩을 많이 하면 할수록 실수 없이 빠르게 풀 수 있게 됩니다. 단, 시뮬레이션을 풀다 보면 모든 경우의 수를 따져야 하는 상황이 생기는데 이 경우 백트래킹을 이용하는 대신 C++ STL next_permutation이라는 함수를 써서 간단하게 모든 경우의 수를 처리할 수 있습니다. 직접 사용 예시를 확인해보세요.
시뮬레이션 문제는 특정 기능을 구현하거나 전수조사를 하는 등의 다양한 유형이 있고, 종류가 워낙 다양하기 때문에 마땅히 대비를 할 수 있는 방법이 없습니다. 그냥 코딩을 많이 하면 할수록 실수 없이 빠르게 풀 수 있게 됩니다. 단, 시뮬레이션을 풀다 보면 모든 경우의 수를 따져야 하는 상황이 생기는데 이 경우 백트래킹을 이용하는 대신 C++ STL next_permutation이라는 함수를 써서 간단하게 모든 경우의 수를 처리할 수 있습니다. 직접 사용 예시를 확인해보세요.
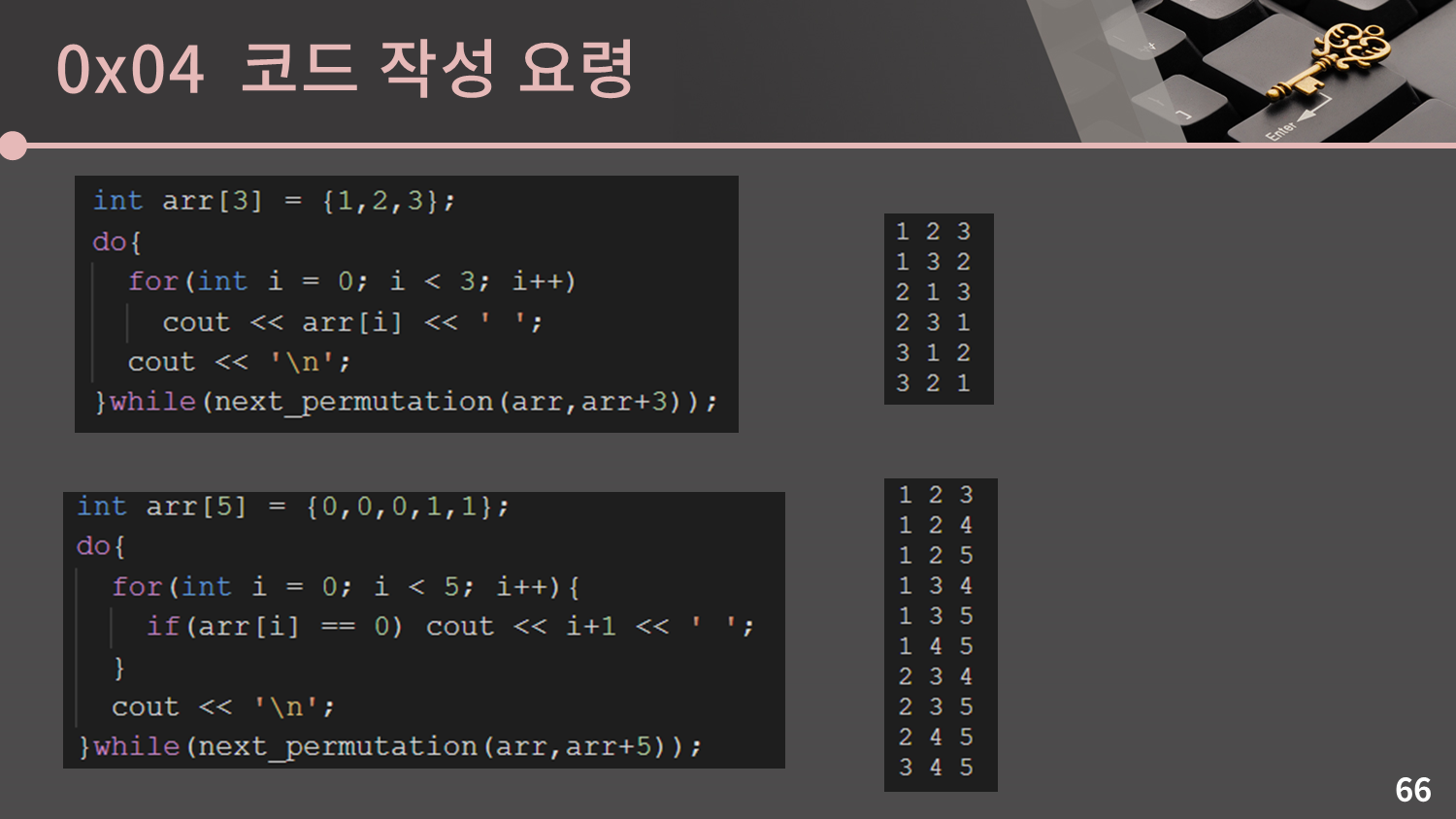
next_permutation함수를 이용해 3개를 줄세우는 경우, 혹은 5개에서 3개를 뽑는 경우 등을 처리할 수 있습니다.
 그리고 3개의 칸에 0, 1, 2를 중복이 허용되는 상황에서 쓰는 문제를 생각해봅시다. 이 문제는 3진법을 이용하면 경우의 수를 쉽게 처리할 수 있습니다. 만약
그리고 3개의 칸에 0, 1, 2를 중복이 허용되는 상황에서 쓰는 문제를 생각해봅시다. 이 문제는 3진법을 이용하면 경우의 수를 쉽게 처리할 수 있습니다. 만약 int tmp = brute;와 같이 brute 변수를 tmp로 복사하는 것이 아니라 brute 변수 자체를 나눠버리면 어떤 일이 생길지 고민해보세요.
 굉장히 좋은 시뮬레이션 문제인 BOJ 15683번 : 감시 문제를 같이 풀어봅시다. 각자 코딩스타일도 다르고 또 어떻게 풀든 답만 맞으면 그만이기에 정해진 길은 없지만, 제가 구현한 방법이 꽤 괜찮은 것 같아 저는 어떤 식으로 이 문제를 해결했는지 소개해드리려고 합니다.
굉장히 좋은 시뮬레이션 문제인 BOJ 15683번 : 감시 문제를 같이 풀어봅시다. 각자 코딩스타일도 다르고 또 어떻게 풀든 답만 맞으면 그만이기에 정해진 길은 없지만, 제가 구현한 방법이 꽤 괜찮은 것 같아 저는 어떤 식으로 이 문제를 해결했는지 소개해드리려고 합니다.
이 문제에서는 결국 각 cctv가 위치할 수 있는 4가지의 방향을 모두 해보면 답을 구할 수 있습니다. 방향을 잡는 것은 진법을 이용한 방법으로 구현했고, 방향을 잡은 후 시뮬레이션을 하는 것은 각 cctv의 종류에 관계없이 공통된 부분을 찾아 구현했습니다.
 cctv가 $K$개라고 할 때
cctv가 $K$개라고 할 때 tmp를 0 부터 $4^K-1$까지로 두어 모든 cctv의 방향을 확인할 수 있습니다. 2, 5번 cctv은 각각 2개와 1개의 방향만 존재하기 때문에 이 두 종류의 cctv에 대해서는 더 적은 방향을 확인해도 되지만 구현의 편의를 위해 처리하지 않았습니다. $4^K$를 계산하기 위해 bit shift 연산을 이용했습니다.
 방향을 잡은 이후에는 실제 시뮬레이션을 해야 합니다. 우선
방향을 잡은 이후에는 실제 시뮬레이션을 해야 합니다. 우선 (x, y)에서 특정 방향으로 진행하며 벽을 만날 때 까지 빈칸(=0)을 7로 바꾸는 upd 함수를 작성했습니다.
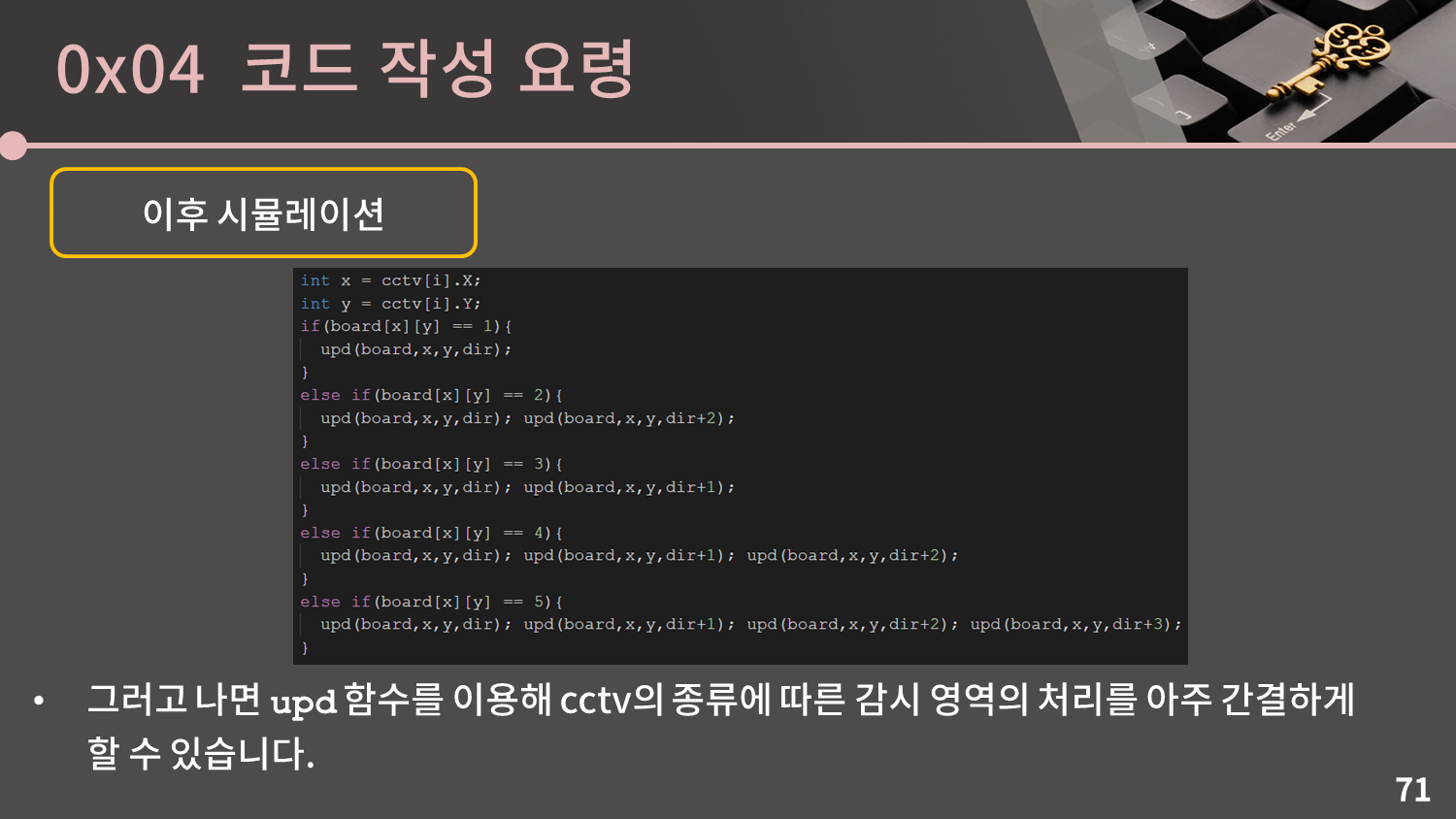 그러고 나면
그러고 나면 upd 함수를 이용해 cctv의 종류에 따른 감시 영역의 처리를 아주 간결하게 처리할 수 있습니다.
 정답 코드를 확인하세요. 메인에서 모든걸 다 처리하는 대신 공통된 부분을 찾아 함수로 빼면 구현도 쉬워지고 코드가 틀렸을 때에도 함수 단위로 테스트를 해볼 수 있다는 장점이 있습니다. 이건 꼭 코딩테스트가 아니라 일반적인 개발에서도 통용되는 이야기입니다.
정답 코드를 확인하세요. 메인에서 모든걸 다 처리하는 대신 공통된 부분을 찾아 함수로 빼면 구현도 쉬워지고 코드가 틀렸을 때에도 함수 단위로 테스트를 해볼 수 있다는 장점이 있습니다. 이건 꼭 코딩테스트가 아니라 일반적인 개발에서도 통용되는 이야기입니다.
 이제 모의고사를 쳐보겠습니다. 이 모의고사의 문제들은 삼성SW역량테스트 A형 정도의 수준으로 제가 직접 만든 문제들입니다. 1일차, 2일차가 있으니 1, 2일차 각각 3시간이 주어졌다고 모의고사를 쳐보세요. 번외 문제는 난이도가 높은 관계로 먼 훗날 도전해보세요. 참고로 이 글을 작성하는 2019년 3월 기준으로 삼성SW역량테스트에서는 내 코드의 채점결과를 알려주지 않습니다. 즉, 사실상 제출 기회가 1번인 것과 다름이 없습니다. 그러니 예제가 나온다고 바로 제출하지 마시고, 직접 만든 다양한 예제로 프로그램이 잘 동작하는지 확인해보세요. 제출 기회가 1번이라고 생각하고 한 문제라도 정확하게 풀어낼 수 있도록 합시다. 다음 슬라이드부터는 바로 각 문제에 대한 풀이가 진행되니 스포일러를 당하고 싶지 않으신 분은 풀이를 보기 전에 꼭 먼저 모의고사를 쳐보세요.
이제 모의고사를 쳐보겠습니다. 이 모의고사의 문제들은 삼성SW역량테스트 A형 정도의 수준으로 제가 직접 만든 문제들입니다. 1일차, 2일차가 있으니 1, 2일차 각각 3시간이 주어졌다고 모의고사를 쳐보세요. 번외 문제는 난이도가 높은 관계로 먼 훗날 도전해보세요. 참고로 이 글을 작성하는 2019년 3월 기준으로 삼성SW역량테스트에서는 내 코드의 채점결과를 알려주지 않습니다. 즉, 사실상 제출 기회가 1번인 것과 다름이 없습니다. 그러니 예제가 나온다고 바로 제출하지 마시고, 직접 만든 다양한 예제로 프로그램이 잘 동작하는지 확인해보세요. 제출 기회가 1번이라고 생각하고 한 문제라도 정확하게 풀어낼 수 있도록 합시다. 다음 슬라이드부터는 바로 각 문제에 대한 풀이가 진행되니 스포일러를 당하고 싶지 않으신 분은 풀이를 보기 전에 꼭 먼저 모의고사를 쳐보세요.
 1일차의 Maaaaaaaaaze 문제에 대한 풀이를 해보겠습니다.일단 큐브의 모양을 만들어놓고 나면 BFS로 해당 큐브를 탈출하는데 필요한 최소 이동 횟수를 알 수 있습니다. 각 판을 쌓는 방법은 $5! = 120$가지이고 판을 쌓는 방법을 고정했을 때 큐브의 모양은 $4^5=1024$가지의 경우가 있습니다. 그러므로 가능한 큐브의 갯수는 122,880개입니다.
1일차의 Maaaaaaaaaze 문제에 대한 풀이를 해보겠습니다.일단 큐브의 모양을 만들어놓고 나면 BFS로 해당 큐브를 탈출하는데 필요한 최소 이동 횟수를 알 수 있습니다. 각 판을 쌓는 방법은 $5! = 120$가지이고 판을 쌓는 방법을 고정했을 때 큐브의 모양은 $4^5=1024$가지의 경우가 있습니다. 그러므로 가능한 큐브의 갯수는 122,880개입니다.
큐브의 꼭짓점은 8개이므로 얼핏 생각할 때 122,880개의 큐브들에 대해서 8개의 꼭짓점을 각각 입구로 두어 다 확인해봐야 하는 것이 아닌가 싶을 수도 있는데, 잘 생각해보면 꼭짓점의 위치를 고정해도 아무 상관이 없음을 알 수 있습니다.
 입구와 출구가 바뀌어도 결과는 동일하기 때문에 우선 8개의 꼭짓점 중 위의 4개만 고려하면 되고, 위의 4개에서도 큐브를 적절히 돌려 시작점을 한 곳으로 보낼 수 있기 때문입니다. 즉
입구와 출구가 바뀌어도 결과는 동일하기 때문에 우선 8개의 꼭짓점 중 위의 4개만 고려하면 되고, 위의 4개에서도 큐브를 적절히 돌려 시작점을 한 곳으로 보낼 수 있기 때문입니다. 즉 (0,0,0)에서 (4,4,4)로 가는 경우만 따지면 됩니다.
BFS에는 최대 $5^3=125$개의 칸을 거치므로 6개의 방향을 살펴봐야 하는 것을 감안해도 122,880×125×6 = 92,160,000으로 2초 안에는 충분히 모든 큐브에 대해 BFS를 돌려 최소 이동 횟수를 알아낼 수 있음을 알 수 있습니다.
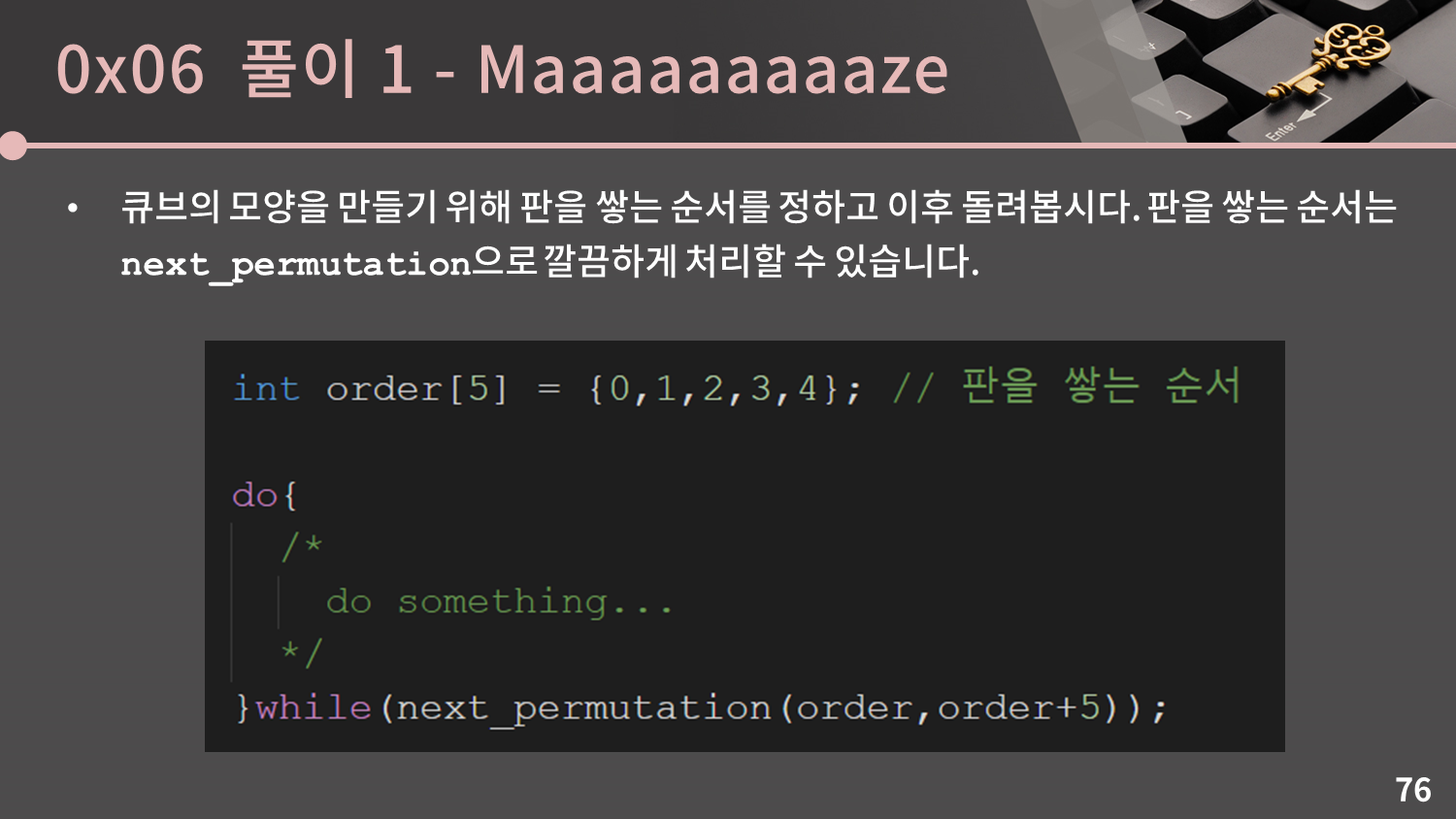 큐브의 모양을 만들기 위해 판을 쌓는 순서를 정하고 이후 돌려봅시다. 판을 쌓는 순서는 앞에서 설명한 next_permutation으로 깔끔하게 처리할 수 있습니다.
큐브의 모양을 만들기 위해 판을 쌓는 순서를 정하고 이후 돌려봅시다. 판을 쌓는 순서는 앞에서 설명한 next_permutation으로 깔끔하게 처리할 수 있습니다.
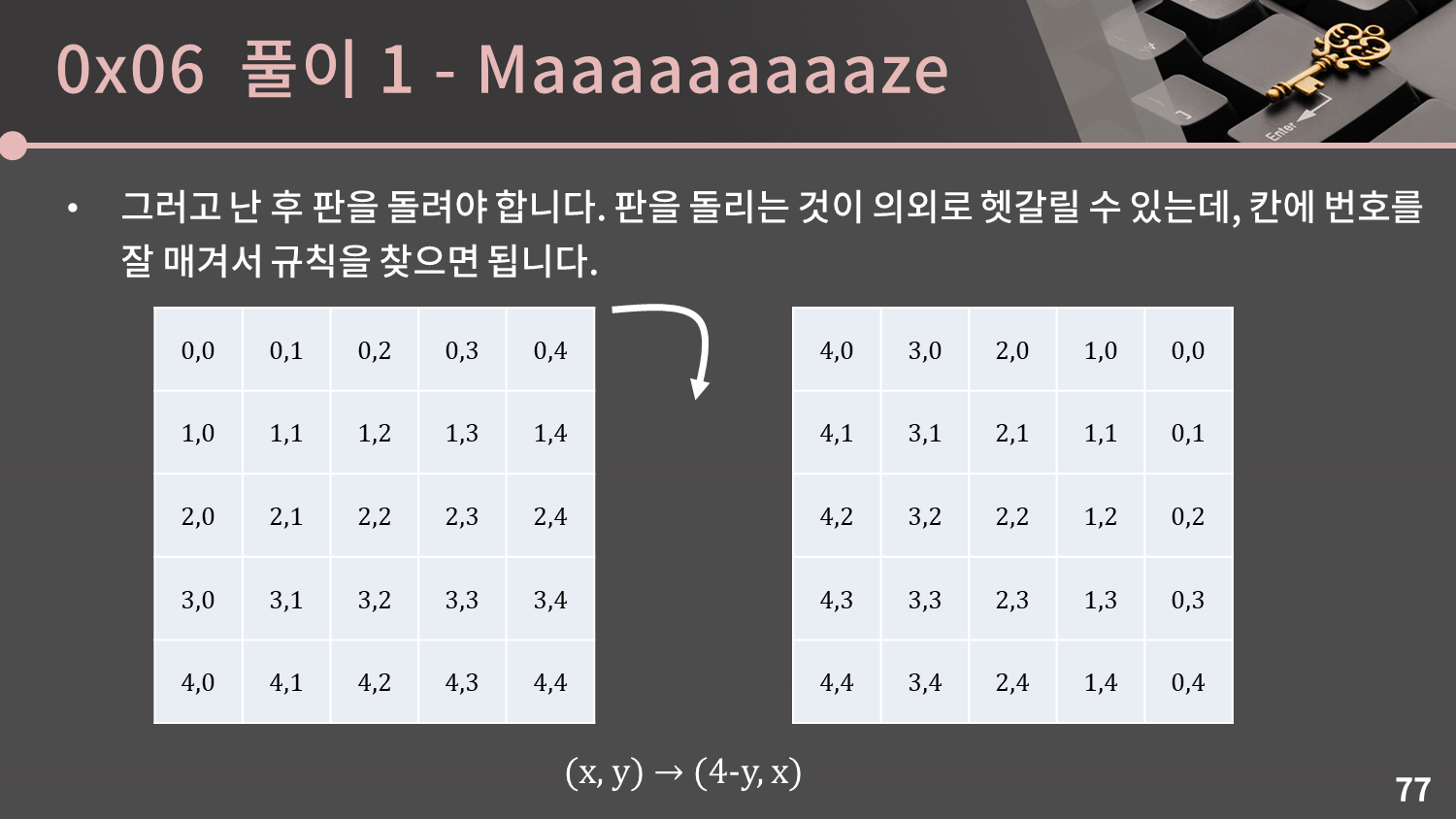 그러고 난 후 판을 돌려야 합니다. 우선 시계 방향으로 90도 돌리는 경우만 생각해봅시다. 판을 돌리는 것이 의외로 헷갈릴 수 있는데, 칸에 번호를 잘 매겨서 규칙을 찾으면 됩니다. 충분히 헷갈릴 수 있는 부분이니 실수하지 않도록 조심해야 합니다.
그러고 난 후 판을 돌려야 합니다. 우선 시계 방향으로 90도 돌리는 경우만 생각해봅시다. 판을 돌리는 것이 의외로 헷갈릴 수 있는데, 칸에 번호를 잘 매겨서 규칙을 찾으면 됩니다. 충분히 헷갈릴 수 있는 부분이니 실수하지 않도록 조심해야 합니다.
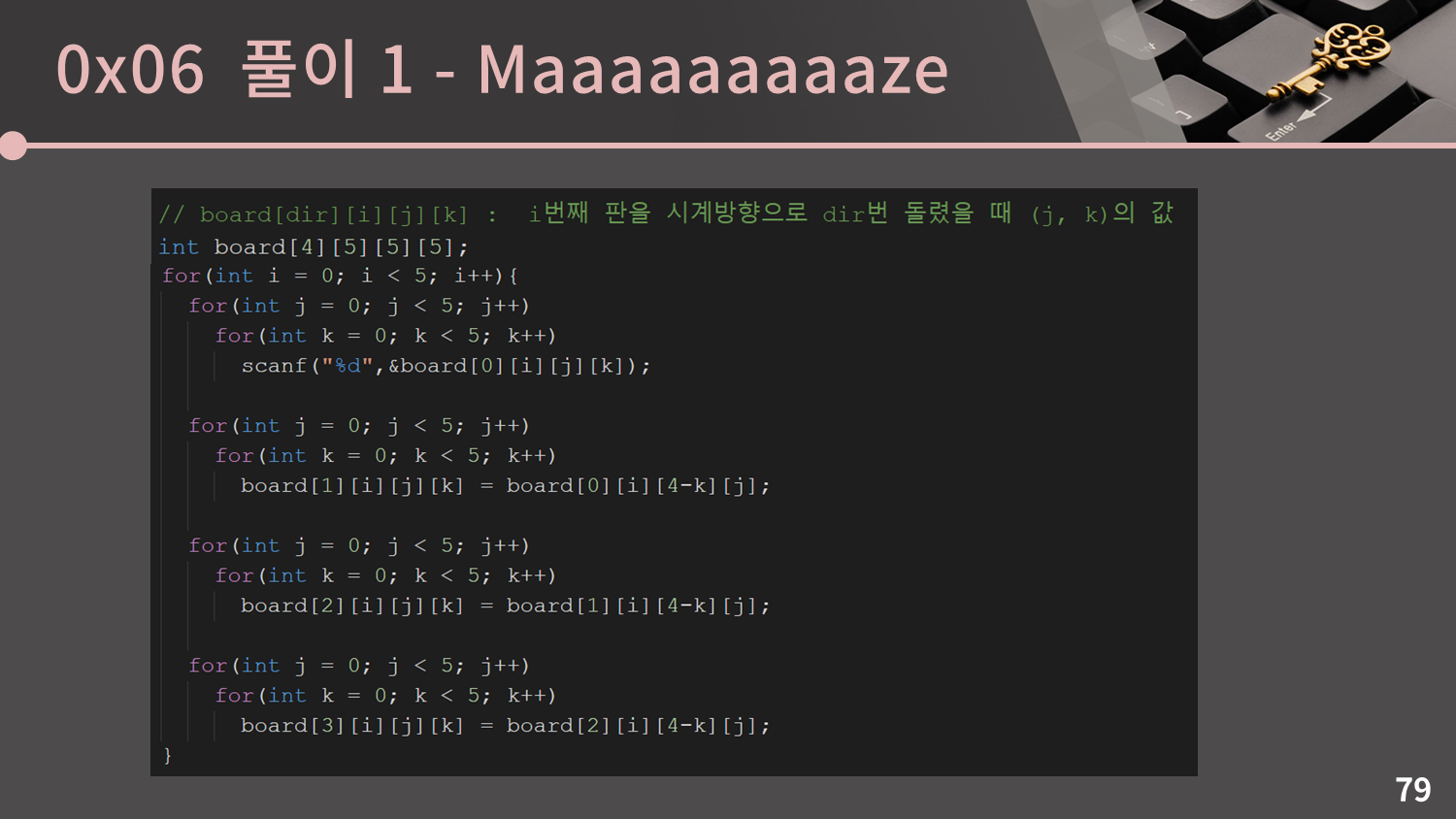
 시계 방향으로 2, 3번 돌렸을 때 좌표가 어떻게 되는지도 알아야 합니다. 그런데 이를 앞에서 한 것 처럼 직접 각 좌표가 어디로 가는지를 계산해 구하는 것 보다는 그냥 1번 돌리는 과정을 여러 번 반복하도록 하는 것이 더 구현하기 편합니다. 더 나아가 회전이 필요할 때 마다 회전을 직접 수행하는 대신, 미리 판을 입력받을 때 1/2/3번 회전한 결과를 따로 저장해두면 코드도 깔끔해지고 수행 시간에서도 이득을 챙길 수 있습니다. 다음 슬라이드의 슬라이드의 코드를 참고해주세요.
시계 방향으로 2, 3번 돌렸을 때 좌표가 어떻게 되는지도 알아야 합니다. 그런데 이를 앞에서 한 것 처럼 직접 각 좌표가 어디로 가는지를 계산해 구하는 것 보다는 그냥 1번 돌리는 과정을 여러 번 반복하도록 하는 것이 더 구현하기 편합니다. 더 나아가 회전이 필요할 때 마다 회전을 직접 수행하는 대신, 미리 판을 입력받을 때 1/2/3번 회전한 결과를 따로 저장해두면 코드도 깔끔해지고 수행 시간에서도 이득을 챙길 수 있습니다. 다음 슬라이드의 슬라이드의 코드를 참고해주세요.
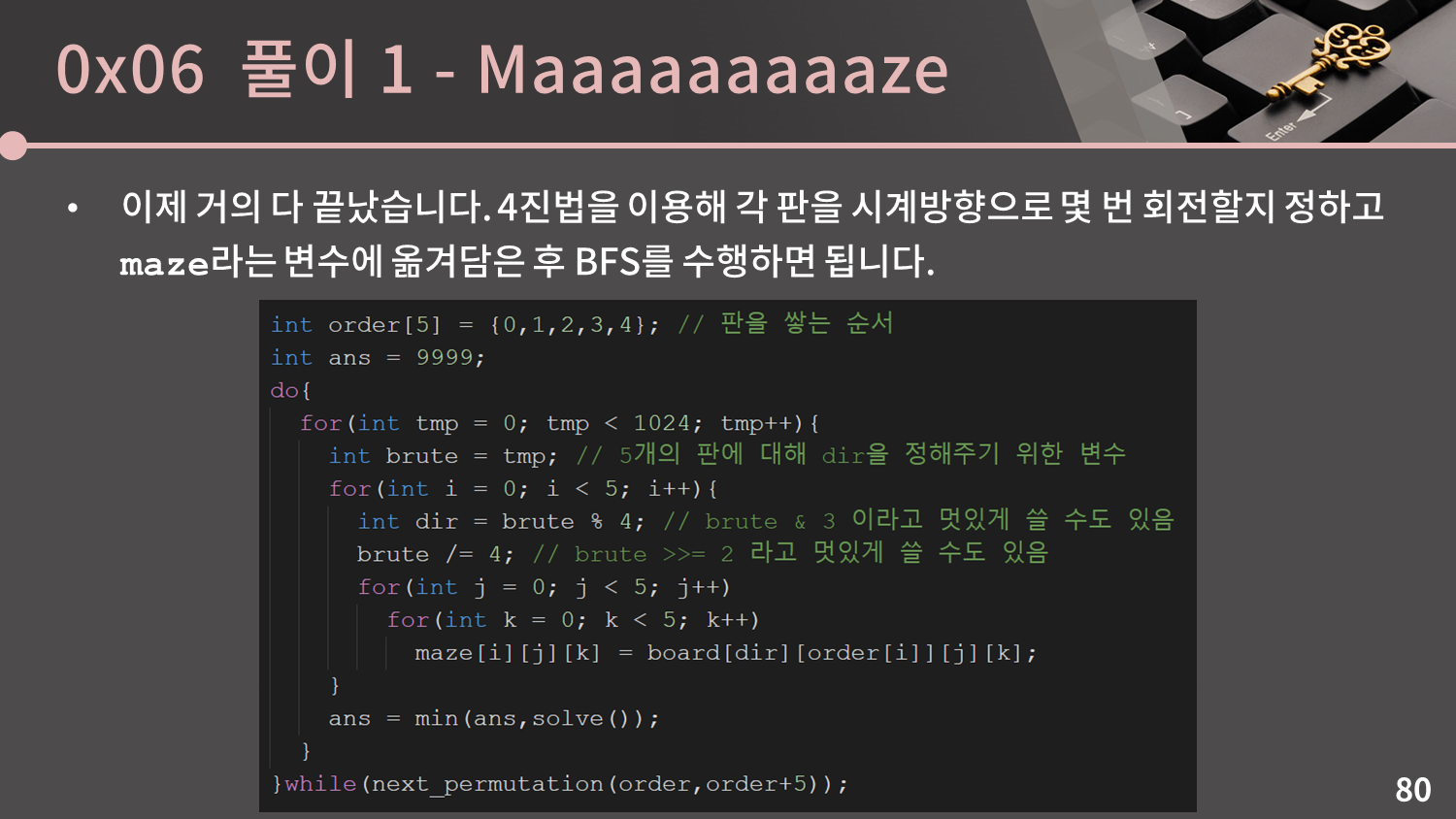 이제 거의 다 끝났습니다. 4진법을 이용해 각 판을 시계방향으로 몇 번 회전할지 정하고 maze라는 변수에 옮겨담은 후 BFS를 수행하면 됩니다.
이제 거의 다 끝났습니다. 4진법을 이용해 각 판을 시계방향으로 몇 번 회전할지 정하고 maze라는 변수에 옮겨담은 후 BFS를 수행하면 됩니다.
 정답 코드를 참고해보세요. 테스트케이스를 충분히 넣었다고 생각했는데 의외로 오답이 많이 발생해 조금 신기했습니다.
정답 코드를 참고해보세요. 테스트케이스를 충분히 넣었다고 생각했는데 의외로 오답이 많이 발생해 조금 신기했습니다.
이 문제는 임의의 테스트케이스에 대해 내가 출력한 답이 올바른지를 직접 확인하는 것이 거의 불가능에 가깝습니다. 그러나 기능을 잘 쪼개어 구현하면 각 기능이 잘 동작하는지 알 수 있습니다. 그렇기 때문에 시간이 널널하다면 판의 위치를 섞지 않고 회전도 하지 않은 채로 그냥 BFS를 돌게 했을 때 제대로 된 값을 내는지, 회전한 결과를 출력했을 때 올바르게 회전이 되고 있는지 등을 반드시 확인해야 합니다.
 두 번째로 인싸들의 가위바위보 문제를 풀이해보겠습니다. 지우가 내는 손동작의 순서는 최대 $N!$개입니다. $9! = 362880$ 이므로 모든 경우에 대해 다 해봐도 충분히 시간 내에 해결이 가능합니다.
두 번째로 인싸들의 가위바위보 문제를 풀이해보겠습니다. 지우가 내는 손동작의 순서는 최대 $N!$개입니다. $9! = 362880$ 이므로 모든 경우에 대해 다 해봐도 충분히 시간 내에 해결이 가능합니다.
이 문제는 백트래킹으로 구현할 수도 있고, next_permutation 함수를 이용한 전수조사로도 구현할 수 있습니다. 중간에 가지치기가 잘 일어나는 백트래킹이 더 효율적이지만 구현 난이도는 전수조사가 훨씬 낮습니다. 그리고 연산이 그다지 많지 않으므로 조금 비효율적이더라도 전수조사로 구현하는 것이 편합니다.
백트래킹의 경우, 지우가 특정 손동작을 냈을 때의 상황을 함수 안에 넣게 되는데 지우가 이기면 그대로 다음 경기를 진행해 한 단계 더 따라 들어가면 되지만 지우가 질 경우 경희와 민호의 경기를 한 번 진행한 후 한 단계 더 따라 들어가야 합니다. 이 과정에서 실수를 하기 쉽습니다.
 먼저 백트래킹으로 구현을 하는 과정을 설명드리겠습니다. 백트래킹으로 구현을 할 땐 함수의 인자로 지우가 어떤 손동작을 선택했는지, 그리고 지우와 붙을 상대가 누구인지를 가져가는 것이 자연스럽습니다. 더 나아가 경희/민호가 몇 번 경기를 진행했는지(
먼저 백트래킹으로 구현을 하는 과정을 설명드리겠습니다. 백트래킹으로 구현을 할 땐 함수의 인자로 지우가 어떤 손동작을 선택했는지, 그리고 지우와 붙을 상대가 누구인지를 가져가는 것이 자연스럽습니다. 더 나아가 경희/민호가 몇 번 경기를 진행했는지(idx)와 지우/경희/민호의 승리 횟수(w)도 알고 있어야 승리 조건이 달성됐는지, 경희/민호가 다음번에 낼 손동작이 무엇인지를 알 수 있습니다.
코드 상에서 isused와 달리 idx, w는 전역변수로 두지 않고 값을 복사하도록 했습니다. 전역변수로 두어도 구현을 할 수는 있지만 중간에 상대가 우승해 함수를 종료하고 넘겨줄 때 굉장히 껄끄러워 값을 복사하도록 했습니다.
 슬라이드의 코드와 같이
슬라이드의 코드와 같이 idx와 w를 이런 식으로 복사하기 때문에 마음껏 바꾸고 되돌리지 않아도 됩니다.
 이후 지우는 상대와 대결을 합니다. 지우가 승리했을 때, 상대가 승리했을 때를 잘 나눠서 처리해야 합니다.
이후 지우는 상대와 대결을 합니다. 지우가 승리했을 때, 상대가 승리했을 때를 잘 나눠서 처리해야 합니다.

 다시 지우의 턴이 왔으니 한 단계를 더 따라가도록 처리를 해주면 재귀함수의 구현이 끝납니다. 코드를 참고하세요.
다시 지우의 턴이 왔으니 한 단계를 더 따라가도록 처리를 해주면 재귀함수의 구현이 끝납니다. 코드를 참고하세요.
 백트래킹으로도 이렇게 구현을 할 수는 있지만 그다지 추천하지 않습니다. 이번에는 전수조사로 구현을 해봅시다. 구현을 가장 깔끔하게 할 수 있는 방법은 경희와 민호가 정해진 손동작의 순서가 있듯 지우 또한 손동작의 순서를 고정해 놓는 것입니다. 그러면 지우과 경희/민호를 따로 구분해서 코딩할 필요가 없어집니다.
백트래킹으로도 이렇게 구현을 할 수는 있지만 그다지 추천하지 않습니다. 이번에는 전수조사로 구현을 해봅시다. 구현을 가장 깔끔하게 할 수 있는 방법은 경희와 민호가 정해진 손동작의 순서가 있듯 지우 또한 손동작의 순서를 고정해 놓는 것입니다. 그러면 지우과 경희/민호를 따로 구분해서 코딩할 필요가 없어집니다.
이제 지우의 $N!$ 가지의 손동작의 순서에 대해 지우가 우승하는 경우가 1개라도 존재하는지를 확인하면 됩니다. 코드
 이번에는 2일차의 계란으로 계란치기 문제의 풀이를 해봅시다. 이 문제 또한 앞의 문제처럼 백트래킹으로 풀어도 되고 전수조사로 풀어도 됩니다. 그런데 백트래킹으로 해결을 하면 코드도 깔끔하고 속도도 빠릅니다.
이번에는 2일차의 계란으로 계란치기 문제의 풀이를 해봅시다. 이 문제 또한 앞의 문제처럼 백트래킹으로 풀어도 되고 전수조사로 풀어도 됩니다. 그런데 백트래킹으로 해결을 하면 코드도 깔끔하고 속도도 빠릅니다.
 먼저 전수조사로 구현해봅시다. 전수조사를 하기 위해 미리 각 계란에 대해서 어떤 계란을 칠지 미리 정해둡니다. 서술의 편의를 위해 이를 스케쥴이라고 부르겠습니다. 각 계란이 칠 수 있는 계란은 $N-1$개이기 때문에 가능한 스케쥴의 가지수는 $(N-1)^N$개이고 이 값은 $N=8$일 때 5,764,801 이기 때문에 시간 내에 모든 경우를 해볼 수 있습니다.
먼저 전수조사로 구현해봅시다. 전수조사를 하기 위해 미리 각 계란에 대해서 어떤 계란을 칠지 미리 정해둡니다. 서술의 편의를 위해 이를 스케쥴이라고 부르겠습니다. 각 계란이 칠 수 있는 계란은 $N-1$개이기 때문에 가능한 스케쥴의 가지수는 $(N-1)^N$개이고 이 값은 $N=8$일 때 5,764,801 이기 때문에 시간 내에 모든 경우를 해볼 수 있습니다.
단 원래 치기로 정해둔 계란이 깨져있을 경우의 처리에 굉장히 주의해야 합니다. 깨져있는 것을 고려하지 않고 그대로 내려쳐도 오답이고, 정해둔 계란이 깨져있을 경우 치지 않고 넘어가도 문제의 조건과 달리 들고있는 계란을 스킵하는 것이 되기 때문에 오답입니다.
 그렇다고 해서 중간에 치기로 정해둔 계란이 깨져있는 경우, 그 스케쥴을 잘못되었다고 판단하고 아예 건너뛰어도 안됩니다. 예를 들어 모든 계란이 내구도가 1, 무게가 100일 경우 모든 스케쥴이 잘못되었다고 판단해버려 답을 구할 수 없기 때문입니다. 그렇기 때문에 중간에 치기로 정해둔 계란이 깨져있을 때에는 경우를 나눠서 생각해야 합니다. $N-1$개의 계란이 깨져 깨지지 않은 다른 계란이 없을 때에는 현재 손에 든 계란으로 다른 계란을 치지 않은 채 건너뛰고 해당 스케쥴을 계속 진행하면 되고, 깨지지 않은 다른 계란이 있으면 그 스케쥴이 잘못되었으므로 아예 그 스케쥴을 건너뛰면 됩니다. 코드를 참고하세요.
그렇다고 해서 중간에 치기로 정해둔 계란이 깨져있는 경우, 그 스케쥴을 잘못되었다고 판단하고 아예 건너뛰어도 안됩니다. 예를 들어 모든 계란이 내구도가 1, 무게가 100일 경우 모든 스케쥴이 잘못되었다고 판단해버려 답을 구할 수 없기 때문입니다. 그렇기 때문에 중간에 치기로 정해둔 계란이 깨져있을 때에는 경우를 나눠서 생각해야 합니다. $N-1$개의 계란이 깨져 깨지지 않은 다른 계란이 없을 때에는 현재 손에 든 계란으로 다른 계란을 치지 않은 채 건너뛰고 해당 스케쥴을 계속 진행하면 되고, 깨지지 않은 다른 계란이 있으면 그 스케쥴이 잘못되었으므로 아예 그 스케쥴을 건너뛰면 됩니다. 코드를 참고하세요.
 인싸들의 가위바위보 문제와 다르게 이 문제에서는 백트래킹으로 구현을 하는 것이 전수조사보다 오히려 쉽습니다.
인싸들의 가위바위보 문제와 다르게 이 문제에서는 백트래킹으로 구현을 하는 것이 전수조사보다 오히려 쉽습니다.
solve(a) 함수는 $a$번째 계란을 손에 든 상황을 의미합니다. 깨지지 않은 다른 계란이 있다면 그 계란들 각각에 대해 적절하게 내구도를 변경한 후 재귀적으로 solve(a+1)으로 따라 들어가면 되고, 그렇지 않다면 바로 $solve(a+1)$으로 가면 됩니다.
참고로 전역 변수로 깨져있는 계란의 수를 가지고 가면 구현할 때 편합니다. 코드
 마지막 Baaaaaaaaaduk2 문제입니다. Easy는 그다지 어렵지않게 해결이 가능합니다. 빈칸이 $K$개일 때 현재 판 위에서 2개의 돌을 두는 경우의 수는 $K(K-1)/2$개입니다. 그렇기 때문에 빈칸이 $NM$개에 가까울 때 총 경우의 수는 대략 $N^2M^2$입니다.
마지막 Baaaaaaaaaduk2 문제입니다. Easy는 그다지 어렵지않게 해결이 가능합니다. 빈칸이 $K$개일 때 현재 판 위에서 2개의 돌을 두는 경우의 수는 $K(K-1)/2$개입니다. 그렇기 때문에 빈칸이 $NM$개에 가까울 때 총 경우의 수는 대략 $N^2M^2$입니다.
일단 돌을 둔 이후 죽은 상대 돌의 갯수를 파악하는 것은 BFS로 $O(NM)$에 할 수 있습니다. 이 부분은 다리 건너기 문제에서 섬을 파악한 것과 비슷한 방식으로 하면 됩니다.
이렇게 모든 가능한 돌을 두는 경우를 다 해보는 방법은 $O(N^3M^3)$이기에 $N$, $M$이 최대 20인 Easy에서 통과됩니다. 정답 코드를 확인해보세요. 그러나 $O(N^3M^3)$은 Hard를 해결하기에 턱없이 부족한 시간복잡도입니다. Hard 문제를 해결하기 위해서는 관찰을 통해 몇 가지 성질을 알아내야 합니다. 만약 스포일러를 원치 않는다면 Hard의 풀이를 넘어가고 109번 슬라이드로 가면 됩니다.
 첫 번째로는 상대의 그룹들 중 인접한 빈 칸이 3개 이상인 그룹은 죽일 수 없다는 성질입니다. 반대로 말하면 상대의 그룹들 중에서 인접한 빈 칸이 2개 이하인 그룹만 고려하면 된다는 의미입니다.
첫 번째로는 상대의 그룹들 중 인접한 빈 칸이 3개 이상인 그룹은 죽일 수 없다는 성질입니다. 반대로 말하면 상대의 그룹들 중에서 인접한 빈 칸이 2개 이하인 그룹만 고려하면 된다는 의미입니다.
 두 번째로 각 빈 칸에 대해, 그 빈 칸에만 착수했을 때 죽일 수 있는 상대의 돌이 몇 개인지 알 수 있습니다. 상대의 그룹을 파악하기 위해 Flood Fill을 할 때, 해당 그룹에 인접한 빈 칸이 1개일 경우에는 그 빈 칸에 그 그룹의 크기를 더해두면 됩니다. 구체적으로 어떻게 하는 것인지 과정을 따라가봅시다.
두 번째로 각 빈 칸에 대해, 그 빈 칸에만 착수했을 때 죽일 수 있는 상대의 돌이 몇 개인지 알 수 있습니다. 상대의 그룹을 파악하기 위해 Flood Fill을 할 때, 해당 그룹에 인접한 빈 칸이 1개일 경우에는 그 빈 칸에 그 그룹의 크기를 더해두면 됩니다. 구체적으로 어떻게 하는 것인지 과정을 따라가봅시다.
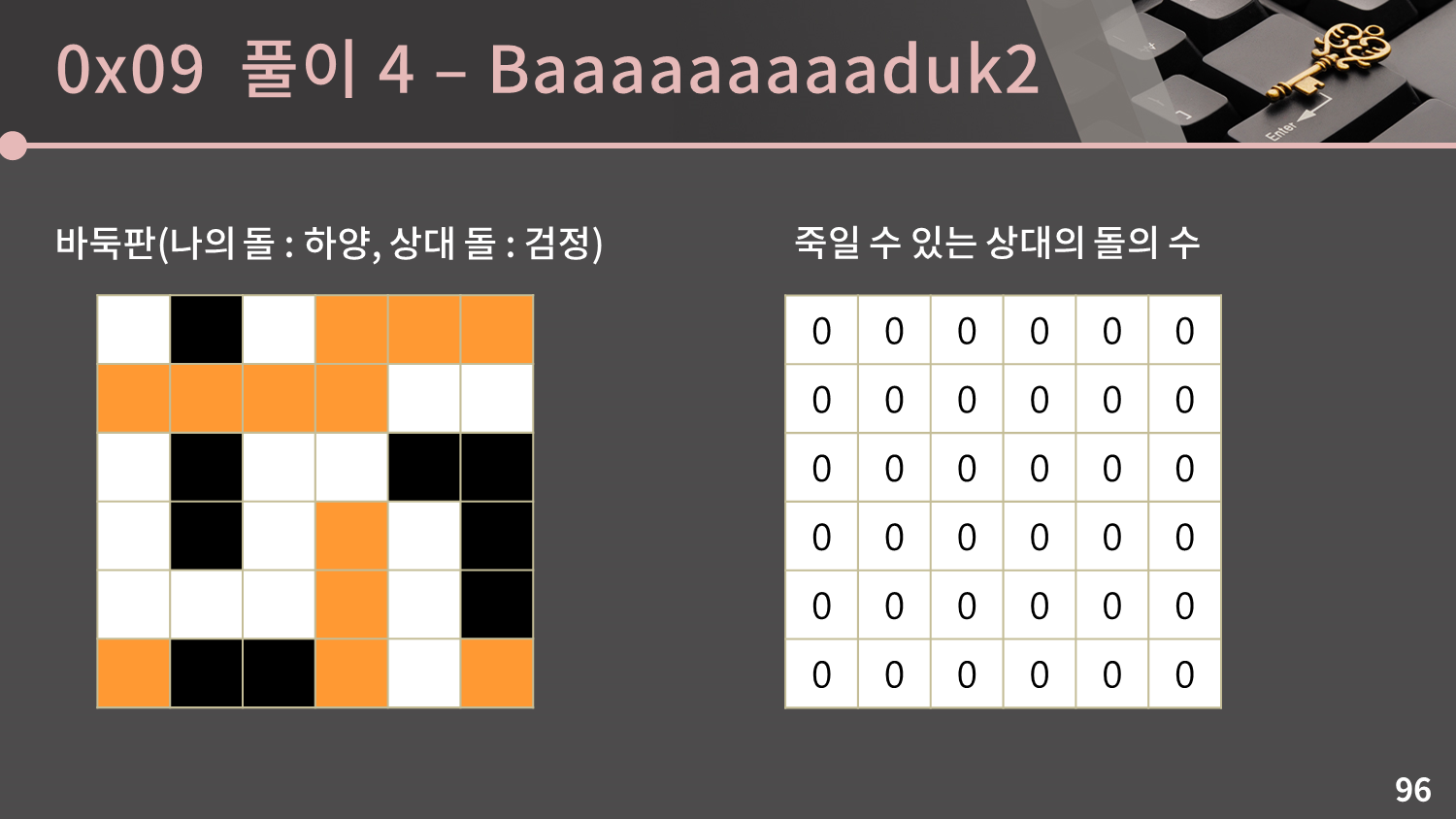 나는 하얀 돌이고 상대는 검은 돌입니다. 바둑판이 왼쪽과 같이 생겨있을 때 전체적으로 Flood Fill을 돌면서 특정 칸에 착수했을 때 죽일 수 있는 상대의 돌의 수를 구해봅시다.
나는 하얀 돌이고 상대는 검은 돌입니다. 바둑판이 왼쪽과 같이 생겨있을 때 전체적으로 Flood Fill을 돌면서 특정 칸에 착수했을 때 죽일 수 있는 상대의 돌의 수를 구해봅시다.
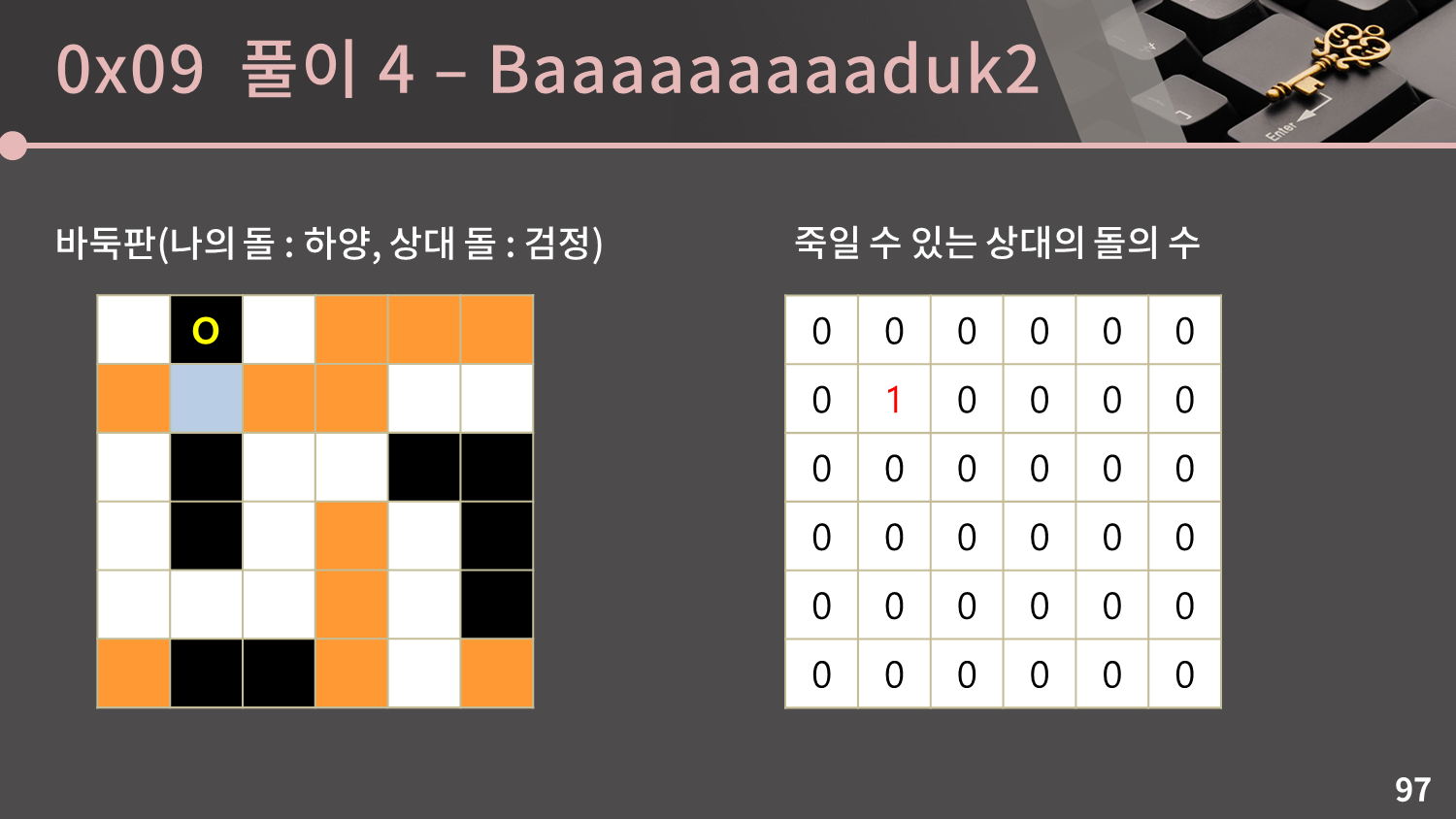 첫 번째 그룹을 보면 인접한 빈 칸이 1개이므로 그 빈 칸에 착수를 해 첫 번째 그룹을 죽일 수 있습니다.
첫 번째 그룹을 보면 인접한 빈 칸이 1개이므로 그 빈 칸에 착수를 해 첫 번째 그룹을 죽일 수 있습니다. (1,1)에 그룹의 크기인 1을 더합니다.
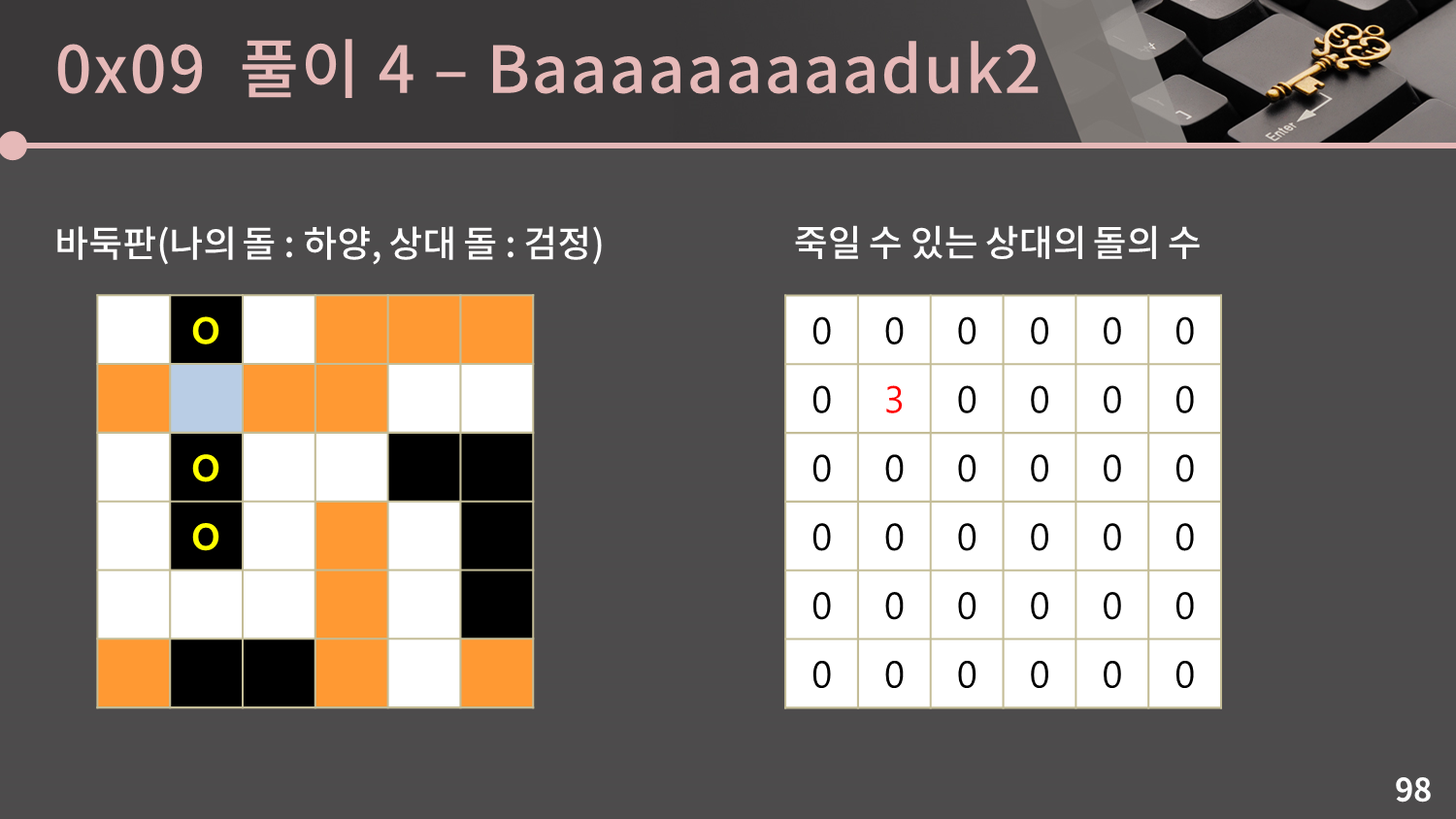 두 번째 그룹도 마찬가지로 인접한 빈 칸이 1개이므로 그 빈 칸에 착수를 해 두 번째 그룹을 죽일 수 있습니다.
두 번째 그룹도 마찬가지로 인접한 빈 칸이 1개이므로 그 빈 칸에 착수를 해 두 번째 그룹을 죽일 수 있습니다. (1,1)에 그룹의 크기인 2을 더합니다.
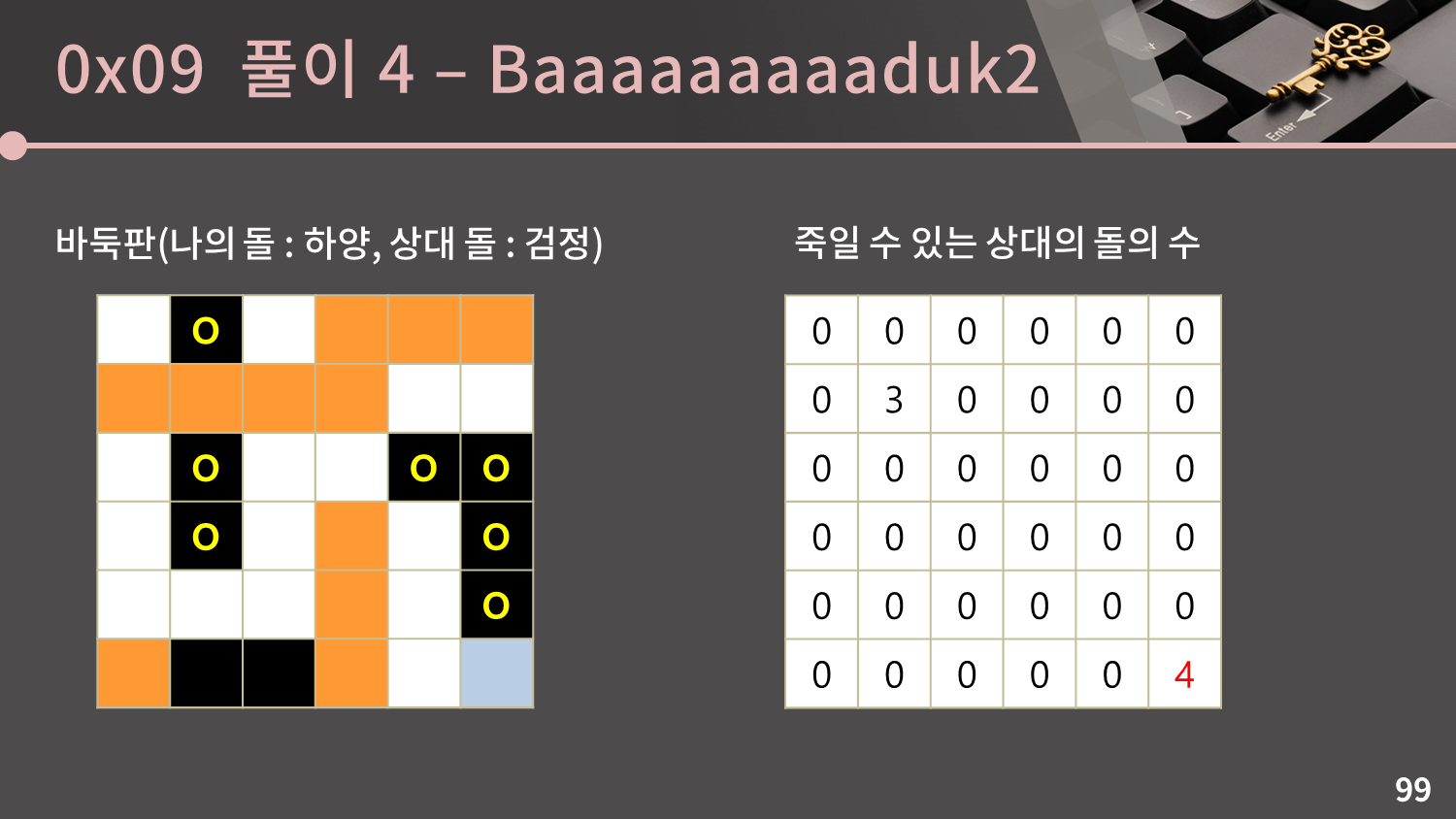 세 번째 그룹도 인접한 빈 칸이 1개이므로 그 빈 칸에 착수를 해 세 번째 그룹을 죽일 수 있습니다.
세 번째 그룹도 인접한 빈 칸이 1개이므로 그 빈 칸에 착수를 해 세 번째 그룹을 죽일 수 있습니다. (5,5)에 그룹의 크기인 4을 더합니다.
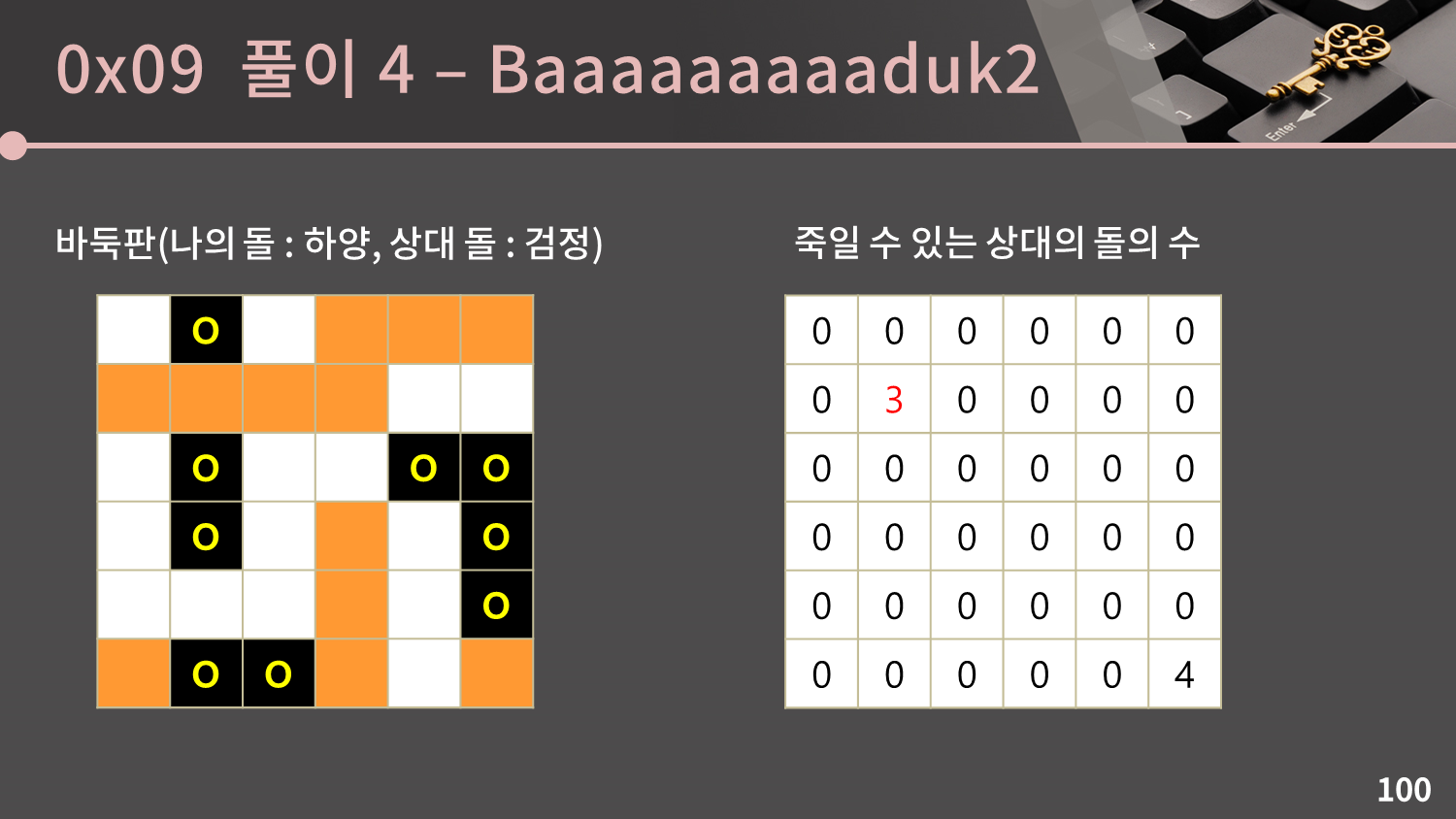 네 번째 그룹은 인접한 빈 칸이 2개이므로 특정 빈 칸 하나에 착수를 해도 네 번째 그룹을 죽일 수 없으므로 넘어갑니다.
네 번째 그룹은 인접한 빈 칸이 2개이므로 특정 빈 칸 하나에 착수를 해도 네 번째 그룹을 죽일 수 없으므로 넘어갑니다.
 세 번째 성질입니다. 인접한 빈 칸이 1개인 상대의 그룹만 잡고 싶으면 앞에서 구한 각 칸의 죽일 수 있는 상대의 돌의 수 중 최댓값 2개를 더하면 됩니다.
세 번째 성질입니다. 인접한 빈 칸이 1개인 상대의 그룹만 잡고 싶으면 앞에서 구한 각 칸의 죽일 수 있는 상대의 돌의 수 중 최댓값 2개를 더하면 됩니다.
 네 번째 성질은 인접한 빈 칸이 2개인 상대의 그룹을 잡으려면, BFS 과정에서 미리 후보군들을 정해놓을 수 있다는 것입니다. 마찬가지로 예시를 같이 봅시다.
네 번째 성질은 인접한 빈 칸이 2개인 상대의 그룹을 잡으려면, BFS 과정에서 미리 후보군들을 정해놓을 수 있다는 것입니다. 마찬가지로 예시를 같이 봅시다.
 첫 번째 그룹은 인접한 빈 칸이 2개이므로 후보군에 그 두 빈 칸
첫 번째 그룹은 인접한 빈 칸이 2개이므로 후보군에 그 두 빈 칸 (1,1), (1,2)를 기록해둡니다.
 두 번째 그룹은 인접한 빈 칸이 1개이므로 넘어갑니다.
두 번째 그룹은 인접한 빈 칸이 1개이므로 넘어갑니다.
 세 번째 그룹은 인접한 빈 칸이 2개이므로 후보군에 그 두 빈 칸
세 번째 그룹은 인접한 빈 칸이 2개이므로 후보군에 그 두 빈 칸 (5,0), (5,3)를 기록해둡니다.
 네 번째 그룹은 인접한 빈 칸이 1개이므로 넘어갑니다.
네 번째 그룹은 인접한 빈 칸이 1개이므로 넘어갑니다.
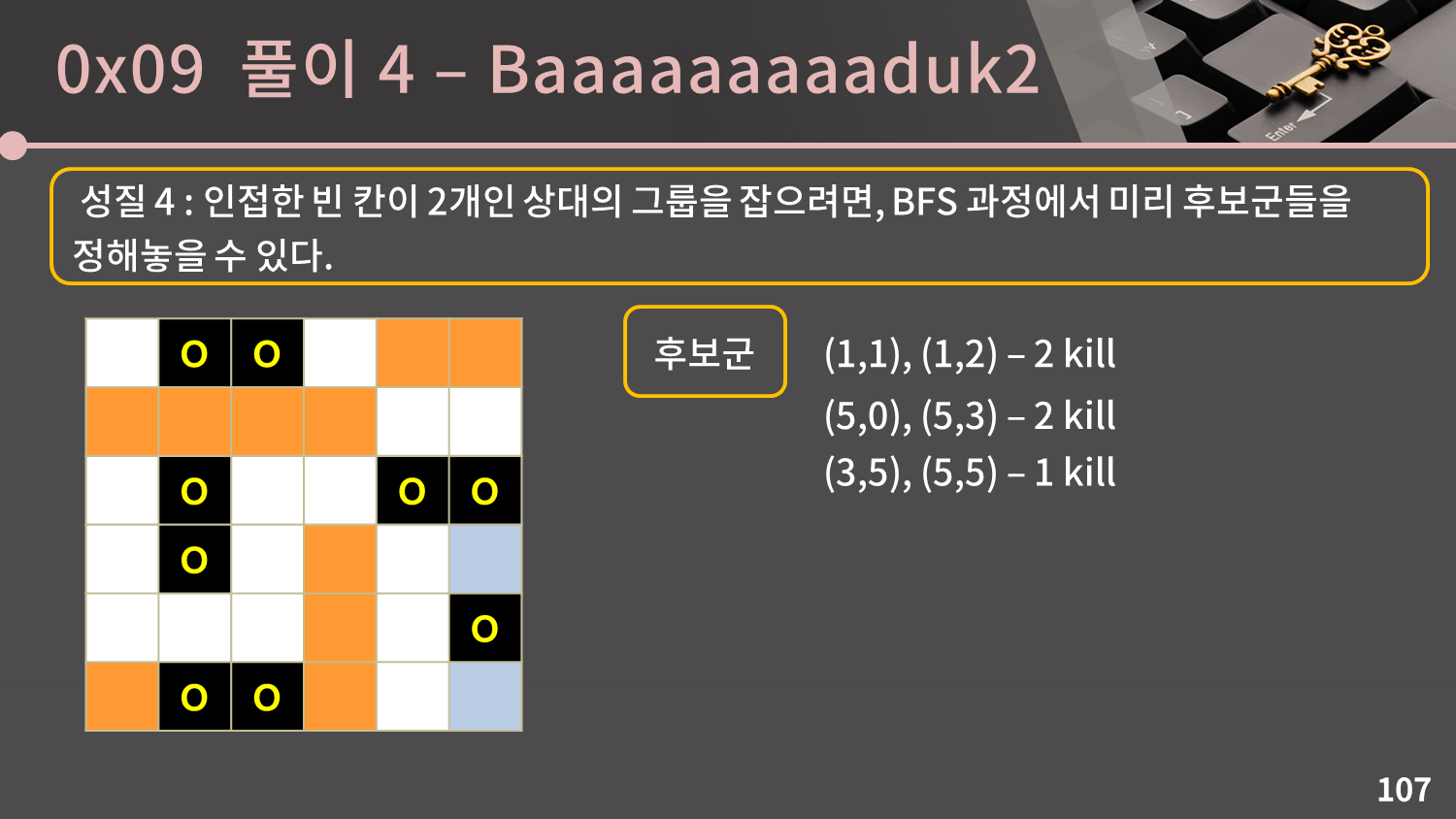 마지막 그룹은 인접한 빈 칸이 2개이므로 후보군에 그 두 빈 칸
마지막 그룹은 인접한 빈 칸이 2개이므로 후보군에 그 두 빈 칸 (3,5), (5,5)를 기록해둡니다.
 마지막 성질입니다. 각 빈 칸에 대해, 그 빈 칸에 인접한 상대의 그룹은 최대 4개입니다. 이 성질을 사용하지않고 그냥 후보군을 정렬하거나 map을 이용해 동일한 후보군인 경우를 처리하는 $O((lgN+lgM)NM)$ 풀이도 통과되지만, 성질 5를 사용하면 각 후보군에서 2개의 착수에 대해 상하좌우로 인접한 상대방의 그룹을 살펴보며 처리를 해줌으로서 $O(NM)$에 풀이가 가능합니다.
마지막 성질입니다. 각 빈 칸에 대해, 그 빈 칸에 인접한 상대의 그룹은 최대 4개입니다. 이 성질을 사용하지않고 그냥 후보군을 정렬하거나 map을 이용해 동일한 후보군인 경우를 처리하는 $O((lgN+lgM)NM)$ 풀이도 통과되지만, 성질 5를 사용하면 각 후보군에서 2개의 착수에 대해 상하좌우로 인접한 상대방의 그룹을 살펴보며 처리를 해줌으로서 $O(NM)$에 풀이가 가능합니다.
 드디어 풀이가 끝났습니다! Baaaaaaaaaduk2 Hard의 경우 애초에 코딩테스트를 뛰어넘는 수준이라 이해하지 않으셔도 괜찮습니다. 그러나 나머지 네 문제 중에서 접근 방법조차 떠올리지 못한 문제가 존재한다면 BFS/DFS, 백트래킹의 기본개념에 대한 공부가 선행되어야 합니다. 네 문제 모두 구현이 조금 까다롭긴 하지만 발상이 어려운 문제는 아니었습니다.
드디어 풀이가 끝났습니다! Baaaaaaaaaduk2 Hard의 경우 애초에 코딩테스트를 뛰어넘는 수준이라 이해하지 않으셔도 괜찮습니다. 그러나 나머지 네 문제 중에서 접근 방법조차 떠올리지 못한 문제가 존재한다면 BFS/DFS, 백트래킹의 기본개념에 대한 공부가 선행되어야 합니다. 네 문제 모두 구현이 조금 까다롭긴 하지만 발상이 어려운 문제는 아니었습니다.
만약 방법은 알겠는데 코드가 너무 더러워졌다거나, 분명 맞는 것 같은데 제출했더니 틀렸다고 뜨는 경우에는 비슷한 유형의 문제를 계속 풀어보며 구현력을 기르셔야 합니다.
 알고리즘 문제를 잘 해결하기 위해서는 배경지식/문제해결능력/구현력이라는 3가지 능력을 모두 갖춰야 합니다. 배경지식은 여러 자료를 통해 공부하면서 늘릴 수 있지만, 문제해결능력과 구현력은 양질의 문제를 많이 풀어보면서 늘려야 합니다.
알고리즘 문제를 잘 해결하기 위해서는 배경지식/문제해결능력/구현력이라는 3가지 능력을 모두 갖춰야 합니다. 배경지식은 여러 자료를 통해 공부하면서 늘릴 수 있지만, 문제해결능력과 구현력은 양질의 문제를 많이 풀어보면서 늘려야 합니다.
 개인마다 자신에게 맞는 공부 방법은 모두 다르지만, 제가 생각하기에 초보 단계에서는 최대한 많은 문제를 풀어보는게 좋다고 생각합니다. 일단 구현력이 어느 정도는 갖춰져야 특정 문제에서 계속 틀린 채로 정체되지 않고 계속 나아갈 수 있으니까요.
그렇기에 한 20-30분 정도 고민하고 전혀 실마리가 잡히지 않거나, 오랫동안 구현을 해보려고 했는데 꼬여서 진척이 없으면 적극적으로 풀이를 참고해 구현력을 먼저 끌어올리시는걸 추천드립니다.
개인마다 자신에게 맞는 공부 방법은 모두 다르지만, 제가 생각하기에 초보 단계에서는 최대한 많은 문제를 풀어보는게 좋다고 생각합니다. 일단 구현력이 어느 정도는 갖춰져야 특정 문제에서 계속 틀린 채로 정체되지 않고 계속 나아갈 수 있으니까요.
그렇기에 한 20-30분 정도 고민하고 전혀 실마리가 잡히지 않거나, 오랫동안 구현을 해보려고 했는데 꼬여서 진척이 없으면 적극적으로 풀이를 참고해 구현력을 먼저 끌어올리시는걸 추천드립니다.
 그리고 삼성 역량테스트만을 놓고 보면 DP가 잘 안나오지만 다른 곳에서는 정말 자주 나오니 DP도 꼭 공부하세요. 또 언어에 관해 알려드리고 싶은 것이 있습니다. 파이썬은 속도가 많이 느립니다. 그렇기에 동일한 시간복잡도의 풀이임에도 불구하고 C나 JAVA로는 통과되는데 파이썬으로는 통과되지 않는 경우가 종종 있습니다. 물론 코딩테스트 언어에 파이썬이 포함되어 있으면 테스트 내에서 파이썬으로도 정답을 받을 수 있게끔 제한을 적당히 잘 설정해두었을 것이라고 추론할 수는 있습니다만, 관련 자료도 C언어가 압도적으로 많고 또 C언어 정도는 익숙해서 나쁠게 없으므로 당장 코딩테스트가 촉박하면 어쩔 수 없지만 아직 시간이 많다면 최대한 빨리 C언어로 갈아타는 것을 추천드립니다.
그리고 삼성 역량테스트만을 놓고 보면 DP가 잘 안나오지만 다른 곳에서는 정말 자주 나오니 DP도 꼭 공부하세요. 또 언어에 관해 알려드리고 싶은 것이 있습니다. 파이썬은 속도가 많이 느립니다. 그렇기에 동일한 시간복잡도의 풀이임에도 불구하고 C나 JAVA로는 통과되는데 파이썬으로는 통과되지 않는 경우가 종종 있습니다. 물론 코딩테스트 언어에 파이썬이 포함되어 있으면 테스트 내에서 파이썬으로도 정답을 받을 수 있게끔 제한을 적당히 잘 설정해두었을 것이라고 추론할 수는 있습니다만, 관련 자료도 C언어가 압도적으로 많고 또 C언어 정도는 익숙해서 나쁠게 없으므로 당장 코딩테스트가 촉박하면 어쩔 수 없지만 아직 시간이 많다면 최대한 빨리 C언어로 갈아타는 것을 추천드립니다.
 어느 정도 유형이 정해져있는 A형과 달리 B/C형은 Divide&Conquer, 빡구현, Hash, Linked List, Heap, 참신한 아이디어 등의 정말 다양한 유형의 문제들이 나와 한 유형만 팠는데 운이 좋아 그 유형의 문제가 출제된게 아니면 단기간에 따는게 불가능에 가깝습니다. 또 그렇기에 B/C형을 콕 찝어서 대비할 수 있는 방법도 없습니다. 그러니 swexpertacademy에 있는 B형 연습문제를 한 번 보시고, 올림피아드 기출과 같은 양질의 문제를 많이 풀어보며 문제해결능력을 기르셔야 합니다. B/C형을 취득할 정도면 다른 어느 코딩테스트에서도 어려움이 없을 것입니다.
어느 정도 유형이 정해져있는 A형과 달리 B/C형은 Divide&Conquer, 빡구현, Hash, Linked List, Heap, 참신한 아이디어 등의 정말 다양한 유형의 문제들이 나와 한 유형만 팠는데 운이 좋아 그 유형의 문제가 출제된게 아니면 단기간에 따는게 불가능에 가깝습니다. 또 그렇기에 B/C형을 콕 찝어서 대비할 수 있는 방법도 없습니다. 그러니 swexpertacademy에 있는 B형 연습문제를 한 번 보시고, 올림피아드 기출과 같은 양질의 문제를 많이 풀어보며 문제해결능력을 기르셔야 합니다. B/C형을 취득할 정도면 다른 어느 코딩테스트에서도 어려움이 없을 것입니다.
 고생 많으셨습니다! 특강에 못오셨다고 하더라도 이 글을 보면서 공부를 하실 수 있게끔 포스트를 상세하게 작성해두었으니 문제들 꼭 많이 풀어보시면서 익혀보세요. 당장은 실력이 늘지 않는 것 같아 답답할 수 있지만 꾸준함을 이길 수 있는 것은 없으니 포기하지말고 계속 화이팅입니다 ^__^
고생 많으셨습니다! 특강에 못오셨다고 하더라도 이 글을 보면서 공부를 하실 수 있게끔 포스트를 상세하게 작성해두었으니 문제들 꼭 많이 풀어보시면서 익혀보세요. 당장은 실력이 늘지 않는 것 같아 답답할 수 있지만 꾸준함을 이길 수 있는 것은 없으니 포기하지말고 계속 화이팅입니다 ^__^